李飞飞团队开源GPIC:1亿张图、28万亿像素

斯坦福视觉实验室放出GPIC数据集,1亿张授权图片配文字描述,标注模型用的是Qwen3-VL-4B。这是视觉生成训练数据的一次量级跃迁。
李飞飞团队又干了件大事。
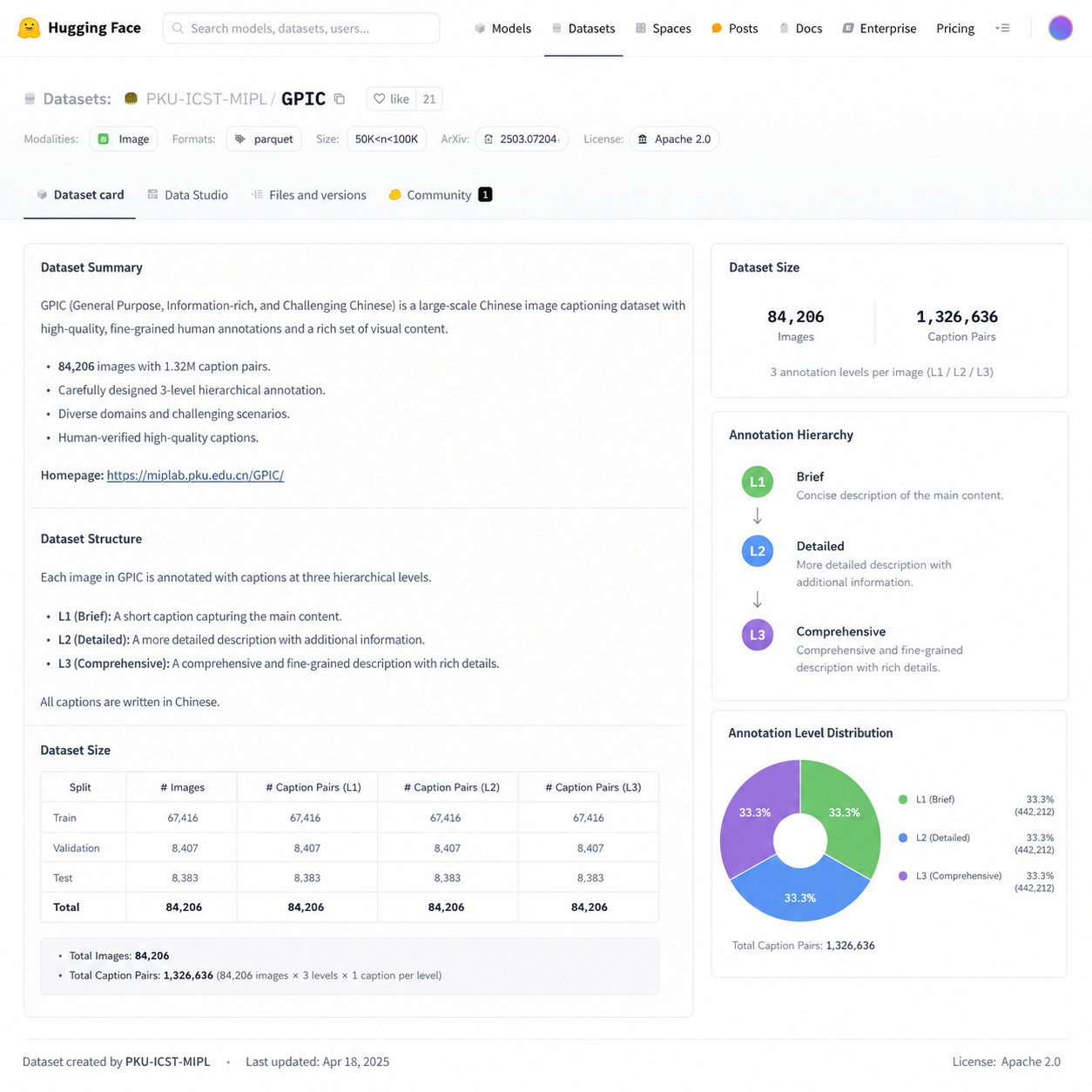
6月初,斯坦福视觉实验室(Stanford Vision Lab)在 Hugging Face 上低调放出了一个叫 GPIC 的数据集——1 亿张授权图片,总像素接近 28 万亿,每张图都配了详细的文字描述,整个数据集体积约 13TB。这是迄今为止公开的、带高质量文本标注的最大规模图文对之一。
更有意思的是标注方案:他们没用 GPT-4o,也没用 Gemini,而是选了阿里去年 10 月开源的 Qwen3-VL-4B——一个只有 40 亿参数的小模型——把这 1 亿张图全部跑了一遍。
这事值得拆开聊聊。
不是简单的「图多」,是数据集设计思路变了
过去几年视觉训练数据的玩法,基本是 LAION 那一套:从 Common Crawl 里爬,靠 alt-text 当标注,规模能堆到 50 亿,但质量参差不齐,版权问题更是悬在头上的剑——LAION-5B 因为里面混了非法内容被下架过,到现在还没完全恢复。
GPIC 的路子完全不同:
- 全部使用授权图片,避开了版权地雷
- 1 亿张的规模虽然比 LAION 小一个数量级,但每张都有 VLM 生成的高质量描述
- 标注分层:1% 是 Tag(关键词),45% 是 Short(短描述),45% 是 Medium(中等长度),9% 是 Long(长描述)
这种分层标注的设计很聪明。训练扩散模型时,不同 caption 长度对应不同的训练目标——短 caption 帮模型学概念,长 caption 帮模型学构图细节和长尾语义。Stable Diffusion 3、FLUX 这些新一代模型都在用类似的混合策略,但靠开源数据集里手工凑这种结构基本不可能,GPIC 直接把这件事做完了。
28 万亿像素是什么概念?平均下来每张图差不多 28 万像素,大致是 500×560 的水平。这个分辨率不算特别高,但对训练基础视觉模型够用了——MidJourney v1、SD 1.5 当年用的都是 512×512。
为什么是 Qwen3-VL-4B?这才是真正的看点
标注 1 亿张图是个非常实际的工程问题。你算一下:
如果用 GPT-4o,按当前 API 价格,一张图 caption 大概 0.005 美元,1 亿张就是 50 万美元——还不算 rate limit 排队的时间。用 Gemini 2.5 Pro 便宜一些,但同样规模的成本依然是六位数美元。
更关键的是延迟。即便有钱烧,闭源 API 的吞吐天花板就在那,1 亿张图按 100 QPS 算也得 11 天不停跑,实际中断、重试、限流一来,半年都不一定搞完。
所以李飞飞团队的选择就很现实:自己部署开源 VLM,跑在自家集群上。而 Qwen3-VL-4B 是去年 10 月阿里通义千问团队开源的轻量版本,4B 参数意味着单张 24GB 的 4090 就能跑推理,A100 上能跑出非常可观的吞吐量。
论文里说,他们对比测试过多个开源 VLM,Qwen3-VL-4B「在质量与吞吐量之间取得了最佳平衡」。这句话翻译一下就是:
- 比它大的(比如 InternVL2-26B、Qwen3-VL-32B)质量略好但吞吐量太低,扛不住 1 亿规模
- 比它小的(2B 以下的 VLM)质量明显不够
- LLaVA 系列、CogVLM 这些老牌选手在中文场景和细节描述上差点意思
这其实给行业释放了一个信号:4B 量级的多模态模型已经实用化到可以承担工业级标注任务。一年前你跟我说用 4B 模型给斯坦福实验室标 1 亿张图,我可能会问"质量行吗",现在这事就这么发生了。
这事对开源生态意味着什么
仔细看 GPIC 的技术栈,会发现一个挺有意思的现象:美国顶级实验室的研究,用中国开源模型当生产力工具。
这在两年前是不可想象的。当时大家做视觉标注的默认选择是 BLIP-2、CLIP,再往上就是闭源 API。现在 Qwen-VL、InternVL、MiniCPM-V 这些国产开源 VLM 已经成为很多研究团队的默认选择,原因很简单——便宜、能本地跑、质量够。
顺便说一句,GPIC 数据集开源后,社区里已经有人在讨论怎么用。比较直接的用途有几个:
- 训练新的文生图基础模型——这是最明显的用途,开源社区可以基于 GPIC 训练 SD / FLUX 量级的模型而不用担心版权
- 训练 VLM——反过来,可以用 GPIC 训练新的视觉理解模型,相当于 Qwen3-VL-4B 给下一代模型铺了路
- 做检索增强生成(RAG)的视觉知识库——1 亿张带描述的图天然就是一个巨大的多模态知识库
- 评测基准构造——可以从中抽取子集做更细粒度的评测
至于有人问「能不能做成前端应用」,老实说直接拿这 13TB 数据做 C 端产品意义不大——它更像是基础建材,不是成品。但基于 GPIC 训练出来的模型,未来很可能会驱动你下个月在用的某个 AI 工具。
一个需要警惕的点
不过有件事得提一嘴:用 VLM 标注的数据训练新的视觉模型,本质上是在做知识蒸馏——新模型学的是 Qwen3-VL-4B 对世界的理解,而不是真实世界本身。
这会带来两个潜在问题:
- 错误传播:Qwen3-VL-4B 本身的描述错误(比如把柯基认成柴犬)会被新模型继承
- 风格趋同:所有用 GPIC 训练的模型可能在描述偏好上趋同,因为它们的"老师"是同一个
李飞飞团队在论文里其实也提到了这一点,他们用了一些采样和后处理策略来缓解,但这是行业层面需要长期关注的问题。当合成数据占比越来越高,模型多样性会不会塌缩,是个开放问题。
写在最后
回过头看,GPIC 这件事其实是一个挺标志性的节点:
- 数据规模上,公开授权图文对终于摸到了亿级
- 工具链上,开源 VLM 正式承担起工业级标注的重任
- 版权合规上,全授权数据集给后续商用模型扫清了一个大障碍
对国内开发者来说,最直接的影响是——以后训自己的视觉模型,不用再偷偷摸摸用爬虫数据了,GPIC 直接拿来就能用,13TB 的传输量虽然不小,但比起从零自己攒数据集,这成本可以忽略不计。
顺便,如果你在做应用层、想直接调用 Qwen3-VL 系列或者拿它做对比测试,OpenAI Hub 这边的 Qwen3-VL 接口是 OpenAI 格式兼容的,国内直连,不用折腾代理,跟 GPT-4o、Claude、Gemini 共用一个 Key 切换比较方便——做多模型评测的时候省事。
李飞飞这几年一直在推「以数据为中心的 AI」(Data-Centric AI),GPIC 算是这个思路的一次大规模工程落地。模型架构卷到现在已经趋同,下一波竞争的焦点回到数据本身——这个判断,看来是对的。
参考来源
- 李飞飞团队用Qwen 3 VL 4B打标了1亿张图片 - linux.do:社区最早讨论 GPIC 数据集的帖子
- stanford-vision-lab/gpic - Hugging Face:GPIC 数据集官方页面,13TB 资源可下载
- 百万规模数据集已经不够用了!斯坦福开源GPIC:28 万亿像素 - 知乎:对 GPIC 标注流程和分层策略的详细解读