智源开源ClawKeeper:用智能体监管智能体

智源联合北邮、信通院发布ClawKeeper v1.0,以Skill-Plugin-Watcher三层架构为OpenClaw智能体提供全生命周期安全防护,直面本地全能智能体的高危攻击面。
OpenClaw 的安全问题终于等来了一个系统性的回应。
近日,北京智源人工智能研究院联合北京邮电大学、中国信息通信研究院发布了 ClawKeeper v1.0——一个专门为 OpenClaw 智能体生态打造的开源安全框架。项目已在 GitHub 开源,论文同步放出。
这不是又一个「安全最佳实践文档」,而是一套可以跑起来的、用智能体监管智能体的实时防御系统。
OpenClaw 到底有多危险?
要理解 ClawKeeper 的价值,得先看清楚它要解决的问题有多棘手。
当前主流的 AI 智能体大致分三类:应用层智能体(豆包、千问上的那些)、云端沙箱智能体(Manus、HaloMate)、以及本地智能体(Claude Code、Gemini CLI)。前两类要么能力有限,要么跑在沙箱里翻不出花;第三类虽然能操作本地资源,但采用零信任策略,每条命令都要用户点头才能执行。
OpenClaw 是个异类。它在默认配置下对技能调用和命令执行不加限制、无需授权,是真正意义上的「本地全能智能体」。能力越大,攻击面越大。
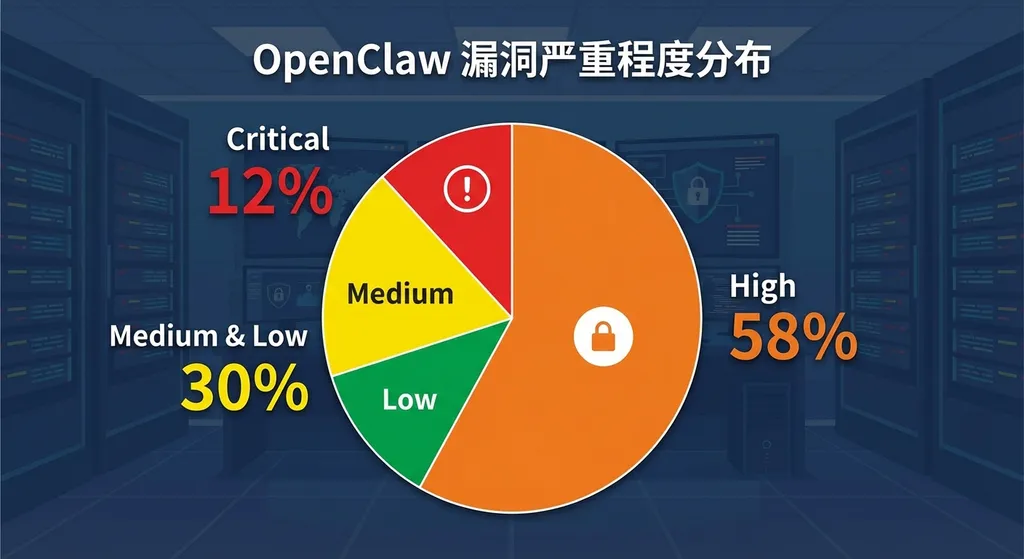
数字很说明问题。根据绿盟科技今年 4 月初的安全分析报告,OpenClaw 相关的 CVE 漏洞在 2026 年 2 月达到披露峰值,集中暴露了沙箱逃逸和指令执行方面的问题。漏洞的严重程度分布更让人捏把汗:
- 严重(Critical)占 12%,可导致远程代码执行、管理员权限获取或 API Key 直接泄露
- 高危(High)占 58%,涉及沙箱逃逸、特权提升、大规模数据泄露
- 两者合计 70%
漏洞类型上,不当授权(CWE-285)占 42%,OS 命令注入(CWE-78)占 22%,路径穿越(CWE-22)占 18%。攻击面高度集中在插件集成和外部 Webhook 这些智能体与外部系统交互的关口。
供应链的情况同样不乐观。2026 年 2 月,安全公司 Snyk 对 ClawHub 和 skills.sh 上的 3984 个第三方技能做了扫描,结果是:13.4%(534 个)包含严重安全问题,包括恶意软件、凭据窃取和提示词注入;36.8%(1467 个)至少存在一个安全漏洞,比如硬编码的 API 密钥。
更具标志性的事件是今年 1 月底到 2 月中旬的「ClawHavoc」供应链投毒攻击——攻击者通过 ClawHub 分发伪装成正常技能的 Atomic macOS Stealer,被 Trend Micro 和 OpenSourceMalware 联合发现。这不是理论上的风险,是已经发生过的真实攻击。
简单说,OpenClaw 的安全现状就是:一个权限几乎不设防的本地全能智能体,跑着一个三分之一技能都有安全隐患的生态市场,还已经被攻击者盯上了。
ClawKeeper 的三层防御架构
ClawKeeper 的核心设计思路是「纵深防御」,但它没有选择简单地给 OpenClaw 加一堵墙,而是设计了三个各司其职又相互配合的防御层:Skill(技能)、Plugin(插件)、Watcher(观察者)。
这个架构的巧妙之处在于,它用 OpenClaw 自身的扩展机制来实现安全防护——用智能体的方式去监管智能体。
第一层:Skill(技能层防御)
这是最内层的防护,直接作用在智能体执行技能的环节。你可以把它理解为给每个技能调用加了一道安检门。
Skill 层主要做两件事:一是对技能的输入输出做实时校验,拦截异常参数和可疑返回值;二是对技能本身做静态分析,在加载阶段就识别出潜在的恶意代码模式。考虑到 ClawHub 上超过三分之一的技能存在安全问题,这层防护的必要性不言而喻。
对于开发者来说,这意味着你不需要逐个审计每个第三方技能的源码,ClawKeeper 会在运行时帮你把关。当然,它不能替代人工审计,但至少把最明显的风险挡在了外面。
第二层:Plugin(插件层防御)
Plugin 层处理的是智能体与外部系统交互的安全问题——也就是前面提到的漏洞重灾区。
这一层重点防御的场景包括:Webhook 集成(Discord、Slack、Matrix 等)的权限校验、API 调用的凭据保护、以及外部数据输入的消毒处理。还记得那 42% 的不当授权漏洞吗?Plugin 层就是冲着这个来的。
它的工作方式类似于传统 Web 应用中的中间件:拦截所有进出智能体的外部通信,按预定义的安全策略做过滤和校验。不同的是,这些策略可以根据部署环境动态调整,这对局域网内的智能体集群管理尤其重要。
第三层:Watcher(观察者层防御)
这是最外层,也是 ClawKeeper 最有意思的一层。
Watcher 本质上是一组独立运行的监控智能体,它们不参与业务逻辑,只负责观察其他智能体的行为模式。当检测到异常行为——比如某个智能体突然开始大量读取不相关的文件、尝试访问未授权的网络地址、或者执行与其任务描述不符的系统命令——Watcher 会触发告警甚至直接阻断。
这就是「用智能体监管智能体」的核心含义。传统的规则引擎只能匹配已知的攻击模式,而 Watcher 智能体可以理解上下文,判断一个行为在当前场景下是否合理。比如,一个负责文档整理的智能体去读取 ~/.ssh/ 目录,规则引擎可能需要你手动配置黑名单路径,但 Watcher 可以直接判断「这不对劲」。
当然,用 AI 监管 AI 本身也引入了新的问题——监管者自身的可靠性怎么保证?ClawKeeper 的做法是让 Watcher 运行在独立的、权限受限的进程中,并且 Watcher 之间可以交叉验证。这不是完美方案,但在工程上是务实的。
跟同类方案比,ClawKeeper 的位置在哪?
智能体安全不是一个新话题。最近几个月,这个方向上的开源项目密集涌现:
| 项目 | 主要思路 | 侧重点 | |------|---------|--------| | ClawKeeper | Skill + Plugin + Watcher 三层架构 | OpenClaw 生态全生命周期防护 | | ClawAegis(蚂蚁+清华) | 全链路纵深防御插件 | 五阶段覆盖,偏通用智能体 | | MCP Guardian | 安全优先的中间层 | MCP 协议层面的防护 | | ShieldAgent | 可验证安全策略推理 | 形式化验证方向 | | LlamaFirewall(Meta) | 护栏系统 | 通用 LLM 智能体防护 |
ClawKeeper 的差异化很明确:它是专门为 OpenClaw 生态定制的。这既是优势也是局限——针对性强意味着防护更到位,但也意味着如果你用的不是 OpenClaw,这套方案的适用性会打折扣。
相比蚂蚁和清华联合开源的 ClawAegis,ClawKeeper 的 Watcher 机制是一个明显的差异点。ClawAegis 更偏向传统的规则+策略路线,而 ClawKeeper 引入了智能体级别的行为监控,理论上对未知攻击模式的适应性更好。但 ClawAegis 的通用性更强,不绑定特定的智能体框架。
值得注意的是,这些项目并不互斥。在实际部署中,完全可以在 MCP 协议层用 MCP Guardian,在 OpenClaw 运行时层用 ClawKeeper,形成更完整的防御纵深。
对开发者意味着什么?
如果你正在用 OpenClaw 构建智能体应用,ClawKeeper 基本上是现阶段的必选项。原因很简单:OpenClaw 默认配置下的安全模型太过宽松,而你不可能手动审计生态中的每一个第三方技能。
部署上,ClawKeeper 特别适合局域网内的智能体集群场景——比如企业内部部署的多智能体协作系统。在这种场景下,智能体之间的通信频繁,攻击面大,但又不能像公有云那样依赖外部安全服务,ClawKeeper 的本地化部署和 Watcher 机制正好对症。
对于通过 API 调用各类模型来驱动智能体的开发者,安全防护需要从模型调用层就开始考虑。比如你用 OpenAI Hub 这类聚合平台统一调用 GPT、Claude、Gemini 等模型的 API,那么在智能体的 system prompt 中就应该内置安全约束,再配合 ClawKeeper 的运行时防护,形成从模型层到执行层的完整链路。
一个典型的安全加固调用示例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.openai-hub.com/v1",
api_key="your-api-key"
)
# 在 system prompt 中内置安全约束
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": (
"你是一个受安全策略约束的智能体。执行任何文件操作前必须校验路径合法性,"
"禁止访问用户主目录之外的敏感路径,禁止执行未经白名单授权的系统命令。"
"所有外部 API 调用必须通过安全代理层。"
)
},
{
"role": "user",
"content": "帮我整理 ./documents 目录下的文件"
}
]
)
print(response.choices[0].message.content)
当然,system prompt 层面的约束只是第一道防线,容易被提示词注入绕过。真正的安全还是要靠 ClawKeeper 这类运行时框架在执行层做硬拦截。
更大的背景
ClawKeeper 的发布不是孤立事件,它是整个行业对智能体安全问题集体觉醒的一部分。
今年 3 月,新修改的《网络安全法》明确要求加强人工智能风险监测评估和安全监管。政策层面的信号已经很清晰:智能体不是想怎么跑就怎么跑的。
从技术社区的反应看,2026 年 Q1 是智能体安全方案的集中爆发期。ClawKeeper、ClawAegis、MCP Guardian、ShieldAgent、LlamaFirewall……几乎每周都有新的安全框架或工具发布。这说明两件事:第一,智能体的安全问题确实严峻到了不得不解决的地步;第二,行业还没有形成统一的安全标准和最佳实践,大家都在摸索。
对于 OpenClaw 生态来说,ClawKeeper 的出现是一个积极信号。一个开源项目的安全性,很大程度上取决于社区是否愿意正视问题并投入资源去解决。智源、北邮、信通院三家联合出手,至少说明学术界和标准制定机构已经把 OpenClaw 的安全问题当回事了。
但也要清醒地看到,ClawKeeper v1.0 还只是起点。智能体安全是一个攻防持续演进的领域,今天能防住的攻击模式,明天可能就被绕过。Watcher 机制的有效性需要在真实攻击场景中持续验证,三层架构之间的协调开销对性能的影响也需要更多的基准测试数据。
不过,有总比没有强。在 OpenClaw 默认配置几乎「裸奔」的现状下,ClawKeeper 至少给开发者提供了一个可以立即用起来的安全基线。
参考来源:
