MOTHRAG开源:干掉知识图谱,多跳RAG照样打赢GraphRAG

MOTHRAG把GraphRAG那套离线建图的活儿全砍了,用查询时编排+稠密索引硬刚多跳问答,HotpotQA拿下78.1分,比GraphRAG高近10个点。
一个反直觉的结论:做多跳 RAG,你可能根本不需要知识图谱
过去两年,做多跳 RAG 的圈子基本形成了一个共识——想要在 HotpotQA、MuSiQue 这种需要跨文档推理的任务上拿高分,你得建图。微软 GraphRAG 从 2024 年 7 月开源之后一路飙到 31K star,HippoRAG、RAPTOR、LightRAG 一茬接一茬,路线几乎没有分歧:先用 LLM 把语料抽成实体-关系三元组,再跑社区检测,查询时在图上做遍历。
这套东西效果确实好,但代价也很直白:每次数据变更,都要重跑一遍 LLM 索引。对于价目表、内部工单、每日新闻、客服记录这种高频更新的语料,重建图的账单是持续性的、看得见的血流。微软自己在 LazyGraphRAG 里已经承认了这件事,把社区摘要推迟到查询时,索引成本从几百刀降到 5 刀以下,代价是每次查询多 2–8 秒延迟。
刚在 Reddit 上开源的 MOTHRAG(Moth-Retrieval)想得更极端一点:图这东西,能不能干脆不要?
作者的回答是:不要图、不要 GPU、不要离线重建,全部走商用 API 就能跑。而且——这是最扎心的部分——在三个多跳基准上,它把 GraphRAG、HippoRAG、RAPTOR 全按在地上摩擦了一遍。
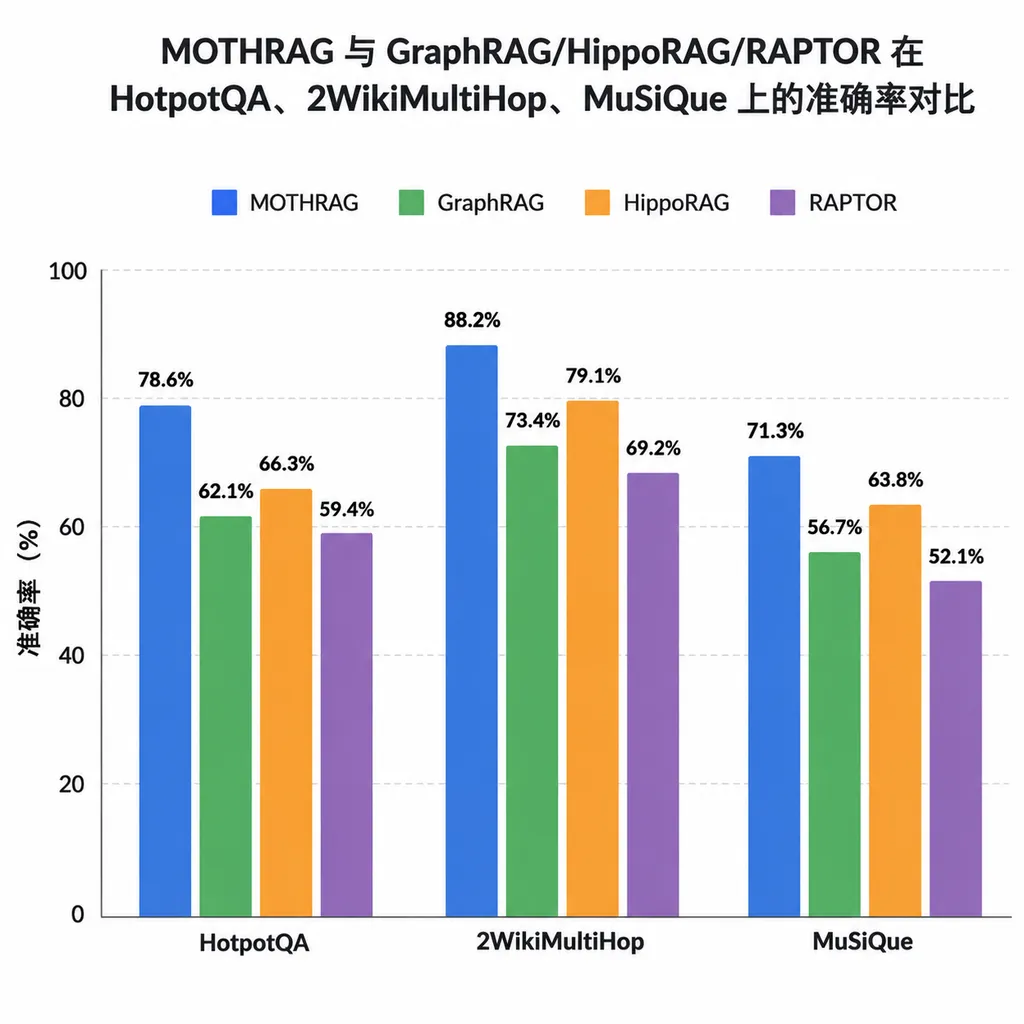
数据先摆出来
作者放出的对比表(Accuracy/F1 综合分):
| Benchmark | MOTHRAG | GraphRAG | HippoRAG | RAPTOR | |---|---|---|---|---| | HotpotQA | 78.1 | 68.6 | 75.5 | 69.5 | | 2WikiMultiHopQA | 76.3 | 58.6 | 71.0 | 52.1 | | MuSiQue | 50.5 | 38.5 | 48.6 | 28.9 |
三个数据集全部第一,其中 2WikiMultiHop 领先 GraphRAG 将近 18 个点,MuSiQue 领先 12 个点,HotpotQA 领先 GraphRAG 接近 10 个点。这不是那种"我微调了一下超参赢 0.5"的胜利,是路线之争级别的碾压。
更关键的是,HippoRAG 才是 GraphRAG 系里当前的 SOTA,MOTHRAG 在 HippoRAG 之上还有 2.6–5.3 个点的优势。所以这不是拿一个过时基线撑门面。
为什么可以不要图?先说说图到底解决了什么
要理解 MOTHRAG 为什么能省掉图,先得看清 GraphRAG 那一派到底在解决什么问题。
传统向量 RAG 的瓶颈在于:分块之后,跨文档的实体关系就被切碎了。你检索到 chunk A 说"公司 X 大量投资 AI 基础设施",检索到 chunk B 说"AI 基础设施面临监管风险",模型没有任何机制知道这两条能连起来。GraphRAG 的做法是提前把"X → 投资 → AI 基础设施 → 面临 → 监管风险"这条链路显式建成图边,查询时在图上做多跳遍历。
代价是什么?
- 索引成本:微软原版方案索引一份大型企业语料动辄几百到几万美元
- 更新噩梦:改一条数据,理论上要重跑抽取和社区检测
- 抽取质量瓶颈:关系抽取用 spaCy 便宜但粗糙,用 LLM 精确但贵,两难
- 简单查询反而变差:图遍历带的边缘上下文会污染语义搜索
MOTHRAG 的思路是:多跳推理的"结构",不一定要预先物化成图,可以在查询时临时组织出来。
查询时编排(Query-Time Orchestration)到底是什么
这是 MOTHRAG 的核心。它把"多跳"这个动作从索引时挪到了查询时,用 LLM 做检索控制器(不是做嵌入、不是做抽取,就是做"下一步该搜什么"的决策器)。
可以把它理解成一个循环:
- 初始检索:把用户 query 走稠密向量检索,拿到 top-k 候选文档
- 信息缺口判断:让 LLM 看当前上下文,判断"要回答这个问题,我还缺什么信息"
- 子查询生成:根据缺口生成下一跳查询(可能是实体扩展、可能是时间约束、可能是关系反向查找)
- 再检索 → 再判断:重复 2-3,直到 LLM 认为证据链闭合
- 答案合成:用聚合的上下文生成最终答案
听起来是不是很像 Agent?没错,但重点在于——它绕开了图这个中间产物。图本质上是把"实体-关系"这层结构化知识预先物化下来,MOTHRAG 的做法是相信 LLM 有能力在查询时即时推断出这层结构,只要你把候选证据喂得足够到位。
这背后的一个隐含判断是:2025 年这一批模型的推理能力,已经足够在 query-time 承担 GraphRAG 用离线图承担的关系推断任务。三年前这条路走不通,因为模型太笨;今天走得通,是因为 GPT-4o、Claude Sonnet 4.5、Gemini 2.5 这批模型的 in-context 推理已经足够撑起这种编排。
索引侧:一个普通到不能再普通的稠密索引
作者原话是 "graph-free dense index",翻译过来就是——就是个普通向量库。没有实体抽取、没有关系抽取、没有 Leiden 社区检测、没有摘要层级、没有 GPU。
这意味着:
- 更新成本 = 嵌入新文档 + append。语料每天变都无所谓
- 可以跑在任何 managed vector DB 上,Pinecone、Qdrant、Milvus、pgvector 都行
- 冷启动几乎为零,10 万篇文档几十分钟就能上线
对比一下:微软 GraphRAG 索引 10 万篇文档,光 LLM 调用费轻松破千美元,跑上一整天。LazyGraphRAG 好一点但每次查询要多 2-8 秒延迟。MOTHRAG 是把这两个成本都压到最低。

为什么 2Wiki 和 MuSiQue 领先幅度更大
看那张表会发现一个有意思的细节:MOTHRAG 在 HotpotQA 上领先 GraphRAG 大约 10 个点,但在 2WikiMultiHop 和 MuSiQue 上领先 12-18 个点。
这不是巧合。HotpotQA 的多跳大多是 2-hop,问题相对干净;2Wiki 和 MuSiQue 有更多 3-hop、4-hop 的组合,还带很多干扰项。GraphRAG 这类系统在深度多跳上有个隐藏问题——图遍历路径会指数级膨胀,社区摘要要么给不到细节,要么给太多噪声。而查询时编排是自适应的:LLM 觉得够了就停,觉得不够就再问一跳,天然对可变跳数友好。
这也解释了为什么 MOTHRAG 在最难的 MuSiQue(50.5)比 RAPTOR(28.9)高出 21 个点——RAPTOR 那种分层摘要在长跳链上信息损耗特别严重。
这套东西什么时候用、什么时候别用
先泼冷水。MOTHRAG 不是银弹,几个明显的适用边界:
适合的场景:
- 语料高频更新(金融、新闻、工单、监控日志)
- 预算敏感,不想为索引花大钱
- 团队没有图数据库运维能力
- 查询以多跳事实问答为主
不适合的场景:
- 需要"全局综合"的问题,比如"请总结这 5000 份年报的整体趋势"——这种问题 GraphRAG 的社区摘要还是有结构性优势
- 对延迟极度敏感的场景。查询时编排意味着每个 query 要多轮 LLM 调用,端到端延迟可能 3-10 秒
- 需要可解释的关系路径展示给用户看(图天然可视化,编排轨迹不好看)
还有一个成本口子要提醒:索引省下来的钱,会部分转移到查询侧的 LLM 调用。如果 QPS 高,这笔账要重新算。MOTHRAG 的经济性甜蜜点是"更新频繁 + 查询量中等"的场景。
工程落地:需要注意什么
如果打算真的把 MOTHRAG 接到自己的系统里,有几个坑作者没细说但可以预判:
-
编排控制器选什么模型。太弱的模型判断信息缺口会偏,太贵又扛不住 QPS。实测 GPT-4o-mini、Claude Haiku 4.5 这个档位的性价比最合适。像 OpenAI Hub 这种多模型聚合平台可以方便地切模型跑 A/B,看哪个在你的数据上编排效率最高。
-
循环终止条件。LLM 判断"证据够了"这件事不总是可靠,需要加最大跳数硬限制(建议 4-5 跳封顶)+ token 预算保护。
-
稠密索引本身的召回率。MOTHRAG 的整体表现依赖底层检索器把"该出现的候选"至少捞到 top-50,如果 recall@50 都低于 70%,编排再聪明也救不回来。建议先用 BGE-M3 或 E5-Mistral 这种强 embedder 打底,混合稀疏检索会更稳。
-
cache 策略。同一批查询往往会触发相似的子查询,一个语义级的子查询缓存能大幅省钱。这是 GraphRAG 没有的红利。
一个更大的判断:RAG 的重心正在从索引侧滑向查询侧
MOTHRAG 不是孤立现象。往回看这一年多的 RAG 演进:
- 2024 上半年,大家在拼索引结构:GraphRAG、HippoRAG、RAPTOR、层次化摘要
- 2024 下半年,开始有人往查询侧挪:Self-RAG、Adaptive-RAG、Corrective-RAG
- 2025 至今,Agentic Retrieval、LazyGraphRAG、以及现在的 MOTHRAG,几乎都在把"聪明"从离线搬到在线
这个方向的物理逻辑其实很清楚:模型越强,离线预处理的边际收益就越低。当模型能在 in-context 里干很多以前要靠图结构才能干的事,你还非要建图,就是在为过时的模型能力付冗余成本。
GraphRAG 会消失吗?短期不会——全局综合、可视化、审计留痕这些需求图仍然是最优解。但"多跳 QA 必须建图"这个共识,被 MOTHRAG 撕开了一个大口子。
项目已经在 Reddit r/MachineLearning 板块开源,代码库对接的是标准商用 API,没有任何本地模型强依赖。想验证自家数据上是否复现的团队,最快一个下午就能跑通端到端。
参考来源
- Moth-Retrieval: Graph-Free Multi-Hop Retrieval via Query-Time Orchestration - Reddit:MOTHRAG 作者的原始发布贴,含基准数据和技术说明
- GraphRAG:用知识图谱与生成式AI开创关系感知的智能新时代 - 知乎:GraphRAG 技术体系的中文综述


