Parsewise 上线跨文档推理 API:RAG 之外的另一条路

YC P25 批次的 Parsewise 昨日发布文档推理 API,主打多文档跨文件推理、实体链接和矛盾检测。这不是又一个 RAG 封装,而是把'读一叠文件回答一个问题'这件事重新做了一遍。
又一个做文档 AI 的,但这次思路不太一样
YC P25 批次的 Parsewise 昨天在 Hacker News 挂出 Launch 帖,正式发布他们的文档推理 API。团队给自己的定位很直接:不是单文档解析器,也不是又一个 RAG 封装,而是专门解决跨文档推理这件事。
听起来又是个把 LLM 包一层的产品?先别急着划走。过去两年做文档 AI 的公司多如牛毛,Unstructured、LlamaParse、Reducto、Chunkr,加上各家云厂商的 Document AI,赛道已经拥挤到令人窒息。但仔细看 Parsewise 的切入点,会发现他们盯的不是"把 PDF 解析得更干净",而是一个所有做过 RAG 的人都被折磨过的问题:当答案需要从多份文件里拼出来的时候,RAG 就开始不讲道理了。
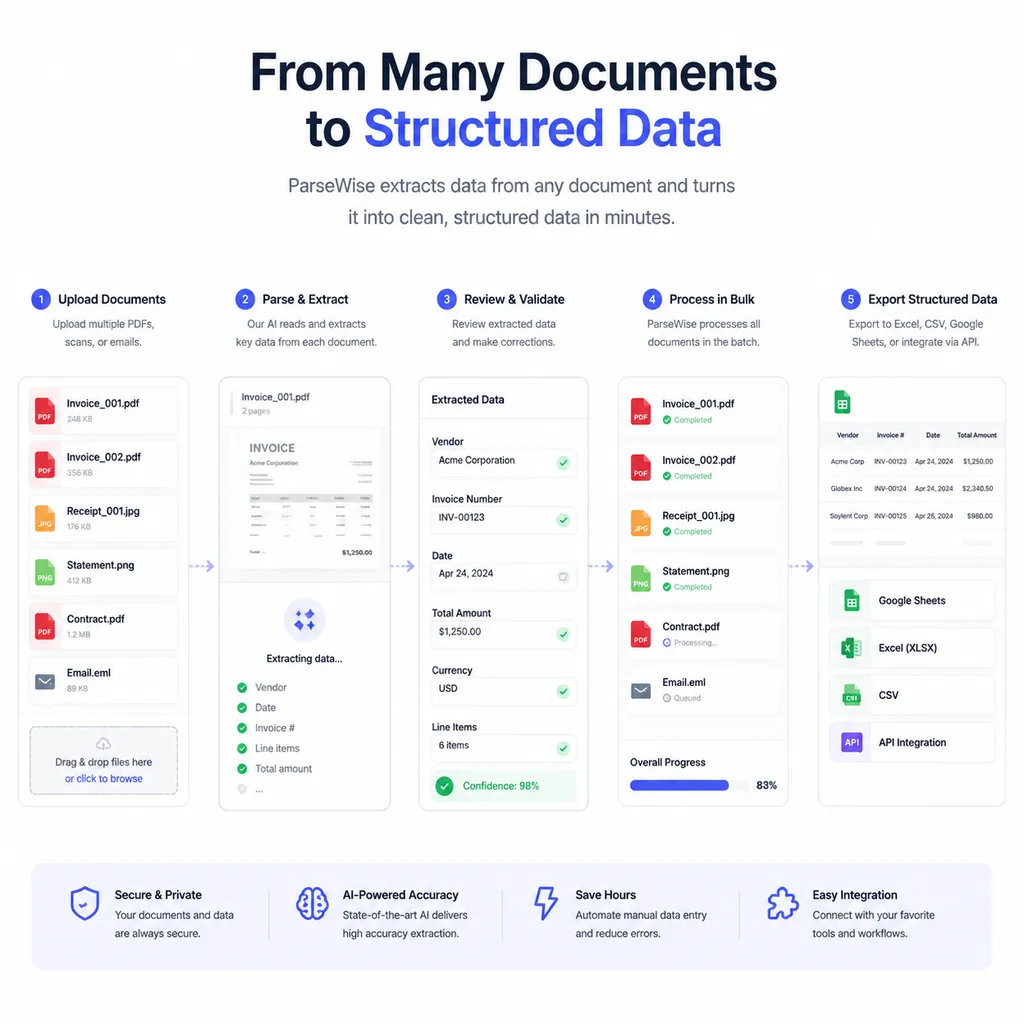
RAG 的天花板,从多文档开始
做过企业文档场景的开发者应该都遇到过这种需求:一笔贷款申请里,借款人的信息散落在申请表、W-2、银行流水、征信报告四份文件里,Doc A 写"John Smith, borrower",Doc B 写"J. Smith",Doc C 只有社保号后四位。要回答"这个借款人过去 12 个月的平均月收入是多少",得先做实体对齐,再做数值抽取,最后跨文档汇总。
传统 RAG 到这里基本就跪了。原因也不复杂:
- 向量检索是"相似",不是"相关"。切片之后,跨文件的语义关联被切没了。
- 实体消歧靠模型硬猜。同一个人在不同文件里叫法不一样,Top-K 检索根本区分不出来。
- 矛盾发现基本不可能。文件 A 说月收入 8000,文件 B 的银行流水显示实际到账 6500,RAG 只会随便挑一个塞进 context。
- 可追溯性差。答案给出来了,但你没法准确定位到是哪份文件的哪一页哪一行。
Parsewise 想解决的就是这一层。他们的 API 输出不是一段自然语言回答,而是一个结构化的单一响应,包含跨文档的实体链接、字段来源、以及标注了 bounding box 的证据溯源。官网上写得很直白:"cross-document reasoning with full traceability and no false negatives",重点在最后半句 —— 没有假阴性,这在合规、金融、法律场景里比准确率还重要。
产品的几个技术判断
翻了一下他们的官网和 Launch 帖里的讨论,能看出这家团队几个比较硬的技术选择:
1. 用 Agent 而不是 Pipeline
Parsewise 明确说 API 背后是 Agent 架构,可以写代码、执行代码、访问网络来回填缺失字段和验证已抽取数据。这个设计挺聪明。传统文档抽取是个固定 pipeline:OCR → Layout → NER → 结构化。哪一步出问题,后面全崩。
换成 Agent 之后,模型发现"这份 W-2 的年收入和银行流水对不上"时,可以主动去查两个数字的来源,甚至跑一段 Python 算一下税前税后。这有点像 OpenAI 的 Code Interpreter 用在文档场景里,但目标更明确 —— 不是让用户和文档聊天,而是把一堆文件榨出一个可信的结构化结果。
2. 用 Claude 作为底座
官网首页有一行小字:"Built with Claude on Parsewise"。选 Claude 而不是 GPT,我理解是三个原因:长上下文(跨文档天然吃 context 长度)、指令跟随(结构化输出稳定性)、以及最近半年 Claude 在文档理解上的 benchmark 确实压过 GPT。这个选择本身也反映出他们对"这是个推理任务而非生成任务"的判断 —— 谁的推理链更稳,就用谁。
3. 提供 UI 工具包
这一点容易被开发者忽略但其实很重要。Parsewise 除了 API 还开源了一套 UI 组件,用来展示 bounding box、跳转到原文位置、显示矛盾提示。为什么这很关键?因为任何做 B 端文档抽取的产品,最后 80% 的时间都花在"人工审核"环节上。API 再准,用户还是要看一眼。给一套现成的 review UI,省下的是客户几个月的前端开发时间。
一个 60 秒的多文档 pipeline?
Parsewise 在官网上强调 "Build a multi-document pipeline in 1 minute",我理解他们的调用模型大概是这个形态 —— 上传一批文件,指定要抽取的 schema,剩下的实体对齐、矛盾检测、来源标注全部由 API 完成。
和市面上其他方案比一下差异更明显:
| 方案 | 单文档抽取 | 跨文档实体链接 | 矛盾检测 | 证据溯源 | |------|-----------|--------------|---------|---------| | LlamaParse / Unstructured | ✅ | ❌ | ❌ | 部分 | | Google Document AI | ✅ | ❌ | ❌ | ✅ | | 自建 RAG | ✅ | 靠模型 | ❌ | 弱 | | Parsewise | ✅ | ✅ | ✅ | ✅ |
如果你的场景是"一份合同抽字段",Parsewise 没啥优势,用便宜的方案就行。但一旦进入"一叠文件回答一个问题"的模式 —— 贷款审核、KYC、尽调、保险理赔、法律 e-discovery —— 差距就出来了。
谁会买单
从 HN 评论区的讨论看,最先响应的果然是金融和法律行业的开发者。有个做小贷 SaaS 的评论者说他们内部试用了两周,最有价值的不是抽取准确率,而是矛盾检测直接把一批伪造流水的申请给筛出来了。这个反馈挺有意思 —— 说明 Parsewise 的价值可能不止在"提效",还在于"发现单文档看不到的东西"。
可以合理预期的几类场景:
- 金融合规:KYC、AML、贷款审核,跨多份证明文件做主体识别和交叉验证
- 法律尽调:并购项目里几百份合同的条款一致性检查、义务对齐
- 医疗保险理赔:病历、处方、账单的跨文件一致性核验
- 供应链审计:发票、报关单、物流单的三单匹配
这些场景过去要么靠人海战术,要么靠一堆规则引擎硬凑。Parsewise 试图把这层"跨文件推理"抽象成 API,让上游的产品团队只管调用。
值得担心的几个点
作为编辑,也得给读者提几个泼冷水的观察:
一是延迟和成本。Agent 架构 + Claude + 多文档 context,单次调用的 token 消耗和响应时间都不会低。他们官网没公布定价,但可以预期不会便宜。做实时场景的团队要掂量一下。
二是"无假阴性"的承诺经不经得起推敲。这是个非常大的 claim。任何做过文档抽取的人都知道,OCR 阶段丢字、扫描件低质量、手写签名,这些都是天然的信息损失源。做到"跨文档层面无假阴性"和"从原始文件到最终结果无假阴性"是两回事,营销文案不要过度解读。
三是可控性。Agent 会写代码、跑代码、上网查证,这套流程对 B 端客户来说既是能力也是风险。金融、医疗客户对"模型自主执行了什么"是有强审计要求的,Parsewise 后面必然要在可观测性和 guardrail 上补课。
一点行业观察
2026 年上半年,文档 AI 这个赛道明显在分化。一头是往下走做基础设施的(OCR、layout、结构化),另一头是往上走做垂直 agent 的(合同 review、财报分析)。Parsewise 选的是中间那条最难走但也最有想象力的路 —— 做跨文档推理这一层的通用能力。
中科院和阿里之前发布的 LongDocURL 基准也印证了这个方向的重要性:多模态长文档理解、跨元素定位、数值推理已经是学术界公认的下一个硬骨头。Parsewise 把这块能力先包成 API 卖出去,商业化节奏比学术界快了不止一个身位。
值得关注的是,Parsewise 目前用 Claude 作为核心推理引擎,后续会不会开放模型选择、支持 GPT 或者国产模型作为 backbone,是一个开放问题。对国内的开发者来说,如果需要用类似能力但又受限于 Claude 的访问,可以先用 OpenAI Hub 这类聚合平台调 Claude 做原型验证 —— 一个 Key 调所有主流模型(GPT、Claude、Gemini、DeepSeek),国内直连、兼容 OpenAI 格式,做多文档推理这种需要频繁切换模型对比效果的场景,省掉了自己维护多套 SDK 的负担。
最后一句话总结:Parsewise 不是 RAG 的替代,而是补上了 RAG 一直没解决的那部分。如果你正在做的产品里,有一步流程需要"读一叠文件、给一个结构化答案、还要能说清答案是从哪儿来的",这家值得看一眼。
参考来源
- Launch HN: Parsewise (YC P25) – Reason Across Documents with an API —— Parsewise 的 Hacker News Launch 帖,评论区有大量来自金融、法律行业开发者的一手反馈


