Claude Code顾问工具:让便宜模型请贵模型当军师

Anthropic为Claude Code推出Advisor Tool API,核心思路是让Sonnet等低成本模型执行任务,遇到难题时调用Opus等旗舰模型提供决策建议,实现成本与智能的最优平衡。
Anthropic 这周干了一件挺聪明的事——给 Claude Code 加了一个叫「顾问工具」(Advisor Tool)的新 API。
一句话讲清楚:让便宜的模型干活,遇到搞不定的问题时,花钱请贵的模型出主意。
这不是什么概念验证,而是已经以 beta 形式开放的正式 API。它直接改变了开发者构建 AI Agent 时的成本结构。
先说问题:旗舰模型太贵,便宜模型不够聪明
做过 AI Agent 开发的人都知道一个现实——你想让 Agent 靠谱,就得用最强的模型;但最强的模型按 token 计费,跑一个复杂任务动辄几美元,规模化之后成本根本扛不住。
拿 Anthropic 自家的模型来说,Opus 4 的能力毋庸置疑,但它的价格是 Sonnet 的好几倍。大多数 Agent 场景里,80% 的工作其实不需要 Opus 级别的推理能力——读文件、写样板代码、做格式转换,Sonnet 甚至 Haiku 就能搞定。但剩下那 20% 的关键决策,比如架构选型、复杂 bug 的根因分析、多步推理的路径规划,便宜模型确实会翻车。
之前开发者的做法要么是全程用贵模型(烧钱),要么全程用便宜模型(翻车),要么自己写一套路由逻辑来分流(费人)。
顾问工具本质上是 Anthropic 把这个「路由」能力做成了原生 API。
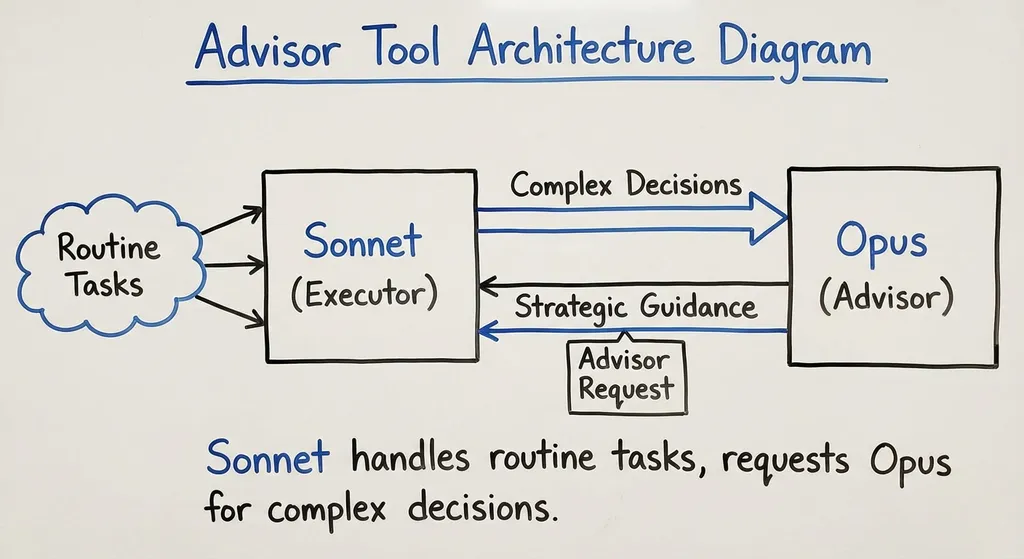
怎么工作的:不是套娃,是分层协作
顾问工具的设计思路很清晰,用 Anthropic 的话说叫「分层协作」。
具体来说,你的 Agent 主循环跑在一个成本较低的模型上(比如 Sonnet),这个模型负责执行具体任务。当它判断当前问题超出自己能力范围时,可以调用一个特殊的工具——Advisor,把问题抛给一个更强的模型(比如 Opus)。Opus 不直接执行任务,只返回建议和分析,Sonnet 拿到建议后继续执行。
这跟简单的「模型套娃」不一样。套娃是 A 调 B,B 调 C,调用链越来越深,上下文越传越乱。顾问工具更像是公司里的组织架构:初级工程师(Sonnet)遇到拿不准的技术方案,去找架构师(Opus)问一嘴,架构师给个方向,初级工程师回去继续干活。架构师不需要了解所有执行细节,初级工程师也不需要每件事都请示。
从 API 层面看,Advisor 被定义为一种新的工具类型。你在 tools 数组里声明它,就像声明一个普通的 function tool 一样,只不过 type 字段是 advisor_20260301。
调用时需要在请求头里加上 beta 标识:
anthropic-beta: advisor-tool-2026-03-01
然后在 tools 里这样声明:
{
"type": "advisor_20260301",
"name": "opus_advisor",
"model": "claude-opus-4-20260401",
"description": "当遇到复杂架构决策或多步推理问题时,咨询高级模型的建议"
}
当执行模型(Sonnet)在对话过程中决定需要帮助时,它会像调用普通工具一样调用这个 advisor,把当前问题的上下文传过去,Opus 返回分析和建议,整个过程对开发者来说是透明的。
实际效果:省钱是真的,但没那么神
社区里已经有不少人在测了。Linux.do 上有个帖子的评论挺有意思,有人让 Sonnet 自己评价这个功能,Sonnet 回了一句:「我是无敌的,不需要 Opus 费心。」
玩笑归玩笑,实际测试下来,效果因场景而异。
在代码生成类任务上,Sonnet + Opus 顾问的组合确实能接近纯 Opus 的质量,同时成本降低 60-70%。原因很直观:大部分代码生成工作 Sonnet 本身就能胜任,只有在需要理解复杂业务逻辑或做架构级决策时才需要 Opus 介入。
但在需要持续深度推理的任务上,比如长链条的数学证明或复杂的多文件重构,顾问模式的效果就没那么理想了。因为 Opus 作为顾问只能看到 Sonnet 传过来的上下文片段,而不是完整的推理链,这会导致建议的质量打折扣。
换句话说,顾问工具解决的是「偶尔需要高级智能」的场景,而不是「全程需要高级智能」的场景。这个定位很务实。
跟竞品比:思路不新,但实现最干净
多模型协作这个概念不是 Anthropic 首创的。
开源社区早就有类似的实践。知乎上有篇文章详细分析了 Claude Code 生态里的几个多模型协作方案——OMO、omc 等项目,通过 Task tool 的 model 参数在 Claude 家族内做模型切换。还有人通过 MCP 协议把 Gemini 接入 Claude Code,实现跨厂商的模型协作。
但这些方案都有一个共同的问题:它们是在应用层做的拼接,开发者需要自己处理上下文传递、错误处理、token 计数等一堆脏活。
顾问工具的优势在于它是 API 原生的。模型之间的上下文传递、token 管理、错误回退都由 Anthropic 在后端处理好了。对开发者来说,加一个 advisor 工具声明就完事了,不需要自己搭一套编排框架。
OpenAI 那边目前没有直接对标的功能。GPT 系列的 function calling 很成熟,但模型间的协作还是得开发者自己编排。Google 的 Gemini 有 Agent 框架,但也没有做到 API 级别的多模型原生协作。
所以 Anthropic 这一步,算是在 API 设计层面领先了半个身位。
对开发者意味着什么
如果你正在做 AI Agent 开发,顾问工具值得认真看一下。
最直接的价值是成本优化。之前你可能因为预算限制只能用 Sonnet 跑 Agent,现在可以在关键节点引入 Opus 的能力,整体成本只增加一点点,但可靠性能上一个台阶。
更深层的影响是,它改变了 Agent 架构的设计思路。以前你设计 Agent 时,模型选择是一个全局决策——选了 Sonnet 就全程 Sonnet,选了 Opus 就全程 Opus。现在模型选择变成了一个局部决策,Agent 可以根据当前任务的难度动态调整使用的模型级别。
这很像微服务架构里的思路:不是所有请求都需要打到最强的服务器上,大部分请求用普通实例处理,只有复杂请求才路由到高配实例。
实战:通过 OpenAI Hub 调用 Advisor Tool
对于国内开发者来说,直连 Anthropic API 可能不太方便。OpenAI Hub(openai-hub.com)已经支持了 Claude 全系列模型的 API 调用,兼容 OpenAI 格式,可以直接用来测试顾问工具。
下面是一个完整的调用示例,展示如何让 Sonnet 作为执行者、Opus 作为顾问来完成一个代码审查任务:
import anthropic
# 通过 OpenAI Hub 调用,国内直连
client = anthropic.Anthropic(
base_url="https://openai-hub.com/anthropic",
api_key="your-openai-hub-key",
)
# 定义顾问工具
tools = [
{
"type": "advisor_20260301",
"name": "opus_advisor",
"model": "claude-opus-4-20260401",
"description": "当遇到复杂架构问题或需要深度代码分析时,咨询 Opus 的建议"
}
]
# 用 Sonnet 作为主执行模型
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
tools=tools,
extra_headers={
"anthropic-beta": "advisor-tool-2026-03-01"
},
messages=[
{
"role": "user",
"content": "请审查以下代码的架构设计是否合理,并给出优化建议:\n\n"
"```python\n"
"class OrderService:\n"
" def __init__(self):\n"
" self.db = Database()\n"
" self.cache = Redis()\n"
" self.mq = RabbitMQ()\n"
" self.payment = PaymentGateway()\n"
" self.email = EmailService()\n"
"\n"
" def create_order(self, user_id, items):\n"
" order = self.db.insert(user_id, items)\n"
" self.payment.charge(user_id, order.total)\n"
" self.cache.invalidate(f'user:{user_id}')\n"
" self.mq.publish('order.created', order)\n"
" self.email.send(user_id, 'Order confirmed')\n"
" return order\n"
"```"
}
]
)
print(response.content)
在这个例子里,Sonnet 会先尝试自己分析这段代码。当它发现这涉及到服务耦合、事务一致性、错误处理策略等架构级问题时,大概率会主动调用 opus_advisor 来获取更深入的分析。最终返回给你的结果,是 Sonnet 的执行能力加上 Opus 的判断力的组合。
如果你更习惯 OpenAI 兼容格式,也可以通过 OpenAI Hub 的统一接口来调用:
from openai import OpenAI
client = OpenAI(
base_url="https://openai-hub.com/v1",
api_key="your-openai-hub-key",
)
# 使用 OpenAI 兼容格式调用 Claude Sonnet
response = client.chat.completions.create(
model="claude-sonnet-4-20250514",
messages=[
{
"role": "user",
"content": "分析这段代码的架构问题并给出重构方案..."
}
],
max_tokens=4096
)
print(response.choices[0].message.content)
一个 Key 就能调 Claude、GPT、Gemini、DeepSeek 等主流模型,在做多模型对比测试时特别方便。
几个值得注意的细节
第一,顾问工具目前是 beta 状态。API 签名后续可能会变,生产环境用的话要做好兼容性准备。
第二,顾问模型的选择不限于 Opus。理论上你可以让 Haiku 当执行者、Sonnet 当顾问,进一步压低成本。甚至可以声明多个不同级别的顾问,让执行模型根据问题难度选择咨询哪个。
第三,顾问调用是有额外延迟的。每次咨询相当于多了一次 API 往返,如果你的场景对延迟敏感,需要权衡。实测下来,一次顾问调用大概增加 2-5 秒的延迟,取决于问题复杂度和 Opus 的响应长度。
第四,上下文窗口的管理。执行模型传给顾问的上下文是有限的,不是把整个对话历史都丢过去。这意味着你需要在 Agent 设计时考虑好,什么信息是顾问做判断时必须知道的,确保这些信息在调用时被包含进去。
往远了看
顾问工具的意义不只是省钱。
它代表了一种趋势:AI 系统正在从「单一大模型解决所有问题」走向「多个专业模型协作」。这跟软件工程的演进路径很像——从单体应用到微服务,从一台大服务器到分布式集群。
未来大概率会看到更多这样的原生协作 API 出现。不只是同一家的模型之间协作,跨厂商的模型协作也会成为常态。想象一下,一个 Agent 用 Claude 做文本推理,用 Gemini 做多模态理解,用 DeepSeek 做数学计算,每个模型各司其职。
当然,这也给 API 聚合平台带来了新的机会。当开发者需要在一个 Agent 里调用多家模型时,统一的 API 入口和 Key 管理就变得更有价值了。
顾问工具现在还只是 beta,但方向是对的。对于正在做 Agent 开发的团队,建议现在就开始试,至少把它纳入你的架构评估范围。等到正式版发布时,你已经知道它适合你的哪些场景了。
参考来源:
- Claude Code 顾问工具讨论帖 - Linux.do(社区对 Advisor Tool 的讨论和实测反馈)
- Claude Code 多模型 Agent 协作实践:OMO、omc - 知乎专栏(多模型协作方案的对比分析)
