一张 3080 跑 15 小时:独立开发者从零手搓 216M 参数 LLM

一位独立开发者在 Reddit 晒出自己完全从零实现的 216M 参数小型语言模型,单卡 RTX 3080 训练 15 小时,Attention、RoPE、SwiGLU 全部手写,没调用任何 HuggingFace 现成模块。
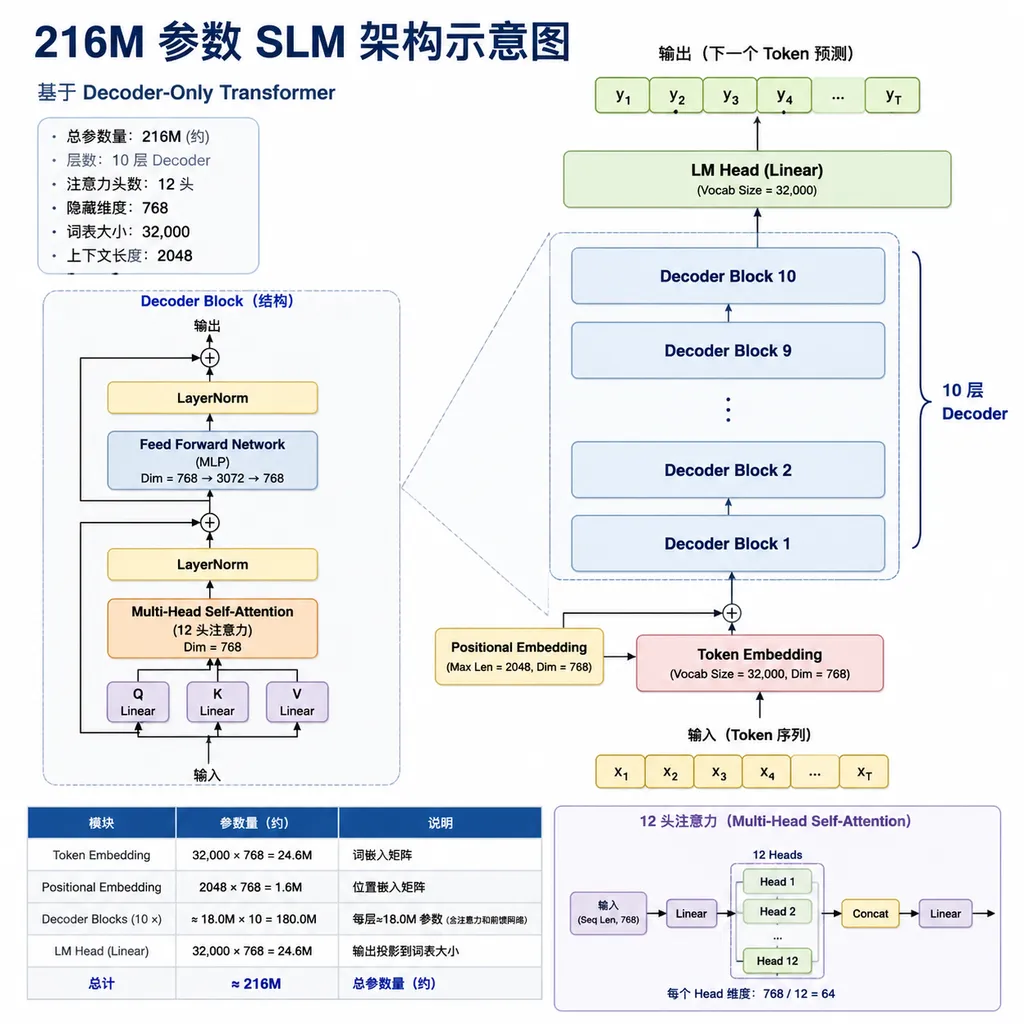
上周末,Reddit 的 r/MachineLearning 版面出现了一个不太起眼但技术含量拉满的帖子。一位独立开发者晒出了自己完全从零实现的小型语言模型——216.5M 参数,10 层 Decoder,单张 RTX 3080 跑了 15 小时训完,从 Tokenizer 到 Attention 全部手写。
在这个动辄千亿参数、动辄几千张 H100 的时代,这条消息本来不该引起什么波澜。但仔细看完他贴出来的架构细节和训练配置后,你会发现,这可能是最近这段时间最值得开发者认真读一遍的 "教科书级" 复现案例。
不是套壳,是真的从零
先把话说清楚——市面上号称 "从零训练" 的项目一抓一大把,但绝大多数都是拿 HuggingFace 的 AutoModelForCausalLM 换个配置文件,或者 fork 一份 nanoGPT 改改超参。这次这位开发者不一样,他连 Attention 层都是自己实现的。
看一下他给出的架构清单:
- 参数量:216.5M
- 层数:10 层
- 注意力:12 头多头自注意力,RoPE 位置编码,SDPA 加速
- 结构:Decoder-only,Pre-Norm,RMSNorm + SwiGLU,输入输出 embedding 共享
- 隐藏维度:1032,head_dim 86,FFN 中间层 4416
- Tokenizer:自训的 36k SentencePiece unigram,保留大小写,byte-fallback,带聊天角色和记忆的特殊 token
- 上下文长度:768
这套配置基本就是把 LLaMA 系列的现代 Decoder 最佳实践在小模型上完整复刻了一遍。RMSNorm 比 LayerNorm 快、SwiGLU 比 ReLU 表达力强、RoPE 比学习式位置编码泛化性好、tied embedding 省参数——每一个选择都不是拍脑袋定的,都是过去两年被反复验证过的最优解。
特别值得一提的是 hidden 1032、head_dim 86 这组数字。1032 不是 2 的幂,86 也不是。这说明作者不是照抄某个开源模型的配置,而是在 10GB 显存的硬约束下,自己算过参数量、算过 attention 的显存占用之后精挑细选的。做过训练调优的人应该都懂,这种非常规的维度选择往往是被显存卡出来的产物。
训练配置:把 3080 的每一 GB 都榨干
更有意思的是训练配置。单张 RTX 3080,10GB 显存,bf16 精度,15 小时训完。
具体的数字是这样的:
- 数据量:约 5.51 亿 token
- 优化器:AdamW,β 0.9/0.95
- 学习率:3e-4,1000 步 warmup
- weight decay:0.1
- 梯度裁剪:1.0
- 有效 batch size:16384 tokens/step(micro batch 4 × grad accum 8 × seq 512)
- 总步数:33650 步
注意这里的关键细节:micro batch 只有 4,序列长度训练时压到 512(推理时可以到 768),靠 gradient accumulation 累到 8 步凑出 16384 token 的等效 batch。这是典型的 "显存不够梯度累加凑" 的操作,也是消费级显卡训 LLM 的唯一活路。
β2 用 0.95 而不是 Adam 默认的 0.999,这是 GPT-3 论文里的经典配方,对训练大模型的稳定性有帮助。3e-4 的学习率配 1k warmup 也是老配方了,说明作者读过不少 paper,不是随手试出来的。
算一下数据配比:551M token 对应 216M 参数,token/参数比大概是 2.5:1。这个比例远低于 Chinchilla 定律建议的 20:1,属于严重欠训练。但对于一个测试性质、目标是验证架构正确性的项目来说,够用了——训练目的是让 loss 收敛、让模型能说人话,不是刷 benchmark。
数据集选得很讲究
数据配比方面,预训练用了 Wikipedia、TinyStories、OpenWebText2 三大件。TinyStories 是微软出的合成简单故事数据集,专门用来训小模型的,能让 100M 级别的模型学会讲流畅的英语——这个选择说明作者非常清楚小模型该喂什么。
SFT 阶段就更看得出功力了:
- SmolTalk:HuggingFace 的 SmolLM 团队专门为小模型策划的对话数据
- UltraChat:清华出的高质量多轮对话数据集
- Magpie:从对齐模型里 "钓" 出来的指令数据,质量很高
- AM-DeepSeek-R1:带推理链的数据,蹭一下 R1 的推理能力
- Orca-Math:数学推理数据
这个组合基本覆盖了小模型 SFT 的所有主流方向:日常对话、多轮交互、指令遵循、推理链、数学。而且都是公开数据集,没有任何合规风险,任何人都能复现。
为什么这件事值得开发者关注
看到这里可能有人要问:现在 Qwen、Llama、Gemma 都开源了这么多小模型,性能秒杀这个 216M 的自制品,从零手搓一个还有什么意义?
三个理由。
第一,学习价值无可替代。把 Attention、RoPE、RMSNorm、SwiGLU 从公式推导到 PyTorch 实现完整走一遍,比读一百篇 blog 都管用。国内也有类似的开源项目在做这件事,比如 Datawhale 的 Happy-LLM(同样是 215M 参数级别,覆盖 LLaMA2 结构复现和预训练全流程),还有 wdndev 的 tiny-llm-zh(92M 中文小模型,从 Tokenizer 训练到 llama.cpp 部署全链路打通)。这些项目本质上都是同一个思路——通过一个能在消费级显卡上跑起来的完整案例,把 LLM 的所有关键技术点串起来。
第二,工程约束下的取舍才是真本事。在 8 张 H100 上训模型和在一张 3080 上训模型是两回事。前者你想怎么设计都行,后者每一个决策都是在跟显存、跟时间死磕。这位作者选择 768 上下文、512 训练序列长度、tied embedding,本质上都是在做取舍。想搞垂直领域小模型的团队,这种约束下的经验比大厂那些 "我们用 1024 张卡训了三个月" 的报告有用得多。
第三,SLM 正在成为一个真赛道。看看今年上半年的动向:微软 Phi 系列迭代到了新版本,Google 的 Gemma 3 Nano 主打端侧,苹果的 Apple Intelligence 底层是 3B 级别的模型,HuggingFace 的 SmolLM 系列一路做到 1.7B。 端侧、离线、隐私敏感场景对小模型的需求正在爆发。一个能在 3080 上 15 小时训出来的架构,稍微加加数据、加加参数,就是可以商用的产品原型。
216M 参数的模型到底能干嘛
说点实在的。216M 参数、551M token 训练量,这个规模的模型能做什么、不能做什么?
能做的:
- 简单对话(打招呼、闲聊、格式化回复)
- 短文本分类和意图识别
- 特定 domain 的文本生成(比如 TinyStories 风格的短故事)
- 作为更大模型的 draft model 做投机解码
- 边缘设备上的轻量级 NLP 任务
做不了的:
- 复杂推理
- 长文档理解(context 只有 768)
- 代码生成(数据里没喂)
- 多语言(纯英文语料)
- 事实性问答(551M token 装不下多少世界知识)
作者自己在帖子里也说了,这是个 "test SLM",目的是练手和验证 pipeline,不是要跟谁比性能。这种诚实的态度在当下动辄 "超越 GPT-4" 的开源生态里,反而显得难得。
一个观察
最近一年,从零训 LLM 的门槛在肉眼可见地下降。两年前你要做这件事,光是搞清楚 Attention 怎么写就要啃好几天论文;一年前有了 nanoGPT,但要跑通完整的 SFT pipeline 还是不容易;到了 2026 年,一个独立开发者拿一张 3080,周末两天就能从头训一个能跑通对话的模型。
这背后是整个基础设施的成熟——PyTorch 2.x 的 SDPA 让 Attention 加速开箱即用,bf16 训练稳定性早已不是问题,公开数据集的质量和数量都今非昔比,SentencePiece 这类 tokenizer 训练工具也非常成熟。
对开发者来说,这意味着两件事:
一是知识民主化。以前只有 OpenAI、Google 这种公司的研究员才能玩的 pretraining 游戏,现在任何一个愿意花点时间的工程师都能玩。你不一定要真去训一个模型,但完整走过一遍这个流程,对于理解 LLM 到底在做什么、为什么会出现某些行为,帮助是巨大的。
二是垂直小模型的机会窗口。通用大模型的战争已经打完了,接下来是各种垂直场景的小模型之争。谁能用 100M-1B 参数的模型解决好某个具体问题,谁就能在端侧、在离线、在隐私敏感的赛道上占位。
当然,实际业务中大多数团队还是会选择直接调 API——毕竟自训模型是有门槛的,调优、部署、迭代都是长期投入。对于要快速验证产品想法的开发者,通过 OpenAI Hub 这类聚合平台一个 Key 调 GPT、Claude、Gemini、DeepSeek 全家桶,往往是更务实的选择。等业务模型跑通了、场景收敛了,再考虑要不要蒸馏一个自己的小模型不迟。
写在最后
那个 Reddit 帖子的评论区里,有人问作者:"你为什么要做这个?"
作者的回复很简单:"想看看自己能不能真的从头做出一个能说话的模型。"
这句话让我想起了很多年前,玩单片机的人非要自己写一个 hello world 点亮 LED 才算入门。今天在 LLM 领域,从零训一个能对话的小模型,大概就是新时代的 "点亮 LED"。
技术门槛在降,但对基本功的要求没变。谁能沉下心把 Attention 的每一行代码写明白,谁就能在下一波 AI 应用浪潮里走得更稳。
参考来源
- Reddit 原帖:Looking for feedback on a small test SLM —— 独立开发者发布 216M 参数 SLM 完整架构和训练细节的原始讨论
- tiny-llm-zh 项目 —— 类似思路的中文小参数量 LLM 从零实现项目,覆盖 Tokenizer、预训练到 llama.cpp 部署
- LLM 时代独立开发者 AI 产品全景图 —— 独立开发者在 AI 时代的赛道梳理,可作为背景阅读
- HuggingFace SmolLM Datasets —— 本文提到的 SmolTalk 等专为小模型设计的训练数据集集合


