AReaL 2.0 开源:给 Agent 装上在线学习闭环

蚂蚁、清华、港科大联合项目 AReaL 于 7 月 2 日发布 2.0 版本,把强化学习基础设施做成微服务,让已上线的 Agent 能直接把真实交互轨迹喂回训练流程,试图解决 Agent 部署即冻结这个老问题。
7 月 2 日,开源强化学习基础设施 AReaL 正式发布 2.0 版本。这次升级把问题的边界从「怎么高效训练一个 Agent」推到了「一个已经在跑的 Agent 怎么继续学习」——听起来只差一个字,工程量差了不止一个数量级。
熟悉这个项目的读者应该记得,AReaL v1.0 是今年 3 月发的,主打大规模异步 RL 训练和 Agent 一键接入。v2.0 的重心明显换了地方:不再纠结于训练环节本身有多快,而是直面 Agent 落地后最尴尬的一个现实——每天都在干活,却学不到东西。

Agent 上线之后就冻结了,这是个真问题
过去一年,Agent 已经真真切切进了生产环境。企业里用它写代码、查资料、调工具、跑流程,任务越来越复杂。但一个略显讽刺的现象是:这些 Agent 每天产生海量交互数据——哪些工具调用失败了、用户为什么改口、哪一步规划走偏了——这些经验绝大多数只是被写进日志,然后就没有然后了。
以往想让 Agent 变强,标准操作是这样:人工构造训练数据 → 离线跑一轮 RL → 重新部署上线。中间环节多、周期长,而且离线仿真环境和线上真实业务之间总有 gap。代码库更新了、流程调了、内部工具接口改了,Agent 还停留在上次训练时对世界的理解上。
AReaL 团队在技术报告里的判断挺直接:自演进 Agent 的瓶颈既不完全在模型本身,也不完全在 RL 算法,而是缺一套服务于真实 Agent 的在线 RL 基础设施。这个判断我基本认同——现在开源社区里 RL 训练框架不少,但绝大多数是给研究者跑 benchmark 用的,离生产环境的假设差得远。
核心思路:把 RL 基础设施改造成微服务
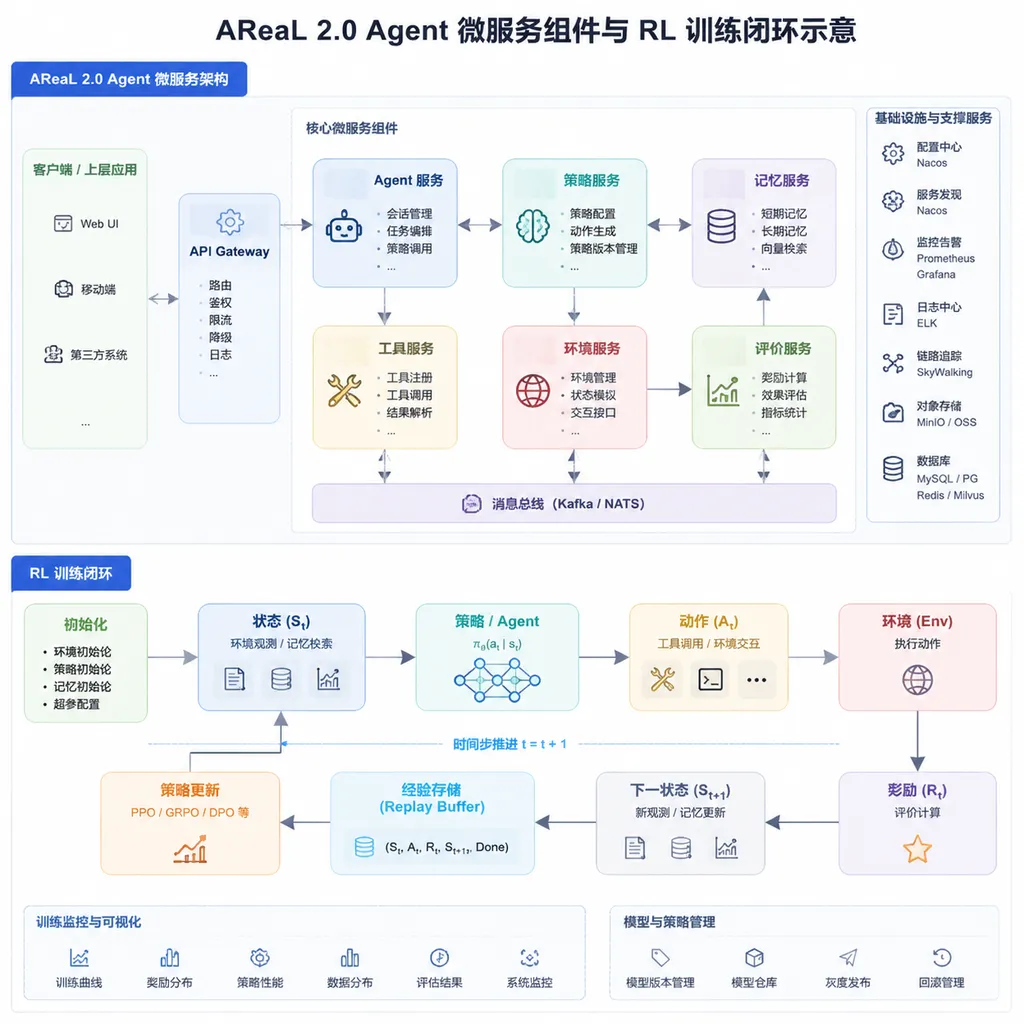
AReaL 2.0 的做法可以一句话说完:把原本服务于 Rollout 和训练的计算单元,重组成可部署、可接入、可替换的 Agent-compute 微服务组件。
翻译一下就是——你不用重写你的 Agent,也不用把业务系统推倒重来。只要把 Agent 原来发给大模型的推理请求,改指向 AReaL 2.0 管理的推理入口,剩下的事情它在后台接管:会话式交互记录、轨迹采集、奖励绑定、异步训练全流程串起来。
这个设计上的选择挺聪明。业内很多做 Agentic RL 的方案,要么让开发者把线上 Agent 抽象成一个离线仿真任务重新跑,要么要求接入方按训练框架的规范重写 Agent loop。前者训出来的东西在真实环境里未必好用,后者的迁移成本足以劝退大部分企业开发者。AReaL 2.0 选择在推理入口这一层做统一切面,最大限度地保留原有 Agent 的规划、工具调用、沙箱和记忆模块,我觉得这更符合工程直觉。
三根支柱:ATDP、Data Proxy、Evolution Control Plane
技术报告里,AReaL 2.0 把自演进 Agent 系统抽象成三个模块:
- Agent Trajectory Data Protocol(ATDP):定义「应该记录什么」。多轮对话、工具调用、执行结果、奖励信号,都要有统一的结构化描述,才能被后续训练流程消费。
- Agentic Data Proxy:解决「在真实生产系统里如何记录」。这一层重点考虑权限控制、数据脱敏、隔离、审计——因为企业里 Agent 摸到的可能是代码库、客户信息、内部系统,训练数据不能随便流。
- Agent Evolution Control Plane:负责在线策略更新和整体调度。
三个模块里,我认为 Data Proxy 是最有产业价值也最容易被忽视的一块。学术界的 Agentic RL 工作大多默认数据可以自由流动,但真到企业场景里,一个 Agent 的训练链路能不能落地,往往不是算法说了算,而是数据合规团队说了算。AReaL 2.0 提前把这层做进架构里,这一点做得比大部分同类项目务实。
团队自己也承认,AReaL 2.0 并没有做出完整的自演进智能体基座,而是选了「基于真实部署轨迹的在线策略模型更新」这条最有代表性的路径先切进去。这种边界感反而让 2.0 的定位更清晰。
从 Hermes 到 Claude Code:两套可复用范例
光讲架构容易空。AReaL 2.0 这次给了两个可跑通的例子。
Hermes Agent 范例演示的是接入方式。Hermes 照常接任务、规划、调模型,AReaL 2.0 在后台记录关键交互过程,结合任务结束后的反馈信号,把真实轨迹拿去做后续训练。开发者要复用,把 Hermes 换成自己的 Agent 和任务环境,接入范式是一样的。
Claude Code Agent RL 范例则接近端到端的软件工程智能体训练参考,覆盖数据处理、Agent Infra 建设、算法训练全链路。对做 Coding Agent 的团队来说,这套东西比重新造轮子省事得多。
两个例子的代码都放在 GitHub 仓库的 examples/ 目录下:
examples/hermes—— Hermes Agent 在线 RL 接入示例examples/swe—— Claude Code 方向的软件工程 Agent 训练示例
可复用性是这次 2.0 版本最实在的卖点。之前做 Agentic RL 的团队大多在重复造相似的轮子——数据采集、轨迹存储、奖励对齐、异步训练——这些工程活儿谁都得干一遍。AReaL 2.0 把这套东西微服务化开源出来,某种程度上降低了行业整体的重复劳动。
项目现在归谁管,生态怎么样
AReaL 项目 2024 年由蚂蚁集团、清华大学、香港科技大学等团队发起,主力研究者包括前 OpenAI 研究员、清华交叉信息院的吴翼团队。今年 5 月,AReaL 从蚂蚁 InclusionAI 孵化独立出来,成为独立开源社区,并加入了 PyTorch Foundation Ecosystem 项目。
独立之后,社区伙伴陆续加入,目前公开可见的合作方包括华为云团队、MindLab 等。团队后续路线图里提到了三个方向:在线强化学习继续深挖、自动化评估、多模态智能体训练。第三个方向估计会是 3.0 版本的重点。
对开发者意味着什么
如果你正在构建生产环境的 Agent 应用,AReaL 2.0 至少提供了两件事:
- 一套可以直接用的在线 RL 基础设施。不需要自己去搭 Rollout Worker、异步训练调度、轨迹管理这些底层的东西。
- 一种把线上真实数据转化为模型能力的工程范式。以往这部分要么闭源在头部大厂内部,要么散落在各个论文的实验代码里,很难拼成一套完整可跑的东西。
当然它不是万能的。首先,跑起来还是需要一定的计算资源,中小团队真要做在线 RL,成本账要算清楚。其次,能不能训出效果,很大程度取决于奖励信号设计得好不好——这个部分 AReaL 2.0 帮不上太多忙,属于业务方自己的活儿。
对底层模型的选择也是开放的。AReaL 2.0 训的是策略模型,开发者可以选自己想优化的 base model。如果只是想快速验证 Agent 的推理链路而不训练底层模型,用 OpenAI Hub 这类聚合平台先把 GPT、Claude、Gemini、DeepSeek 都跑一遍对比,再决定拿哪个做 RL 微调基座,也是一条务实的路径。
一点判断
过去两年 Agent 领域一直有个心照不宣的尴尬——大家都在讲 Agent 会「自演进」、会「越用越强」,但产品真正上线之后基本都是静态的。AReaL 2.0 未必能一次性解决这个问题,但它至少把话题从 PPT 层面拉回了工程层面:Agent 的持续学习不是一个概念,而是一个由推理入口、轨迹协议、数据代理、异步训练组成的具体系统问题。
对国内开源社区而言,能在 RL 基础设施这个偏底层、偏基础的方向上做出一个进入 PyTorch Foundation Ecosystem 的项目,本身也是件不常见的事。接下来值得盯的,是社区能不能围绕 ATDP 这套协议吸引更多 Agent 框架接入——只有生态起来了,「自演进 Agent」才算真的有了工程基础。
参考来源
- AReaL 项目 GitHub 仓库 —— 项目主页,包含 2.0 版本代码、技术报告和 Hermes、SWE 两套接入示例
- 让 Agent 越用越强:AReaL 2.0 开源给智能体装上「成长系统」(掘金) —— 中文技术社区对 2.0 版本的详细解读,覆盖设计思路和企业场景适配


