开源语音输入工具 typeformic:大模型纠错让说话变打字

开发者 uk0 开源了一个 macOS 语音转文本工具 typeformic,用系统自带语音模型识别后交给大模型纠错,1.5 秒内完成输入。这个思路解决了语音识别的老问题:识别快但错字多。
开源语音输入工具 typeformic:大模型纠错让说话变打字
开发者 uk0 在 Linux.do 社区发布了一个名为 typeformic 的开源工具,专门给 macOS 用户做语音转文本输入。它的核心卖点是把系统自带的语音识别模型和大模型结合起来:先用本地模型快速转写,然后扔给 LLM 纠错,最后自动输入到当前光标位置。整个流程控制在 1.5 秒内,取决于你用的 LLM API 响应速度。
这个工具本质上是在解决语音识别的一个老问题:速度和准确率的平衡。苹果系统自带的语音识别引擎足够快,但在专有名词、多音字、同音词这些场景下容易翻车。传统做法是上更重的模型或者后处理规则库,但 typeformic 选择了另一条路——把纠错工作外包给大模型。
为什么要做语音纠错
语音识别模型输出的文本经常会出现"幻觉"问题。这不是模型瞎编,而是声学特征和文本特征在向量空间上本来就有 gap。微软研究院在 FastCorrect 系列论文里指出,ASR 模型在高噪声环境下特别容易产生错误,尤其是实时转写场景,模型没有足够的上下文来消歧。
另一个典型问题是"串语种"。你说的是英文,识别出来变成了中文翻译。这是因为多语言模型在声学特征映射不够精确时,会自动启用翻译能力。阿里通义实验室在 FunAudio-ASR 的技术文档里专门分析过这个现象,他们的解决方案是用 CTC 解码器生成第一遍转写作为上下文 Prompt,引导 LLM 聚焦在识别任务而不是翻译任务上。
typeformic 的思路和这个类似,但更轻量。它不训练自己的纠错模型,直接调用现成的大模型 API。这样做的好处是开发成本低,坏处是每次纠错都要走一遍网络请求。
工作流程拆解
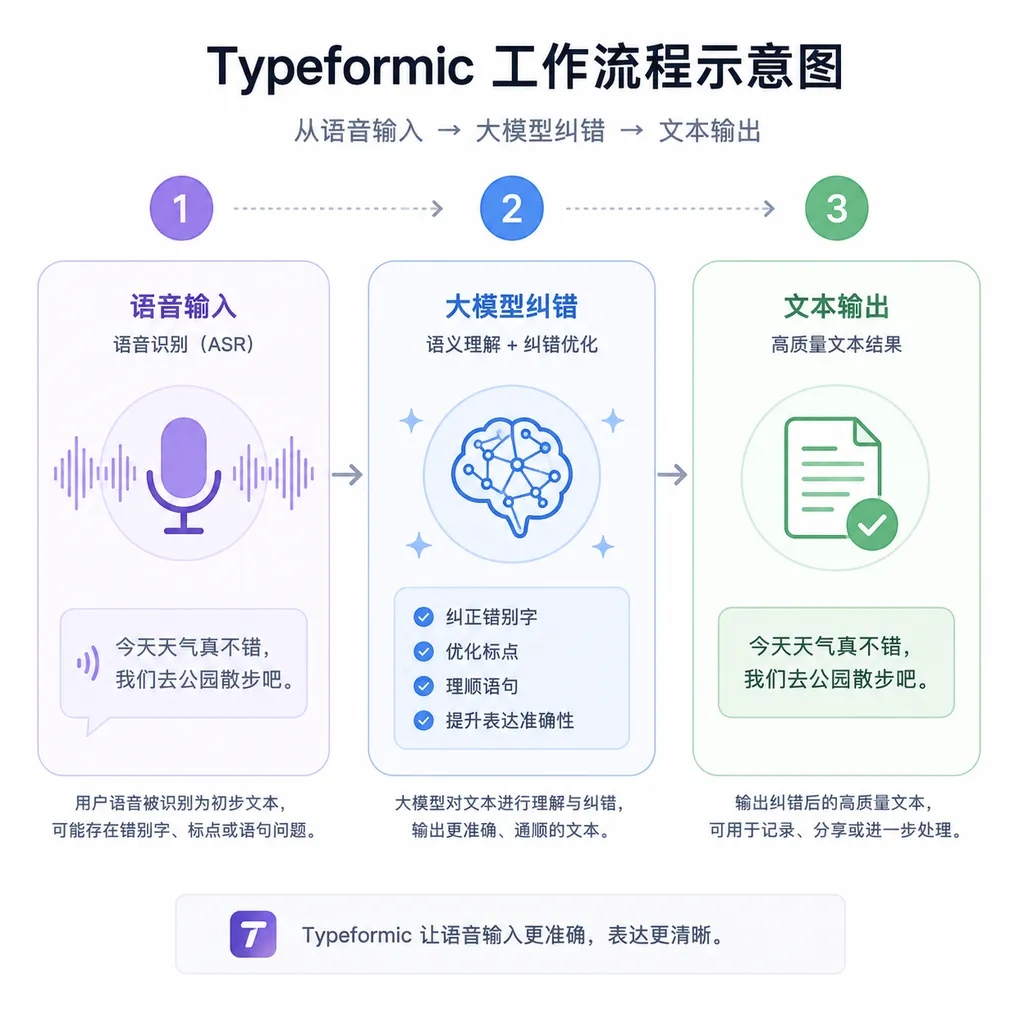
typeformic 的完整流程分三步:
-
语音识别:调用 macOS 系统的 Speech Recognition API。苹果从 macOS 10.15 开始提供了本地化的语音识别能力,支持多种语言,不需要联网。识别速度很快,基本能做到实时转写。
-
文本纠错:把识别结果发给大模型 API(项目没有限定具体用哪个模型,理论上支持所有兼容 OpenAI 格式的接口)。Prompt 设计应该是让模型扮演文本校对员的角色,输入原始转写文本,输出修正后的版本。
-
自动输入:用 macOS 的 Accessibility API 或者 CGEvent 把纠错后的文本模拟键盘输入到当前活动窗口的光标位置。这一步需要用户授权辅助功能权限。
整个链路的延迟主要卡在第二步。本地语音识别和自动输入都是毫秒级,大模型 API 的响应时间通常在 500ms 到 2 秒之间,取决于模型大小、Prompt 长度和服务商的网络质量。作者说 1.5 秒是平均值,实际体验应该会有波动。
为什么选择大模型做纠错
传统的 ASR 纠错方案主要有两种:基于规则的后处理和基于模型的端到端纠错。
规则方案靠人工整理的词库和语法规则库来匹配和替换错误。优点是可控性强、延迟低,缺点是覆盖面有限,遇到新词或者语境复杂的句子就失效了。
模型方案里比较成熟的是微软的 FastCorrect 系列。FastCorrect 1 用非自回归的编辑对齐(Edit Alignment)架构,把自回归纠错模型的延迟降低了 6-9 倍。FastCorrect 2 进一步利用 N-best 假设(ASR 模型通常会输出多个备选结果),让不同识别结果相互印证来提升准确率。但这些方案需要专门训练纠错模型,还得准备标注好的错误-正确文本对作为训练数据。
大模型的优势在于泛化能力。它见过海量文本,对语法、语义、常识都有一定理解,可以处理规则库和小模型覆盖不到的长尾场景。而且不需要额外训练,只要设计好 Prompt 就能上线。缺点是成本高(每次纠错都要调 API)、延迟不可控(依赖服务商的响应速度)、效果不稳定(Prompt 工程是个玄学)。
typeformic 选择大模型,本质上是在用推理成本换开发成本和覆盖面。对于个人开发者或者小团队来说,这个 trade-off 是合理的。
技术实现细节
项目代码在 GitHub 上完全开源,主要用 Swift 写的。选择 Swift 而不是 Python 或者 Electron,应该是为了更好地调用 macOS 原生 API 和控制性能。
语音识别部分用的是 Speech 框架,这是苹果从 iOS 10 / macOS 10.15 开始提供的官方语音识别接口。核心类是 SFSpeechRecognizer,支持实时转写和音频文件转写两种模式。实时模式下,你可以给它一个音频流,它会持续输出中间识别结果和最终结果。
自动输入部分可能用了两种方式之一:
-
CGEvent 模拟键盘:用
CGEventCreateKeyboardEvent生成按键事件,然后通过CGEventPost发送到系统事件流。这种方式模拟的是真实键盘输入,兼容性好,但需要逐字符发送,对于长文本输入效率不高。 -
Accessibility API 直接插入文本:用
AXUIElement获取当前焦点的文本框,然后调用AXUIElementSetAttributeValue直接设置文本内容。这种方式更快,但不是所有应用都支持 Accessibility 接口。
大模型调用部分应该是个标准的 HTTP 客户端,发 POST 请求到 LLM API endpoint,把识别文本放在 messages 数组里,解析返回的 JSON 拿到纠错后的文本。
实际使用场景和局限性
语音输入工具的适用场景其实很窄。它最适合的是这几类情况:
-
长文本写作:写文章、写邮件、写文档,手敲太慢,语音输入能显著提速。但前提是你的思路要清晰连贯,不能想一句说一句然后频繁修改。
-
无法用手操作:开车、做饭、带娃的时候需要回消息或者记录想法。
-
打字不便:键盘故障、手部受伤、在移动设备上输入长文本。
但 typeformic 有几个明显的局限:
只支持 macOS。语音识别和自动输入都依赖苹果的私有 API,跨平台几乎不可能。Windows 和 Linux 用户得找别的方案。
依赖外部 API。大模型纠错需要联网,每次调用都有成本(按 token 计费)和延迟(网络 RTT)。如果 API 挂了或者限流,整个工具就不可用。
纠错质量不稳定。大模型不是专门为 ASR 纠错训练的,它可能会"过度纠错",把一些专有名词或者口语化表达改成书面语。而且 Prompt 设计对效果影响很大,需要反复调试。
隐私问题。你说的每句话都会以明文形式发送到 LLM 服务商的服务器。如果涉及敏感信息(密码、私密对话、商业机密),这个风险不能忽视。
无法处理标点和排版。语音识别通常不输出标点符号,大模型可以补一部分,但对于复杂的段落结构、列表、代码片段,纯语音输入还是力不从心。
和其他方案的对比
市面上已经有不少语音输入工具,typeformic 的定位在哪里?
系统自带输入法:macOS 和 Windows 都内置了语音输入功能,不需要安装额外软件。但它们的纠错能力很弱,基本只能靠语言模型做基础的语法修正,遇到同音词或者专有名词就翻车。
讯飞、搜狗等商业输入法:识别准确率高,支持方言和垂直领域词库,但都是闭源的,而且有隐私顾虑(你的语音数据会被上传到他们的服务器做模型训练)。
Talon Voice:面向程序员的语音编程工具,可以用语音控制 IDE、编写代码、执行命令。它的定位不是通用输入,而是替代键盘鼠标操作,学习曲线陡峭。
Whisper + 本地 LLM:用 OpenAI 的 Whisper 做语音识别(开源,可以本地运行),然后调用 Ollama 或者 LM Studio 跑本地大模型做纠错。这个方案的优势是完全离线、零成本、数据隐私有保障,但配置复杂,而且本地模型的纠错效果不如云端的大模型。
typeformic 的特点是轻量、开箱即用、效果和云端大模型持平,代价是每次使用都要花钱(API 费用)和承担隐私风险。
可能的改进方向
项目目前还比较初级,有几个明显可以优化的点:
支持离线模式。集成本地小模型做基础纠错(比如用 GGUF 格式的量化模型跑在 llama.cpp 上),只有在遇到疑难场景时才调用云端大模型。这样可以降低 API 成本和延迟,同时提升隐私性。
增加 Context 增强。参考 FunAudioLLM 的 CosyVoice 2 方案,用 CTC 解码器生成第一遍转写文本作为 Prompt 的一部分,减少大模型的幻觉和串语种问题。
定制化词库。让用户上传自己的专有名词库(人名、地名、产品名、技术术语),在调用大模型时通过 RAG 机制动态检索相关词汇,提升召回率。这个思路在 FunAudio-ASR 的行业定制化方案里已经验证过。
多模态纠错。不只看文本,还要结合声学特征(音高、语速、停顿)来判断断句和语气,生成更自然的标点符号。
支持流式输入。现在的流程是等语音说完、识别完、纠错完才一次性输出全部文本。可以改成流式模式:边说边识别边纠错边输入,体验会更流畅。CosyVoice 2 已经实现了 150ms 的流式延迟,技术上完全可行。
跨平台支持。Windows 可以用 Windows Speech API,Linux 可以用 PocketSphinx 或者 Vosk。自动输入部分可以用跨平台的自动化库(比如 PyAutoGUI)。核心逻辑用 Rust 或 Go 重写,编译成跨平台的 CLI 工具。
开源语音工具的生态位
语音识别这个领域,商业方案已经很成熟了。Google、Amazon、Azure、讯飞、阿里都有成熟的云服务,准确率高、功能全、API 稳定。但开源方案的价值在于可控性和可定制性。
对于开发者来说,开源意味着你可以看到完整的实现细节,可以根据自己的需求修改和扩展,可以离线运行保护数据隐私,可以避免供应商锁定。
对于企业来说,开源意味着更低的长期成本(不用按调用次数付费),更高的安全性(敏感数据不出内网),更强的定制能力(可以针对垂直领域优化模型)。
typeformic 作为一个个人项目,代码量不大(估计几百行 Swift),但它证明了一个思路:把开源的系统 API 和商业的大模型 API 组合起来,可以快速搭建出实用的工具。这个思路可以推广到其他场景——比如用系统的 OCR 识别图片文字,然后用大模型做结构化提取;用系统的 TTS 生成语音,然后用大模型优化文本的口语化表达。
写在最后
语音转文本是个很老的问题,但远没有被解决。现在的 ASR 模型在安静环境、标准发音、常见词汇的场景下已经接近人类水平,但在噪声、口音、专有名词、多人对话的复杂场景下还是会翻车。
大模型的出现给了纠错任务一个新的解决路径。它不需要专门的训练数据,不需要手工整理规则库,只要设计好 Prompt 就能处理各种长尾场景。当然,这个方案也有成本、延迟、隐私方面的代价。
typeformic 的价值不在于技术创新(它只是把现成的组件组合起来),而在于它是开源的、可运行的、能解决实际问题的。对于想做类似工具的开发者来说,这是个很好的起点。
如果你是 macOS 用户,而且经常需要长文本输入,可以试试这个工具。记得在使用前评估一下隐私风险——如果你要输入的内容包含敏感信息,建议改用完全离线的 Whisper + 本地 LLM 方案。
项目地址:https://github.com/uk0/typeformic
参考资料
- typeformic 项目讨论串 - 作者在 Linux.do 社区发布的原帖,包含项目背景和使用说明
- typeformic GitHub 仓库 - 完整源代码和文档
- FastCorrect 论文 - 微软研究院的语音识别纠错模型系列
- pycorrector 中文文本纠错工具 - 开源的文本纠错工具包,支持多种模型


