英伟达放出视觉 AI Agent 实战手册:合成数据+微调三连击

NVIDIA 在 Omniverse 系列博客中公开了三套视觉 AI Agent 的提精度工作流,覆盖合成数据生成、自动标注与模型微调,目标是把视觉智能体从 demo 推向工厂、园区、交通这些真实落地场景。
视觉 AI Agent 的精度瓶颈,英伟达想用合成数据撬开
6 月底,NVIDIA 在 Into the Omniverse 系列里更新了一篇相当硬核的实战指南——三套用来提升 Vision AI Agent 准确率的工作流。这不是发布会式的口号,而是一份给 CV 工程师看的施工图:从合成数据生成、自动标注,到 VLM 微调和评估闭环,全流程串起来。
背景其实不复杂。过去一年,视觉 AI Agent(也就是用 VLM 驱动、能理解视频流并自主推理的智能体)在制造、物流、交通领域被反复 PoC,但真正进入生产线的并不多。卡点几乎都是同一个:真实场景里那些罕见但要命的事件——传送带上的异常缺陷、监控里偶发的违规行为、仓库里的近距离碰撞——训练数据根本不够。一个视觉智能体在演示视频里能把场景讲得天花乱坠,到了客户现场,碰上没见过的工件角度就开始胡说。
NVIDIA 这次给的解法,本质上是把 Omniverse + Cosmos + Metropolis 这一整套基础设施,封装成开发者能直接调用的「Agent Skills」,让 AI Agent 自己去补全数据闭环。
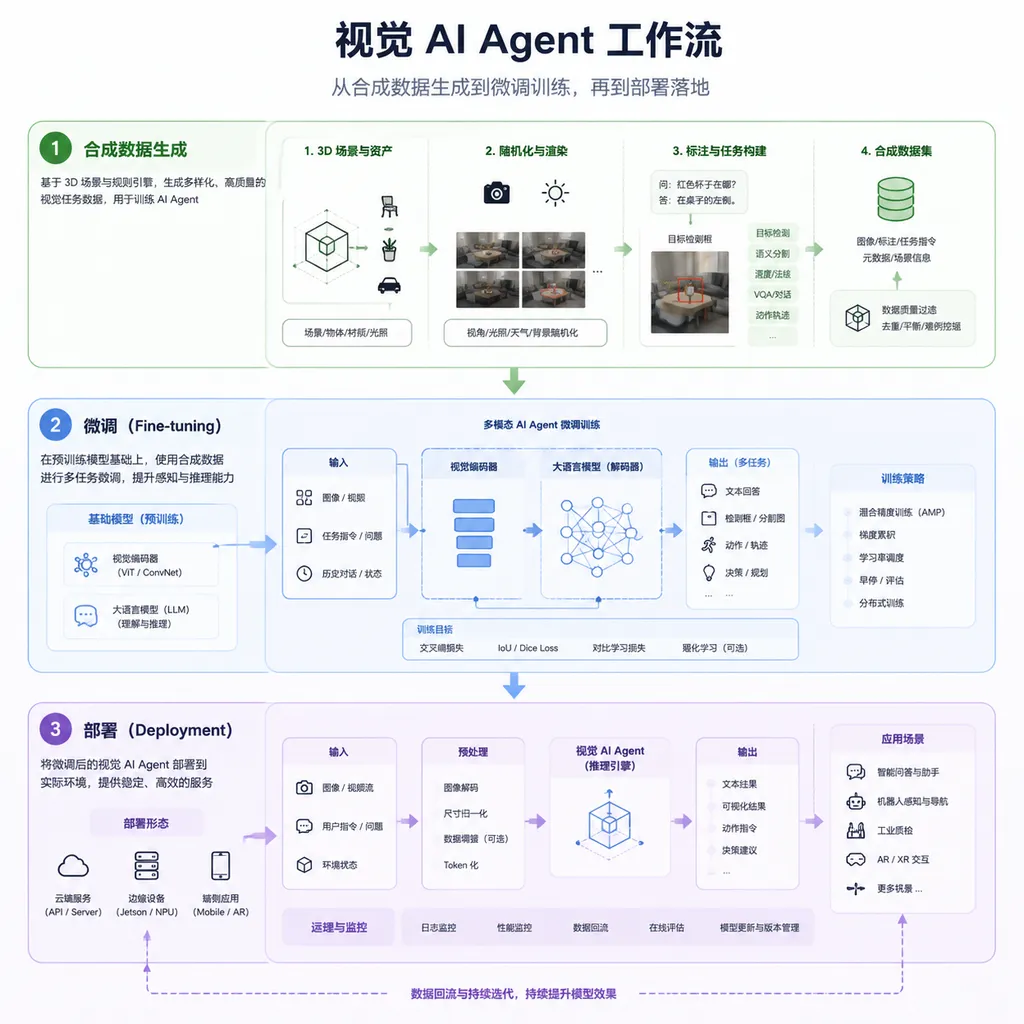
三套工作流,对应三类典型痛点
工作流一:用合成数据补齐长尾缺陷
第一套工作流瞄准的是视觉检测——也就是工业质检里那些「缺陷样本太少」的场景。
传统做法是攒数据:在产线上架相机,等几个月攒一批缺陷件,人工标注完再训。问题是某些高良率工艺,一周可能就出一两件缺陷品,VLM 这种数据饥渴的模型根本喂不饱。
NVIDIA 的方案是用 Isaac Sim + Cosmos 3 + OSMO 这条链路在虚拟环境里生成缺陷图像。具体来说:
- Isaac Sim 负责构建物理精确的 3D 场景,包括工件、光照、相机视角
- Cosmos 3(NVIDIA 6 月刚发的物理 AI 全模态世界模型)负责在真实图像基础上,往不同表面合成不同形态的缺陷——划痕、凹陷、污渍、裂纹
- OSMO 做编排,把视觉语言推理模块接进来,自动评估生成的缺陷是否「合理」
这里值得注意的是 Cosmos 3 的混合 Transformer 架构:一个推理 Transformer 先分析观测结果,把指令丢给生成模块,再去扩展虚拟世界。换句话说,它不是无脑生成缺陷贴图,而是会先「想」一下这种缺陷在物理上是否说得通——这是合成数据从「能用」到「能训练出泛化模型」的关键差别。
实际效果上,开发者可以用这条流水线在几小时内生成数千张涵盖罕见缺陷的图像,对比真实采集动辄数月的周期,落地节奏完全不是一个量级。
工作流二:视频搜索摘要(VSS)+ 自动标注
第二套针对的是视频 AI 智能体——也就是从大量监控、巡检、车队视频里提取洞察、生成摘要、触发告警的那类系统。
这类场景的痛点和第一套不太一样。视频数据本身不缺,缺的是带语义标注的视频。让人去看 1000 小时监控然后标注「这里有人闯入」「这里发生堆叠」,成本爆炸。
NVIDIA 给的工具组合是 Metropolis VSS Blueprint + TAO + 视频增强 Skills:
- VSS Blueprint 提供视频搜索和摘要的参考实现,底层是 NIM 微服务,VLM、LLM、图数据库都可以替换
- TAO 做模型微调,把通用 VLM 往特定场景(比如仓库安全、零售货架)上拉
- 视频增强 Skills 负责伪标注(pseudo-labeling)——也就是先用一个能力强的大模型给视频打粗标签,再用这些标签去训练小模型
这套流程最值得借鉴的点,是它把**「构建—评估—再训练」做成了循环**。Agent 自己拉数据、自己微调、自己跑评估集,工程师只需要在关键节点介入。对于做视频智能分析的团队,这种自动化的 build-eval loop 几乎是把过去一个算法团队几个月的工作压缩成了几天。
工作流三:场景重建驱动的数据增强
第三套偏向辅助驾驶和机器人,但思路对所有视觉 AI 都有借鉴意义。
核心是「神经重建」——把车队(或巡检机器人、无人机)实际采集到的视频,转换成可编辑的 3D 场景。一旦场景变成 3D 资产,你就可以:
- 改变天气、光照、时间
- 加入虚拟的行人、车辆、障碍物
- 调整相机位置生成新视角
- 在罕见极端工况下做压力测试
背后的技术栈包括 Omniverse NuRec、InstantNuRec、Harmonizer 和 HiGS 加速渲染器。Harmonizer 这个组件值得单独提一下,它负责把合成进去的虚拟物体和原始场景的光照、阴影做协调,避免出现那种「一眼假」的合成图——这是合成数据训练能不能 work 的核心因素之一。
开发者真正能用上的部分
抛开 NVIDIA 一贯的「全栈」叙事,开发者实际能拿到的东西梳理一下:
| 组件 | 用途 | 获取方式 | |------|------|---------| | Cosmos 3 | 物理 AI 世界基础模型 | Hugging Face 开放下载 | | Isaac Sim 6.0 | 仿真平台,内置 Agent 连接器 | 免费 | | Metropolis VSS Blueprint | 视频搜索摘要参考实现 | NIM 微服务 | | TAO | 模型微调工具链 | 免费 | | 物理 AI 数据集 | 训练/微调/评估 | Hugging Face,累计下载超 1500 万次 |
NVIDIA 这次也同步放出了几个新数据集,包括 GRAIL(约 50 小时人形机器人交互数据)和六个用于训练 Cosmos 3 的合成视频数据集,覆盖机器人、物理、数字人、辅助驾驶、仓库安全、空间推理六个方向。对做物理 AI 研究的团队来说,这批数据的价值比工具本身可能还要高。
几个值得冷静看待的点
这套工作流的方向是对的,但实际落地有几个坑得提前知道。
第一,硬件门槛不低。Isaac Sim、Cosmos 3、NuRec 这些组件跑起来对 GPU 显存和算力的要求都不小。NVIDIA 推荐的是 RTX PRO 服务器或者 DGX 系列,中小团队想本地跑全流程基本不现实,云端方案是更实际的选择。
第二,合成数据不是银弹。Sim-to-Real Gap 是物理 AI 老生常谈的问题——你在仿真里训得再好,到了真实场景多少会掉点。Cosmos 3 的物理推理能力确实拉高了合成数据的上限,但工业级部署还是要走「合成数据预训练 + 少量真实数据微调」的两段式路线,没法跳过真实数据采集。
第三,工具链整合是个工作量。VSS Blueprint、TAO、Isaac Sim 之间的连接器在 6.0 版本里有改善,但实际工程中你大概率还是要自己写一些胶水代码,把数据格式、调度、监控串起来。NVIDIA 给的是参考实现,不是开箱即用的产品。
这件事的更大背景
往回看,NVIDIA 过去一年其实在干一件统一的事情:把物理 AI 的开发模式,从「找数据—标数据—训模型」改造成「定义场景—生成数据—自动训练—闭环评估」。Cosmos 是世界模型,Omniverse 是 3D 基建,Isaac 是机器人栈,Metropolis 是视觉智能体栈,DRIVE 是辅助驾驶栈——这些此前分散的产品,现在通过「Agent Skills」这一层被串了起来。
对开发者来说,这意味着两件事:一是物理 AI 的入门门槛在快速降低,半年前还需要专门算法团队才能搞的事,现在一个熟悉 Python 和 PyTorch 的工程师配上这套工具就能起步;二是视觉智能体的竞争焦点正在从「模型选型」转移到「数据闭环」——能不能持续生成高质量、覆盖长尾的训练数据,比挑哪个 VLM 更决定最终系统的精度。
顺带一提,这套工作流里用到的 VLM 是可替换的,开发者完全可以接自家的视觉语言模型进去做推理。如果你想快速对比不同模型(Claude 的视觉能力、Gemini 2.5 的多模态、GPT 系列的 OCR)在你场景下的表现,用 OpenAI Hub 这类聚合平台一个 Key 切换不同模型做评估,比挨个去申请 API 要省事得多——尤其是在 VSS 这种需要批量跑评估集的场景下。
视觉 AI Agent 这个方向,2024 年大家还在做 demo,到 2026 年中已经开始拼工程化能力了。NVIDIA 这次给的不是新模型,而是一套让视觉智能体「能持续变好」的方法论——这对真正想把视觉 AI 装进生产环境的团队,意义比再发一个 SOTA 模型要大。
参考来源
- NVIDIA 物理 AI 数据集 - Hugging Face:累计下载量超 1500 万次的官方数据集合集,包含 Cosmos 3 训练数据和 Isaac GR00T 数据