232M参数的另类玩家:Hierarchos把RNN和记忆槽塞进了小模型

开发者 netcat420 团队开源了一个 232M 参数的循环记忆增强助手模型 Hierarchos,用 RWKV 骨干加分层管理器、可微分记忆槽和后缀自动机的混合架构,证明非 Transformer 路线在小模型上也能跑通指令跟随。
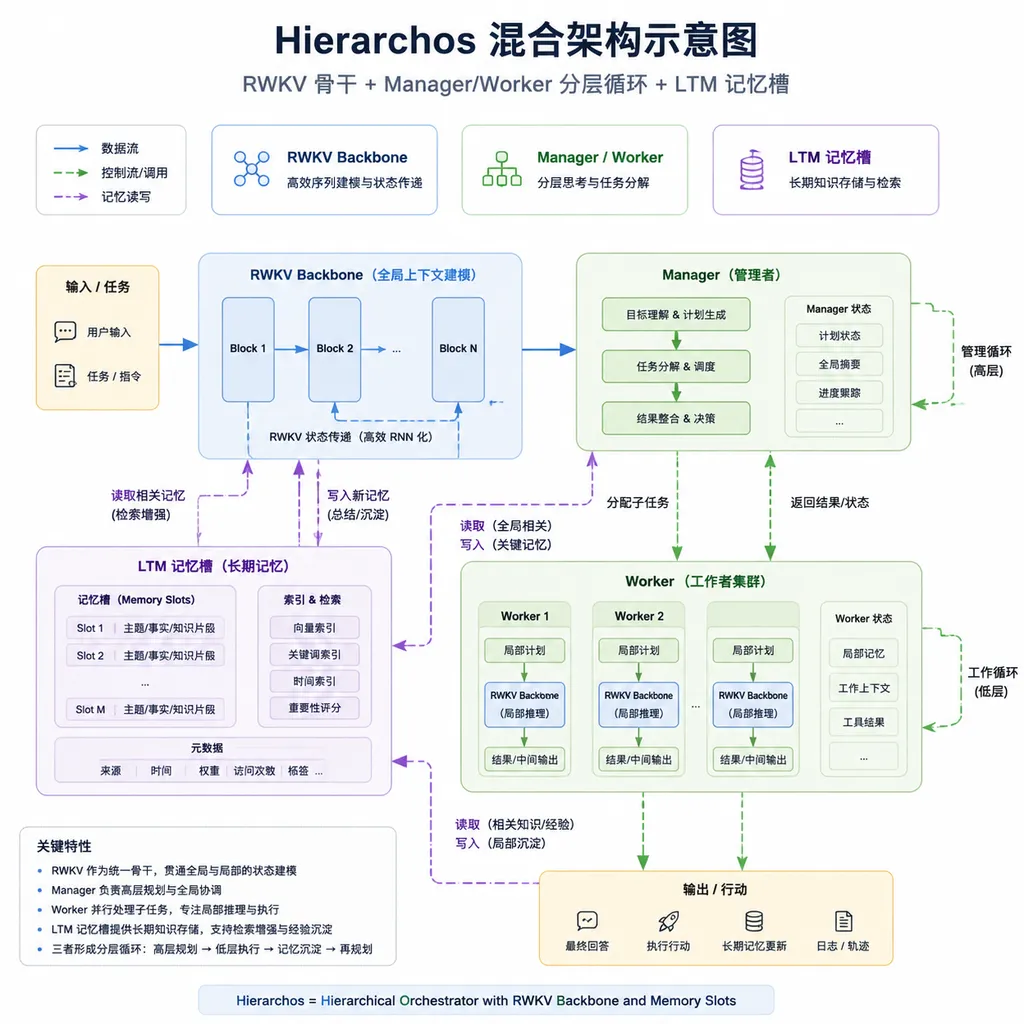
7月2日,一份署名为 Makhi Burroughs(netcat420)、Lost Time 及 Hierarchos 项目组的技术报告贴上了 r/MachineLearning。他们从零训练了一个 232M 参数的模型 Hierarchos,走的不是 Transformer 路线,而是把 RWKV 循环骨干、分层 manager/worker 控制循环、可微分槽式长期记忆(LTM)和一个确定性后缀自动机拼在一起。
这个规模显然不会跟 GPT-3.5 掰手腕,作者自己在 TL;DR 里就先把预期压下来了:不是 GPT-3/3.5 级别的模型,只是证明这套混合架构能跑起来、不会训崩、能维持短指令的连贯性。但把它放到 2026 年这个时间点看,反而有点意思——当所有人都在往万亿参数堆的时候,还有人认真在 232M 的量级上折腾记忆架构。
一个 232M 的模型为什么值得看
先说数字。232M 参数,13 个 epoch,训练硬件是租的一张 RTX 6000 Blackwell 96GB。数据集用的是作者自己整理的 netcat420/Experiment_0.1,Alpaca 格式。这个配置放在今天,基本等同于一个博士生的毕设预算。
但 Hierarchos 想解决的问题不小。它试图回答一个在智能体圈子里被反复讨论、但一直没有干净答案的问题:一个小模型,能不能靠架构上的记忆机制,弥补参数规模上的短板?
过去两年里,关于 AI 智能体记忆的路线其实一直在分叉。北大、复旦几家在 2025 年发的那篇长综述里把它归成了「形态-功能-动态」三维框架,主流做法是外挂 RAG、向量库、图数据库,把记忆当成模型之外的一个服务来做。MemOS 那套思路更进一步,提出「明文记忆-激活记忆-参数记忆」三层,试图像操作系统管内存一样管理智能体的知识状态。EverOS 那种项目则走的是流水线路径,把对话里的事实、事件抽出来落库。
这些方案的共同点是:模型本体基本不动,记忆能力靠外部系统兜底。
Hierarchos 的选择相反。它把记忆机制烧进了架构本身。
架构拆解:四个部件各管一段
报告里把这个模型描述成一个非 Transformer 的混合体,四个核心组件各司其职:
- RWKV 骨干:负责序列建模。RWKV 是这几年一直在小圈子里被讨论的 RNN 变体,训练时能像 Transformer 一样并行,推理时又能像 RNN 一样保持常数级显存。对一个 232M 的模型来说,这个选择很实用,尤其是当你想让模型处理长上下文却又不想被 KV 缓存拖垮显存的时候。
- 分层 manager/worker 循环:这是整个架构里最像「智能体」的部分。manager 负责规划和决定动作,worker 负责具体执行。这种结构在 LLM 智能体框架里不新鲜,但把它直接做进模型内部循环、而不是靠 prompt 拼出来,是另一种玩法。
- 可微分槽式长期记忆:这是 Hierarchos 的关键差异化点。LTM 用一组可学习的记忆槽实现,读写操作全部可微分,梯度能穿过记忆访问反传回参数。这跟外挂向量库有本质区别,向量库的检索是不可微的,模型学不到「怎么用记忆」这件事,只能学「怎么把 query 编好」。
- 确定性后缀自动机:这一部分最反直觉。在一个几乎全是软性、连续、可微组件的架构里,作者硬塞了一个确定性的后缀自动机。它的作用大概率是做精确匹配和检索加速,用来补神经组件在精确回忆上的短板。这种「神经网络里嵌个符号结构」的做法过去两年在 retrieval-augmented 方向零星有人尝试,但落到小模型里比较少见。
把这四样东西塞进 232M 参数里,还能训到不崩,本身就是工程上的活儿。
报告里最诚实的部分:踩坑清单
技术报告最有价值的往往不是架构图,而是「我们踩了什么坑」。Hierarchos 在 TL;DR 里就把这句话讲得很直白:
Most of our breakthroughs came from fixing subtle train/inference parity mismatches and numerical stability bugs.
翻译过来就是:大多数进展不是来自模型设计的高光时刻,而是来自把训练和推理阶段的行为对齐、修各种数值稳定性 bug。
这个坦白值得给个赞。在混合架构里,train/inference parity 是隐形杀手。RNN 类模型在训练时通常用 teacher forcing 或者并行化路径,推理时是纯自回归——两个路径的数值行为如果对不上,训练指标看着好看,实际部署就是另一回事。加上分层 manager/worker 的控制流、加上可微分记忆的读写、加上后缀自动机的确定性分支,一个组件的小错位就能让整个系统在推理时莫名其妙地跑偏。
作者说他们「survive training, avoid collapse, and maintain short-form instruction coherence」。这三个词都是有分量的——训崩、模式坍塌、指令跟随失效,是小模型常见的三种死法,Hierarchos 都躲过了。但请注意「short-form」这个限定词,它坦率地告诉你:长文本生成、复杂推理,目前还不是这个模型能覆盖的场景。
跟主流路线比,Hierarchos 押在哪
把 Hierarchos 放在 2026 年上半年这个坐标系里看,它其实是在赌几件事:
第一,赌小模型 + 强架构的性价比曲线还没被吃完。 现在大多数公司做智能体的路径是「拿一个足够大的通用模型 + 加 RAG + 加工具调用」,成本高、延迟高、但工程门槛低。Hierarchos 押的是反面:从架构上给小模型加记忆能力,让 200M 级别的模型也能承担一部分需要状态维持的任务,比如个人助手、边缘设备上的持续对话。
第二,赌 RNN 路线在推理成本上的优势会重新变得重要。 Transformer 的 KV 缓存问题在长上下文场景下越来越突出,Mamba、RWKV 这类 SSM/RNN 混合方案这一年多在学界里其实一直没停。Hierarchos 用 RWKV 做骨干,是在这条支线上又押了一注。
第三,赌可微分记忆比外挂记忆更值得投入。 这个赌注是最大的。外挂 RAG 的好处是模块解耦、容易升级,但代价是模型永远学不会「主动决定记什么、什么时候用」。可微分记忆槽让梯度能穿过整个记忆访问路径,理论上模型可以学到更精细的记忆策略。代价是训练难度陡增,规模化更难。
一些冷静的判断
把话说明白:Hierarchos 现在不是一个能拿来做生产的模型。232M 参数的短指令连贯性,跟你用 Llama 3 8B、Qwen 2.5 7B 甚至 Phi 系列比,绝对能力上差距不小。作者自己也没有做这样的对比声称。
它的价值在别处:
- 架构验证:证明了 RWKV + 分层控制 + 可微分记忆 + 确定性自动机这套组合能从零训练、能收敛、能维持基本的指令跟随。这是一份对后来者有用的可行性报告。
- 工程手册:train/inference parity、数值稳定性这些坑,作者踩过一遍,报告里的经验对任何想搞混合架构的团队都是财富。
- 开源生态的补充:在一堆越做越大的开源模型里,多一个专门探索小模型记忆架构的项目,对社区是好事。
如果你是做端侧智能体、做特定领域小模型、或者对非 Transformer 路线有兴趣的开发者,Hierarchos 值得跟一跟。如果你只想要一个开箱即用的助手模型,市场上现成的选择要多得多。
接下来看什么
项目当前状态还是 preliminary findings,没有跑主流的 benchmark,没有跟同规模模型做系统对比。这两个东西是接下来必须补的,否则很难说清楚这套架构相对于一个同参数量的 Transformer baseline,究竟带来了多少净收益。
另一个值得关注的方向是 scaling behavior。混合架构最怕的就是「小规模能跑,一放大就崩」。可微分记忆槽的数量、manager/worker 的层数、后缀自动机的介入粒度,这些超参数在放大到 1B、3B 时会怎么表现,才是真正决定这条路线能不能走远的关键。
短期内,Hierarchos 更像一个概念验证。但它至少提醒了一件事:在参数军备竞赛之外,小模型 + 架构创新这条支线还有戏,而且远没到被榨干的时候。
参考来源
- Hierarchos: Preliminary Findings From a 232M Recurrent Memory-Augmented Assistant Model - Reddit:项目原始技术报告发布贴,包含架构细节、训练配置和作者对踩坑经验的总结。
- 2025 最新「AI 智能体记忆」综述解读 - 知乎:北大、复旦等机构联合发布的智能体记忆综述解读,提出「形态-功能-动态」三维框架,对理解 Hierarchos 的架构选择有参考价值。
- hello-agents 第八章:记忆与检索 - GitHub:开源项目对工作记忆、情景记忆、语义记忆、感知记忆的工程实现拆解,可以跟 Hierarchos 的架构内建路线做对比。


