OpenAI 发新基准 GeneBench-Pro,专治 AI 生物学「假聪明」

OpenAI 于 6 月 30 日推出 GeneBench-Pro,一个专门测试 AI 模型在真实生物学研究场景下推理判断能力的基准。129 道题目、20-40 小时的专家工时,全部基于合成数据构建,目的就是把靠背答案和碰运气的模型筛出去。
OpenAI 在 6 月 30 日抛出了一个新东西:GeneBench-Pro。这是一个专门给 AI 模型做生物学研究能力体检的基准测试,129 道题,每道题让人类专家来做要花 20 到 40 个小时。Greg Brockman 在 X 上直接给出了结论:GPT-5.6 Sol 在这个基准上是一次大的跃进。
这个动作本身其实并不孤立。就在几天前,OpenAI 刚刚发布了首款生命科学专用推理模型 GPT-Rosalind,联手了安进、莫德纳、艾伦研究所一票制药和研究机构。两件事放在一起看,OpenAI 在生命科学这条赛道上的意图已经写得很清楚——先做模型,再造尺子,然后把生态圈起来。
传统基准测试到底哪里出了问题
要理解 GeneBench-Pro 的价值,得先说清楚现有那些生物学 AI 基准的毛病。
目前主流的做法基本分两种。一种是知识型题库,像考研一样让模型答选择题,测的是「记没记住」。这种测试早在 GPT-4 时代就已经饱和了,前沿模型分数都在 90+ 徘徊,区分度约等于零。
另一种更进阶,比如 BixBench、LAB-Bench 这类,会给模型真实的生物信息学任务,让它跑代码、查数据库。但这里有个隐藏的陷阱:如果用历史真实数据出题,同一份数据往往存在多条合理的分析路径。模型即便选错了方法,也可能因为数据本身的巧合而给出正确答案。评分者看到答案对了就打勾,但模型的推理过程其实是错的。
这就是所谓的「走捷径」问题。在长流程任务里,这种偏差会被无限放大——你根本分不清模型是真的懂,还是运气好。
合成数据是解法,也是设计哲学的转变
OpenAI 给出的解决方案是全部用合成数据构建题目。这个选择挺关键的。
合成数据意味着 OpenAI 完全掌握底层的因果结构和数据生成过程。他们知道答案是什么,也知道通往答案的正确路径是什么。当模型给出结论时,可以反向验证它走的路对不对,而不是只看终点。
打个比方,传统评测像是给一道数学应用题,只对答案;GeneBench-Pro 更像是既看答案也看解题过程,还要求你在计算过程中处理故意混进来的错题条件。模型必须真正理解「这份数据在告诉我什么」,而不是套用模板。
更狠的一点是,题目本身刻意做成了「模糊、不完整、带有干扰」的状态。这非常接近真实科研现场——你从测序仪器拿到的数据从来不是干净的,实验记录也从来不完整,你需要自己判断哪些数据可信、用什么方法分析、结果能不能支撑下一步决策。
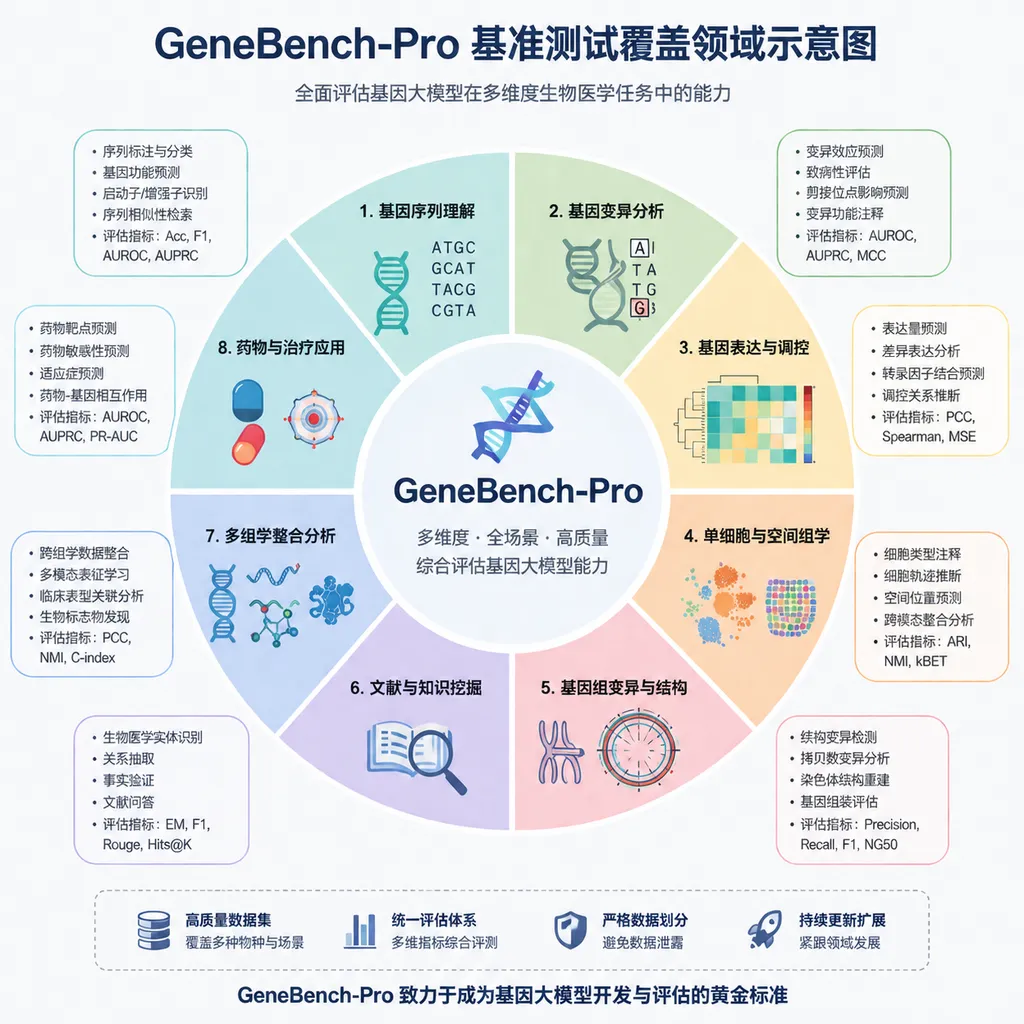
129 道题,覆盖 10 个大领域
GeneBench-Pro 的题目结构值得展开看看。
- 总量:129 道题
- 分类:10 个大领域,21 个子领域
- 覆盖方向:基因组学、定量生物学、转化医学
- 子领域举例:统计遗传学、群体遗传学、功能基因组学、蛋白质组学
每道题的构成基本一致:一份接近真实科研环境的数据集,一段简短的实验背景说明,加上一个与后续决策相关的目标问题。模型需要自主完成数据探索、方法选择,边做边修正策略,最终给出可以用于决策的答案。
注意「与后续决策相关」这个措辞。这不是让你算出一个 p 值就完事,而是要回答类似「基于这份数据,我们下一步该做什么实验」这种开放式问题。这是 GeneBench-Pro 和以往基准最本质的区别——它测的不是数据分析能力,而是研究判断力。
20 到 40 小时的专家工时意味着什么
Brockman 提到「每道题让人类专家花 20 到 40 小时」,这个数字挺震撼的。
对比一下,SWE-bench 上一道题人类工程师大概几十分钟到几小时;GPQA Diamond 里博士级问题也就是十几分钟量级。20 到 40 小时是什么概念?基本等同于一个博士生一到两周的工作量,或者一个初级 postdoc 完整跑一次分析流程的时间。
这个时长本身传递了一个信号:OpenAI 已经不满足于测「智力」,开始测「耐力」和「工程组织能力」。长周期、重工具调用、多步决策的场景,是他们下一步押注的方向。这也解释了为什么 GPT-Rosalind 特别强调工具调用能力和 50 多种科学数据库的连接。
评分怎么做
避免评分偏差是 OpenAI 反复强调的点。除了合成数据这个根基,官方还做了几件事:
- 可验证性优先:因为知道正确路径,评分系统可以检查中间步骤而不只是最终答案
- 鲁棒性检查:每道题都经过 agent 测试和专家复审,确保题目本身没有漏洞
- 第三方评测:官方会开放 129 道题里的 50 道给 Artificial Analysis 做独立评测,这样各家模型的分数就有一个中立的公开榜单
第三点其实挺聪明的。Artificial Analysis 是行业里公认的独立评测机构,把评测权部分交出去,既避开了「自己出题自己给自己打高分」的质疑,也变相把 GeneBench-Pro 推成了跨厂商的标准。
GPT-5.6 Sol 表现如何
Brockman 说 GPT-5.6 Sol 是「a big step forward」,但没有放具体分数。结合 GPT-Rosalind 官方页面披露的数据看,OpenAI 系模型在生物学任务上确实一路领跑:
- 在 BixBench(真实生物信息学与数据分析)测试中,GPT-Rosalind 在所有已公布评分的模型中名列前茅
- 在 LAB-Bench 2 的 11 项任务里,GPT-Rosalind 有 6 项胜过 GPT-5.4,其中 CloningQA(分子克隆方案端到端设计)提升最显著
- 与 Dyno Therapeutics 合作的 RNA 序列功能预测测试中,模型十次提交里的最佳表现超过了 95% 的人类专家
把这些数据放在一起,GeneBench-Pro 本质上是给这一代生命科学模型找一把新的、更严苛的尺子。旧尺子已经量不出差距了。
已经放出来的东西
目前 OpenAI 在 Hugging Face 上开源了 10 道代表性题目,配了可交互 web 界面供外部研究人员体验。剩下的题目会陆续开放给 Artificial Analysis 做第三方评测。
对开发者来说,值得关注的几点:
- 这 10 道公开题可以直接拿来跑,测试自己在用的模型在计算生物学场景下到底能不能打
- 数据集本身是研究计算生物学 agent 的好素材,即便不做基准评测也有参考价值
- 后续 Artificial Analysis 的榜单会成为跨厂商模型能力对比的重要参考
OpenAI Hub 目前已经支持 GPT 系列全线模型的调用,同一个 Key 就能切换测试不同模型在 GeneBench-Pro 公开题上的表现,国内直连无需自建代理,对做生物医药方向 AI 应用的团队来说算是省了不少环境成本。
一点判断
从 GPT-Rosalind 到 GeneBench-Pro,OpenAI 在生命科学的布局节奏能看出来:先造能力,再定标准,最后收编生态。这个打法其实和当年 OpenAI 定义通用大模型的路径一样——先有 GPT,再推 MMLU、HumanEval 这些基准,然后把行业拉到自己的评价体系里。
生命科学是个特殊的战场。它数据量大、计算密集、决策链条长、门槛极高,而且商业价值以百亿美元计——一款新药从立项到上市要 10 年、20 亿美元,任何能压缩这个周期的工具都会被制药公司抢着买单。这也是为什么 OpenAI 直接把安进、莫德纳、赛默飞世尔这种巨头拉进来做联合客户。
GeneBench-Pro 短期内可能不会像 SWE-bench 那样成为开发者天天挂在嘴边的东西,毕竟不是所有人都在做生物学。但对于想把大模型推进到「真正做研究」这个层级的所有厂商来说,这份基准会是一个绕不过去的参考坐标。
谁在真的做研究,谁在假装做研究,129 道题跑一遍就知道。
参考来源
- OpenAI 推出 GeneBench-Pro 基准测试,用于评估 AI 模型生物学计算能力 - IT之家:IT之家 7 月 1 日发布的中文报道,覆盖 GeneBench-Pro 的核心设计与题目结构
- GeneBench-Pro 公开题数据集 - Hugging Face:OpenAI 官方开源的 10 道代表性题目,含可交互 web 界面


