李飞飞用Qwen3-VL标了1亿张图,13TB数据集GPIC全量开源

斯坦福李飞飞、吴佳俊团队发布GPIC数据集,1亿张授权图片、28万亿像素,全部用Qwen3-VL-4B做自动标注与筛选,13TB数据全量开源且可商用。
李飞飞用Qwen3-VL标了1亿张图,13TB数据集GPIC全量开源
斯坦福 SVL 实验室上周把一个叫 GPIC 的图像数据集甩到了 Hugging Face 上——1亿张图、28万亿像素、13TB,全部开源,明确可商用。这次干活的还是李飞飞和吴佳俊那一拨人,他们上一次让圈内集体关注还是 ImageNet 时代。
这事的看点不在数量。Common Crawl 派生的 LAION-5B 比这大得多,但 LAION 那种"网上爬一遍管你版权"的路子早就走不通了——2023 年那波版权诉讼之后,Stability、Midjourney 都吃了官司,LAION-5B 本身也因为含 CSAM 内容被下架重做过一轮。GPIC 真正想解决的,是"干净、合规、带高质量描述的图像数据从哪来"这个老大难。
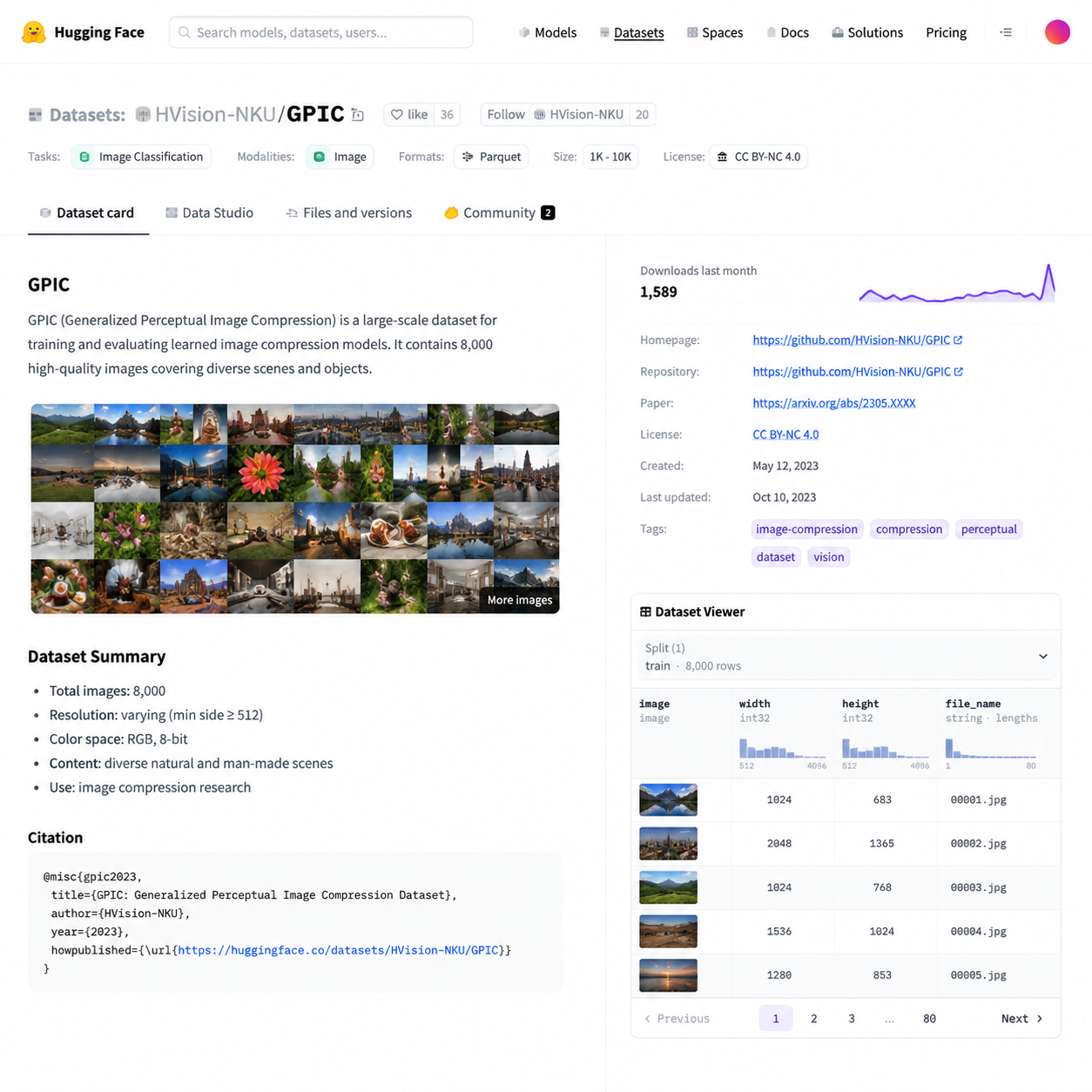
用 Qwen3-VL-4B 给一亿张图打标,烧了 1500 个 H100 小时
最让国内开发者眼前一亮的细节,是斯坦福这帮人在标注环节选了 Qwen3-VL-4B-Instruct。
根据论文披露,团队基于 1520 张人工核验集做了横向对比,候选里包括了若干闭源 VLM 和开源同尺寸模型。最后 Qwen3-VL-4B 在描述准确度、幻觉率、安全过滤这几项综合下来胜出,处理 1 亿张图大约消耗 1500 个 H100 GPU 小时。
算笔账:按 H100 公有云均价 2 美元/小时算,整个数据集的标注成本大概 3000 美元出头。换成 GPT-4V 或 Gemini 2.5 Pro 走 API 调用,同等规模少说也得几十万美元——而且大概率还会被服务商以"批量自动化调用"为由限流。这就是开源小尺寸 VLM 在 2026 年的真实价值:不是替代旗舰模型做对话,而是让数据流水线这种规模化的脏活有了可行成本。
值得一提的是,团队还用 Qwen3-VL-4B 做了质量与安全双重过滤——质量差的、可能涉及未成年人或暴力色情的图片直接踢掉,淘汰率约 1%。这个数字看起来不高,但对一个原始池超过 1 亿的数据集来说,意味着 100 万张候选图被打回。LAION 当年要是有这一步,可能就不用下架了。
数据从哪来:授权图库 + 去重
GPIC 全称是 General-Purpose Image Corpus,原始素材全部来自有商用授权的图库供应商,不是从公开网站爬的。这是和 LAION 路线最本质的区别。
拿到原始池之后,团队的处理流程大致是:
- 去重:1 亿张里有大量连拍、相似构图,团队用感知哈希加视觉嵌入做了两层去重
- Qwen3-VL-4B 过滤:质量差、NSFW、误标内容踢出
- 多粒度打描述:每张图配多条描述,有一两个关键词的短标签,也有几十字甚至上百字的长 caption
- 元数据保留:分辨率、aspect ratio、原始来源标识都保留在 parquet 里
这种"短标签 + 长描述"的多粒度结构,对训练文生图模型来说几乎是标配——SD3、FLUX 这一代模型已经验证过,描述质量和粒度差异直接决定了模型对 prompt 的理解上限。GPIC 把这一步做完了交给社区,等于把数据预处理这段最脏最累的活给免了。
13TB,怎么用?
linux.do 上有人发问:这玩意除了训模型还能拿来做什么前端应用?说实话,这个问题问得有点天真,但又确实代表了一部分开发者的困惑。
13TB 数据,真不是拿来直接"用"的。它的定位非常明确——视觉生成模型的预训练公开基准。具体能落到几条路径上:
- 训练文生图模型:这是最直接的用法。中小团队没必要从零开始做数据清洗,拿 GPIC 直接接预训练 pipeline 即可
- 训练/微调 VLM:图像-文本对天然就是 VLM 的训练料,特别是长描述部分对训练理解长文本指令的模型很有价值
- 图像检索 / RAG:把 GPIC 的图像嵌入预计算后做向量库,可以构建可商用的图像检索服务
- 评测基准:因为有人工核验子集,可以拿来做生成模型的对齐评估
如果只是想做"图片搜索""AI 相册"这种应用,那确实用不上 GPIC——你需要的是模型而不是数据。但如果你在做底层模型,GPIC 这个体量、这个清洗质量、这个授权状态,国内能找到的对标几乎没有。
为什么这事值得国内开发者关注
抛开数据集本身,这个项目折射出几件事。
第一,开源 VLM 的能力梯度已经能撑起严肃工程任务。Qwen3-VL-4B 是阿里今年初放出来的小尺寸 VLM,参数量只有 4B,在斯坦福这种对方法论极其挑剔的团队手里,它直接被选为亿级数据的标注工具——这是一个相当强的背书。要知道斯坦福过去几年的论文里,VLM 部分默认用的都是 GPT-4V 或 Gemini。
第二,"小模型 + 大数据"正在变成基础设施级别的工作流。过去做数据清洗要么靠人工众包、要么烧旗舰 API,现在 4B 级别的开源 VLM 已经能把成本压到云 GPU 时长这个量级。后续可能会看到更多团队跟进——拿 Qwen3-VL、InternVL、MiniCPM-V 这些做大规模数据 relabel,重新清洗自己手里的数据。
第三,合规问题正在被技术手段反推解决。GPIC 选授权图源 + 自动安全过滤这套组合拳,等于给所有想做基础视觉模型但又怕版权的团队提供了一个"现成答案"。这对国内做生成式模型商业化的厂商尤其有意义——以后产品被指控"训练数据来源不明",至少多了一个干净的可替代选项。
一点小遗憾
13TB 的下载量对大多数个人开发者来说是劝退的。Hugging Face 的下载速度即便在国内有镜像,全量拉下来也得按天算,更别说本地存储和处理所需的硬件。
好在数据是 parquet 分片格式,可以按需流式读取。如果只是想看看数据质量、跑个小实验,拉几个 shard 试试手就够了。后续大概率会有团队基于 GPIC 做出蒸馏版的子集,比如 100 万张精选版,那时候才是大多数人真正能上手玩的时机。
至于 Qwen3-VL-4B 这个数据集背后的功臣,目前在 OpenAI Hub 上也是可以直接调用的,省去自己部署的麻烦——如果你想复现斯坦福这套标注流程,或者拿它来清洗自己的图像库,可以直接走 OpenAI 兼容格式。
参考来源
- linux.do 社区讨论:李飞飞团队用 Qwen3-VL-4B 打标了一亿张图片 - 国内开发者关于 GPIC 数据集用途的讨论
- Hugging Face: stanford-vision-lab/gpic - GPIC 数据集官方发布页,含全部 13TB 数据下载