Kimi K2.7 Code 挤进 GitHub Copilot,国产模型第一次拿到主流 IDE 的分发位

GitHub 于 7 月 1 日宣布 Moonshot 的 Kimi K2.7 Code 正式在 Copilot 中 GA 上线,成为首个进入 Copilot 模型选择器的国产编程模型。这既是 Moonshot 的一个里程碑,也意味着 Copilot 的模型池正在从"OpenAI + Anthropic 双寡头"变成一个真正开放的货架。
GitHub 在 7 月 1 日更新的 Changelog 里,用一行不太起眼的标题官宣了一件事:Kimi K2.7 Code 在 Copilot 中正式 GA。没有发布会,没有联合海报,就是一条常规产品更新。但这条更新的分量,比它出现的方式要重得多。
这是第一个进入 GitHub Copilot 模型选择器、面向全体付费用户开放的中国大模型。此前 Copilot 的模型池里坐着的是 GPT 系列、Claude Sonnet/Opus、Gemini,以及少量 xAI 的模型。Moonshot 这次是直接坐上了主桌,而不是通过某个第三方 provider 的插件旁路进来的。
一个安静的官宣,一场并不安静的位次变化
对开发者来说,最直观的变化是:打开 VS Code、JetBrains 或者 Copilot Chat 的模型下拉框,Kimi K2.7 Code 现在和 Claude Sonnet 4、GPT-5.1、Gemini 3 Pro 并列出现。Agent Mode、Edit Mode、代码补全,都能切过去用。企业版和 Business 版可以由管理员在策略里统一放开。
这个"位次"意味着什么,做过分发的人心里都清楚。Copilot 目前是全球开发者渗透率最高的编程助手,付费席位数以千万计。进入它的默认模型池,等同于拿到一个不用自己搭 IDE 生态、不用自己去教育用户切工具的分发通道。过去两年,国产模型不是没能力,是没这个位置。DeepSeek、Qwen、GLM 都在开源榜单上刷过高分,但真要在开发者日常工作流里被"顺手点开",还得靠自建插件或者第三方客户端。
Moonshot 这次是跳过了那一层。
K2.7 Code 到底是个什么模型
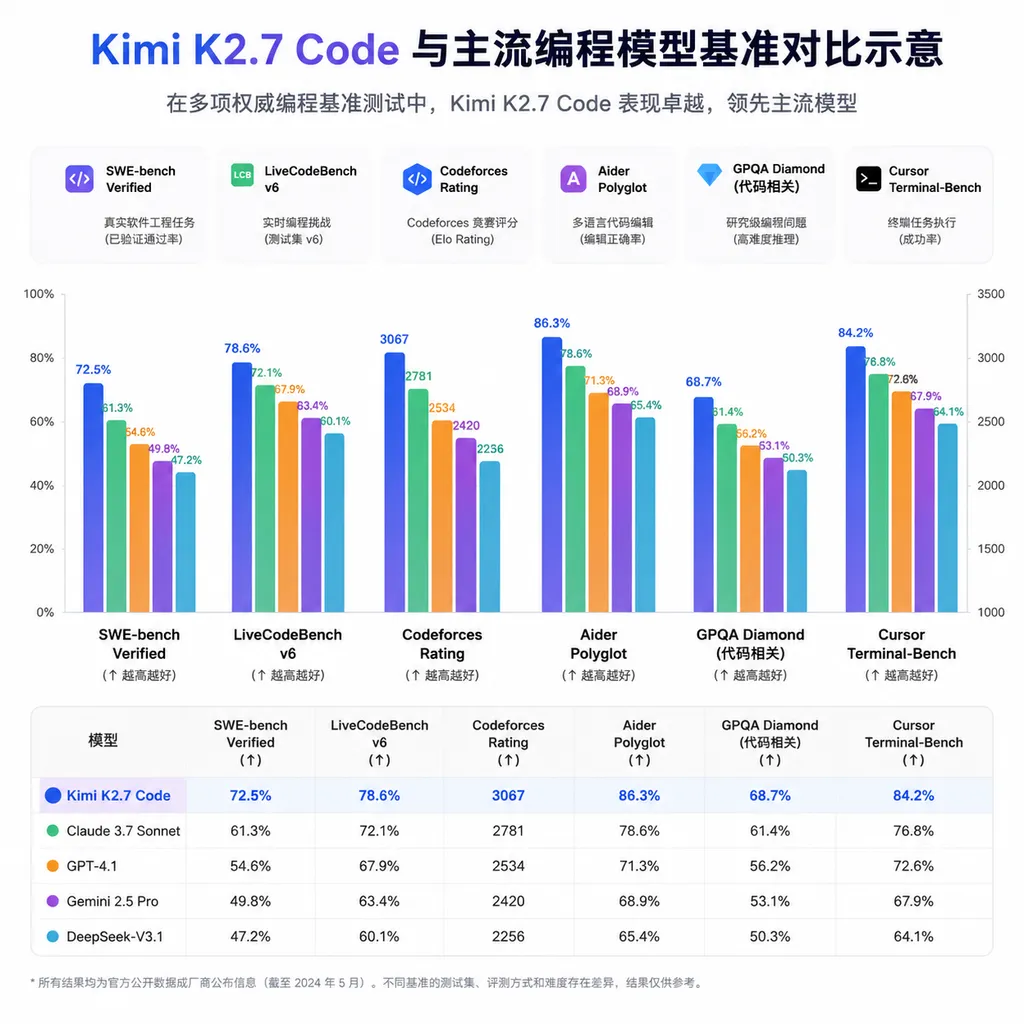
回到模型本身。Kimi K2.7 Code 是 Moonshot 在 6 月 15 日发布的一个专门面向编程和 Agent 任务的版本,架构上延续了 K2 系列的 MoE 路线:1 万亿总参数、320 亿激活参数,256K 上下文窗口。License 是 Modified MIT,权重开放下载,Hugging Face 和 GitHub 都能拿到。
和上一代 K2.6 相比,K2.7 Code 在三件事上做了明显调整:
- Kimi Code Bench v2 从 50.9 提到了 62.0,涨幅超过 21%
- SWE-Bench Verified 从 48.3 到 53.6
- Multi-SWE-Bench Lite 从 26.7 拉到 35.1,这是幅度最大的一项
但比分数更值得关注的是另一个数字:平均 token 消耗下降 30%。Moonshot 官方给的解释是"改善了长程任务中的过度思考倾向"。翻译成人话就是——K2.6 那个版本思考链太长,一个中等复杂度的任务能给你思考出几千 token 的推理过程,看着聪明,跑起来又慢又贵。K2.7 Code 把这条链压短了,但基准分反而涨了。
这在推理模型这一波里其实不算常见。多数厂商是靠"多想一点"换分数,Moonshot 这次是"想得更准"换到的分数。对 Agent 场景尤其重要,因为 Agent 任务本质上是多轮工具调用,每一轮多花 30% token,累计到十几轮就是几倍的成本差距。
还有一点要提前说明:K2.7 Code 只有 thinking 模式,没有非 thinking 模式。这和 GPT-5、Claude Sonnet 4 那种"可选是否思考"的双模式设计不一样。你调它,就是每次都会走推理链。这决定了它更适合处理复杂任务,做代码补全那种毫秒级响应就不合适。GitHub 把它接入 Agent Mode 和 Edit Mode,其实也是踩着这个特性来的——补全用不到它,长任务才用得上它。
为什么 Copilot 要收一个国产模型
从 GitHub 的视角看,这件事的逻辑并不难猜。
Copilot 过去一年在做一件事:把自己从"Copilot = OpenAI"这个绑定关系里拆出来。去年接入 Claude,年初接入 Gemini,年中接入 xAI,路径非常清晰——它要变成一个多模型的分发平台,而不是某一家模型公司的前端。
这个策略的动机也很务实。一是议价权,Copilot 的用户量足够大之后,它需要在模型供应侧有筹码;二是场景,代码任务在各家模型上表现差异很大,Claude 在 refactor 上强,GPT 在 debug 上稳,Kimi 在长上下文任务上有优势,用户切换模型的需求是真实存在的;三是 Agent 化之后,token 消耗会指数级上升,成本结构必须要有多个供应商可选。
K2.7 Code 恰好卡在几个卖点上:开源权重、256K 上下文、token 消耗低、编程分数不输一线。对 GitHub 来说,接一个能打的、有价格弹性的、还带开源属性的选项,几乎没有拒绝的理由。
对国内开发者意味着什么
这里有一个必须要说的现实问题:GitHub Copilot 在国内的支付和网络体验一直不算顺畅,很多团队用的是替代方案,或者 Cursor、Continue、Cline、Roo Code 这类第三方客户端搭配自选模型。所以"K2.7 Code 进 Copilot"这件事,对国内团队来说是间接受益——它证明了模型的能力被主流平台背书,但真要用起来,还是要看能不能拿到稳定、便宜、直连的 API。
这也是最近半年国内 AI 基础设施赛道最热闹的一块。PPIO 在 6 月 15 日模型一发布的当天就首发上线了 K2.7 Code,Moonshot 官方平台也开放了 API。像 OpenAI Hub 这类聚合平台目前也已经把 K2.7 Code 接进了统一的模型池,一套 OpenAI 兼容的 Key 可以同时调 K2.7 Code、Claude、GPT、Gemini、DeepSeek,国内直连,切模型不用改代码——这对同时在测多个编程模型的团队来说,比自己去每家申请账号、拉专线要省事得多。
对个人开发者而言,实际的选择路径大致是这样:
- 如果你的主要 IDE 是 VS Code 或 JetBrains,且能用 Copilot:直接在模型选择器里切到 Kimi K2.7 Code,用 Copilot 的额度
- 如果你用 Cursor / Cline / Roo Code / Claude Code 这类第三方客户端:拿一个 OpenAI 兼容的 API endpoint 填进去就能用,Moonshot 官方文档里就明确写了 K2 系列如何在 Claude Code、Roo Code、Cline 里配置
- 如果你是团队场景、需要审计和多模型对比:用聚合平台的统一入口更容易做成本控制
一个更长期的信号
如果只把这件事看成"又一个模型上了 Copilot",就低估它了。
过去两年,国产大模型在 benchmark 上追得很凶,但真正的问题从来不是分数,而是分发。一个模型再强,如果开发者要专门装插件、专门改工具链、专门去某个网页调,就永远只能在早期尝鲜圈里流转,进不了主流工作流。GitHub Copilot 是全球最大的开发者工作流入口之一,Kimi 这次拿到席位,是国产模型在"被日常使用"这条路上第一次真正跨过分发这一关。
再往前看,Anthropic 的 Claude Code、字节的 Trae、Cursor 的模型自选、Cline 和 Roo Code 这些开源 Agent 框架,都在明确走"多模型可切换"的路。这个趋势的另一面是:模型层的品牌壁垒在变薄,开发者对"哪家的模型"越来越无感,只关心哪个跑当前这个任务更快、更便宜、结果更好。当模型变成可插拔组件,分发渠道和推理服务的重要性反而在上升。
Moonshot 显然想通了这一点。K2.7 Code 从发布到进 Copilot,中间只隔了半个月。这种节奏说明它不是靠单点突破——是模型、License、API 服务、渠道合作被当成一整套东西来做的。开源、成本可控、能力对标一线、被主流平台收录,这四件事凑齐了,Kimi 就从"一个 benchmark 上不错的国产模型"变成了"一个可以被认真放进技术选型表里的选项"。
对整个国产模型阵营来说,这个案例的价值在于——它证明了这条路能走通。DeepSeek、Qwen、GLM 后面会不会跟进 Copilot、Cursor 这类平台,是接下来几个月值得盯的事。至少目前看,Kimi 走了先手。
参考来源
- Kimi K2 官方 GitHub 仓库:Moonshot AI 发布的 Kimi K2 系列开源代码库,包含 K2.7 Code 的模型说明、评测结果与部署指南
- Reddit 上关于 Kimi K2.7 Code 的开发者讨论:LLMDevs 社区对 K2.7 Code 基准分数、token 消耗和实际使用体验的讨论


