ScarfBench发布:首个企业Java框架迁移AI基准

IBM研究院联合学术界推出ScarfBench,专为评估AI Agent在企业级Java框架迁移任务中的能力而设计,填补了行为保持型跨框架重构基准的空白,为AI辅助遗留系统现代化提供标尺。
ScarfBench发布:首个面向企业Java框架迁移的AI Agent基准测试
2026年6月底,IBM研究院(IBM Research)正式发布并开源了ScarfBench——业界首个专门针对企业级Java应用跨框架迁移场景的AI Agent基准测试。这一基准的推出,填补了当前AI代码迁移评估领域中"行为保持型跨框架重构"(behavior-preserving cross-framework refactoring)这一关键空白,为衡量大语言模型与编码Agent在真实企业遗留系统现代化任务中的能力,提供了一把可量化、可复现的标尺。
该基准已通过 Hugging Face 平台同步发布技术博客、数据集与配套评测脚本,并在 arXiv 上公开了完整论文。配合近年来 AWS AI Labs 的 MigrationBench(聚焦 Java 版本升级)等工作,ScarfBench 标志着AI代码迁移评估进入了"跨框架、跨范式"的新阶段。
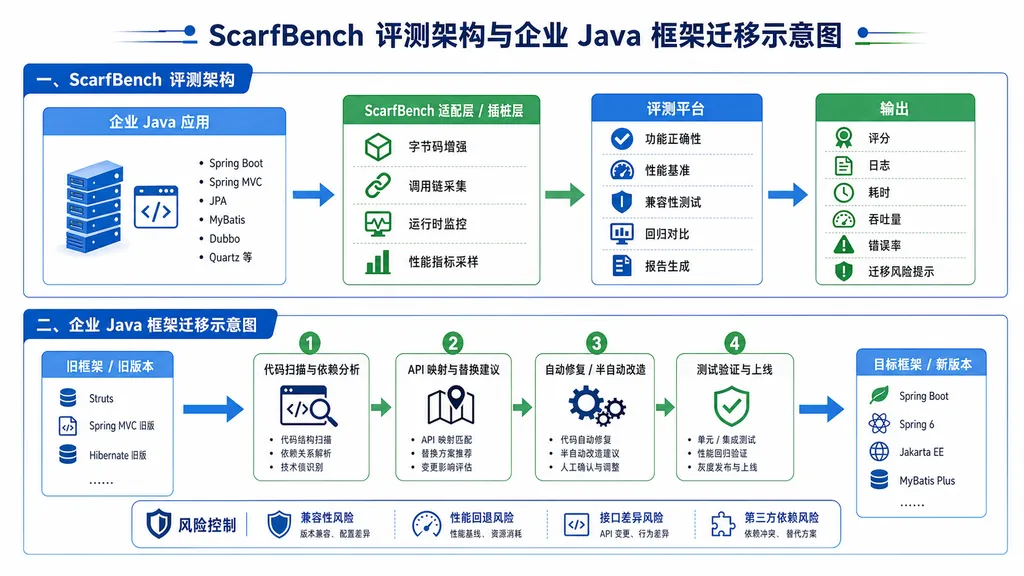
一、为什么需要 ScarfBench?
过去两年,AI Coding Agent 在 SWE-Bench、HumanEval、LiveCodeBench 等基准上的成绩节节攀升,部分前沿模型甚至在某些子集上已经逼近资深工程师水平。然而,在企业真实生产环境中,开发者面临的最大痛点之一并不是"写一段算法题",而是遗留系统的现代化改造——尤其是 Java 生态中盘根错节的框架迁移问题。
典型场景包括:
- 从 Spring Boot 2.x 升级到 Spring Boot 3.x(伴随 Jakarta EE 命名空间从
javax.*到jakarta.*的全局变更); - 从 Struts / Apache Wicket 等老旧 Web 框架迁移到 Spring MVC 或 Quarkus;
- 从 Java EE (JBoss / WebLogic) 应用栈迁移到 Micronaut 或 Quarkus 等云原生轻量级框架;
- ORM 层从 Hibernate 旧版本 切换到 JPA 标准实现 或 jOOQ;
- 测试栈从 JUnit 4 升级到 JUnit 5,伴随 Mockito、AssertJ 等的版本耦合迁移。
这些任务的共同特征是:代码改动量大、跨文件依赖复杂、必须严格保持运行时行为一致。传统的代码补全类基准完全无法刻画这种"系统级重构"的难度,而 AWS AI Labs 此前发布的 MigrationBench 虽然提供了 5,102 个 Java 8→17/21 的版本升级项目,但其本质仍是同框架内的语言级演进,并未触及"框架范式切换"这一更高阶难题。
IBM 研究团队在论文中明确指出,ScarfBench 的目标正是填补这一空白——把 AI Agent 放到"重写半个应用"的真实压力下检验。
二、ScarfBench 的核心设计
1. 数据集构成
ScarfBench 从开源生态中精选了一批真实、完整、可编译、可测试的企业级 Java 项目,覆盖多种典型迁移路径。每个样本都包含:
- 源框架版本的完整代码仓库(含 Maven/Gradle 构建脚本);
- 目标框架版本的参考实现(作为 ground truth);
- 原始测试套件(用于行为保持性验证);
- 迁移规约文档(描述需要保持哪些可观察行为);
- 构建与运行时环境镜像(Docker 化,确保评测可复现)。
这一设计与 SWE-Bench 的"基于 PR 评测"思路一脉相承,但更进一步——ScarfBench 强制要求 Agent 完成的不是单个补丁,而是"整套迁移工程"。
2. 任务类型分层
ScarfBench 将迁移任务划分为多个难度层级:
| 层级 | 典型任务 | 复杂度特征 |
|------|---------|-----------|
| L1 | API 重命名(如 javax→jakarta) | 机械化、可正则化 |
| L2 | 注解语义迁移(如 Spring @Autowired ↔ CDI @Inject) | 需要语义理解 |
| L3 | 配置范式切换(XML → Java Config → YAML) | 跨文件依赖 |
| L4 | 框架核心 API 重写(如 Struts Action → Spring Controller) | 架构级改造 |
| L5 | 多模块协同迁移(Web 层 + 持久层 + 测试层联动) | 全栈一致性 |
3. 评测指标:行为保持是核心
与许多只看"代码相似度"的基准不同,ScarfBench 把行为等价性作为头号指标。具体来说,评测维度包括:
- 编译通过率(Build Pass Rate):迁移后的项目能否成功构建;
- 测试通过率(Test Pass Rate):原始测试套件能否在新框架下全绿;
- 运行时行为一致性(Runtime Equivalence):通过对相同输入观察 HTTP 响应、DB 状态变更、日志事件等副作用,验证语义未漂移;
- 代码质量指标:圈复杂度、重复率、SpotBugs 静态检查等;
- 迁移完整度:是否仍有遗留的旧框架 API 调用。
4. Agent 评测协议
ScarfBench 为 Agent 提供了一套标准化的工作环境:
- 一个可读写的项目工作区;
- 完整的 shell 工具链(Maven、Gradle、JDK、Git);
- 文件系统访问能力;
- 可选的网络访问(用于查阅文档)。
Agent 需要在限定的 token 预算与时间预算内,自主完成探索→规划→改写→验证→修复的完整闭环。
三、与现有基准的差异化定位
ScarfBench 并非孤立出现,而是与近期几项重要工作形成了清晰的互补关系:
- MigrationBench(AWS AI Labs,2025):聚焦 Java 8→17/21 的版本升级,覆盖 5,102 个项目,但不涉及框架范式切换;
- SWE-Bench / SWE-Bench Verified:以单 PR 修复任务为核心,覆盖多语言,但单任务粒度较小;
- xbench(红杉中国,2025):双轨制评估,强调长青评估与垂类落地价值,定位在通用 Agent 能力跟踪;
- AgentBench(清华等,2023):早期系统性 Agent 基准,覆盖多场景但深度有限。
ScarfBench 的独特价值在于它把企业开发中最让 CTO 们头疼的"框架现代化"问题正式纳入了 AI 能力评估视野。IBM 研究院在博客中坦言,这是一类"传统基准无法刻画、却恰恰是企业最愿意为之付费"的任务。
四、首轮评测:当前 Agent 离"上岗"还有多远?
根据 IBM 研究院在 Hugging Face 博客中披露的初步评测结果(具体数字以官方 LeaderBoard 为准),主流前沿模型与编码 Agent 框架在 ScarfBench 上呈现出三段式断崖:
- 在 L1-L2 层级任务上,前沿模型已经能取得相当不错的通过率,机械化的命名空间替换、注解迁移大体可以自动化完成;
- 进入 L3 配置范式切换后,通过率出现显著回落,模型在面对跨文件、跨格式(XML/YAML/Java Config)的整体重构时容易顾此失彼;
- 到了 L4-L5 的架构级和全栈级迁移,绝大多数 Agent 仍然无法在不打破现有测试的前提下完成端到端任务,行为漂移、编译失败、循环改错是最常见的三类问题。
这一结果与企业开发者的直观感受高度一致——AI 已经能帮忙"砍掉重复劳动",但要真正接管一个 Spring Boot 2 到 3 的整库升级,仍需人类工程师把关。
五、对中国开发者意味着什么?
Java 在中国企业(金融、电信、政务、电商)依旧是绝对主力技术栈,Spring Boot 2→3 升级、Struts 退役、Dubbo 与 Spring Cloud 的版本拉齐等,都是悬在大量团队头上的实际工程任务。ScarfBench 的发布意味着:
- 可量化的能力地图:团队在选型 AI 编码助手时,多了一把贴近实际迁移场景的尺子;
- 可复用的评测脚手架:内部如果有自研的 Coding Agent,可以借鉴 ScarfBench 的 Docker 化沙箱与行为等价性验证方法,搭建私有评测;
- 明确的能力短板信号:L3 以上的跨文件、跨范式重构仍是 AI 的薄弱环节,这恰恰是国内 Agent 团队下一步差异化竞争的高价值方向;
- 数据共建机会:IBM 研究院在博客中也呼吁社区贡献更多真实迁移案例,国内开源社区完全可以贡献 Dubbo、Sofa、TongWeb 等本土框架的迁移样本,反向影响基准演化。
六、技术界的更长远思考
ScarfBench 的出现,也让人重新思考"AI Coding Agent"评估范式的演进路径。从早期的单点函数补全,到 SWE-Bench 的单 PR 修复,再到今天的整库框架迁移,评估单元的粒度正在从"行"扩张到"模块"再扩张到"系统"。这背后的逻辑很清晰:模型能力上去之后,真正稀缺的不再是"会不会写代码",而是"能不能驾驭复杂系统的长尾约束"。
红杉中国在推出 xbench 时反复强调的"Profession Aligned Eval"理念,与 ScarfBench 的思路不谋而合——让评估靠近真实业务流,让分数对应可定价的工作产出。ScarfBench 可以被视为这一思潮在企业 Java 这个庞大垂类上的一次具体落地。
七、获取方式与后续动作
开发者可以通过以下方式快速上手:
- 阅读 IBM 研究院在 Hugging Face 上的官方博客(详见文末参考链接);
- 在 Hugging Face Hub 上拉取数据集与评测脚本;
- 在配套仓库中查看 Docker 化的评测环境,提交自己 Agent 的结果到 LeaderBoard。
IBM 研究院表示,ScarfBench 将作为一个长期演进的基准持续维护——覆盖的框架矩阵会随着 Spring、Quarkus、Micronaut 等的演进而扩展,迁移路径也会从 Java 内部进一步拓展到 Kotlin、Scala 等 JVM 语言生态。下一阶段,团队还计划引入多 Agent 协作迁移的评测协议,模拟真实研发团队中"架构师 + 后端 + 测试"的分工模式。
结语
ScarfBench 的发布是 AI Coding Agent 走向"企业级生产力"过程中的一块关键拼图。它把那些藏在企业代码仓库角落里、最让人头痛却又最有商业价值的迁移任务,搬到了聚光灯下。对模型团队而言,这是一份新的难题清单;对企业团队而言,这是一份现实的能力评估;而对整个行业来说,它清晰地指出了下一阶段竞争的真正战场——不在 LeetCode,而在那些跑了十年的 Spring Boot 应用里。
参考来源
- ScarfBench: Benchmarking AI Agents for Enterprise Java Framework Migration(IBM 研究院官方博客) —— ScarfBench 的官方介绍博客,详细阐述了基准的设计动机、数据集构成、评测协议与首批结果。
- Hugging Face Hub 上的 IBM Research 主页 —— 可在此查找 ScarfBench 数据集、评测脚本及 IBM 研究院发布的其他模型与基准资源。


