瑞典团队让神经网络先学物理再做设计,纳米光学材料筛选快10倍

查尔姆斯理工大学将物理定律直接嵌入神经网络,把纳米光学材料筛选的训练时间从30天压到3天。这不是暴力堆算力,而是让AI在训练前就懂基础物理。
瑞典团队让神经网络先学物理再做设计,纳米光学材料筛选快10倍
查尔姆斯理工大学的研究团队刚在《激光与光子学评论》发了篇论文,核心就一件事:把物理定律直接嵌入神经网络,让AI在训练前就懂基础物理。结果是纳米光学材料筛选的训练时间从30天压到3天,预测精度还提升了。
这事儿有意思的地方不在"又一个AI加速",而在于思路的转向。过去几年AI圈都在卷算力、卷数据,这帮人反其道而行之:既然物理定律是确定的,为什么要让模型从零推导?
传统AI筛材料有多慢
纳米光子学研究的是小于光波波长尺度上的光传播和相互作用。在这个尺度,光的行为跟宏观世界完全不一样,天然材料的性能有限,所以得设计人造光学材料来精确控制光。
问题是怎么设计。传统流程是:提出一个结构→跑电磁场模拟→看光学性质→不行就调参数→再跑模拟。一个数据点的生成时间是10分钟到1小时,训练一个神经网络模型可能需要4万个数据点。算下来,光生成训练数据就得几周到几个月。
机器学习确实能加速这个过程,但瓶颈在数据生成。模型再聪明,也得先有足够的样本让它学。查尔姆斯团队之前就卡在这:想用AI优化纳米结构设计,结果发现大部分时间都花在等数据上。
让AI先上物理课
这个团队的突破口,在于改变了神经网络和物理定律之间的关系。传统做法是让神经网络从海量模拟数据中自己"摸索"出物理规律,类似于让一个从未上过物理课的人通过大量实验总结出牛顿定律。
查尔姆斯团队的做法是:直接把物理学和电磁学的基本定律编码进神经网络的结构里。具体来说,是在网络架构中内置麦克斯韦方程组的约束条件,让模型在训练开始前就"知道"光在介质中的传播规律、边界条件、能量守恒等基础物理。
这样模型就不用从数据里反推这些规律了,它只需要学习"在这个特定纳米结构下,光会怎么表现"这种更高层次的问题。数据需求量直接下降了一个数量级。
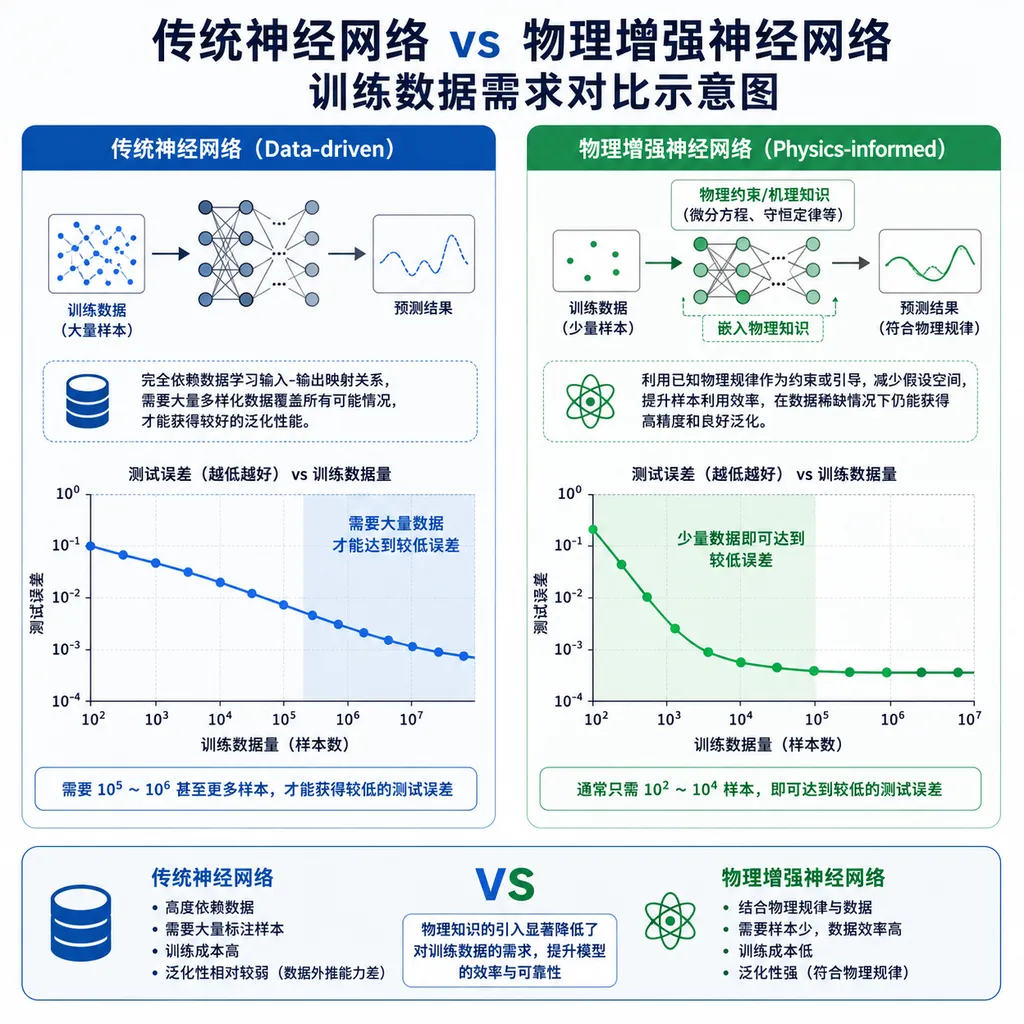
30天压到3天,精度还提升
测试结果很直接:原本需要30天完成的数据生成和模型训练,现在3天搞定。不是换了更快的硬件,就是少生成了90%的训练数据。
更关键的是精度。按理说数据少了,模型性能应该下降才对。但因为物理约束本身就是一种强先验知识,模型反而能减少明显的物理违背错误。比如预测某个结构的透射率时,传统模型可能给出能量不守恒的结果,物理增强模型不会犯这种低级错误。
训练完成后,这个"懂物理"的神经网络可以在毫秒级时间内预测任意纳米结构的光学性质。对比之下,传统电磁场模拟软件(比如COMSOL、Lumerical)跑一次需要几分钟到几小时。
这个速度差意味着什么?意味着可以在设计阶段快速迭代成千上万种候选结构,筛出最优解。以前可能只能测试几十个设计方案,现在可以穷举整个参数空间。
不只是光学材料
这套方法的适用范围比纳米光学宽得多。任何需要大量物理模拟、数据生成昂贵的领域都可能受益:
量子计算:量子比特的设计需要精确控制电磁场和材料性质,传统模拟极其耗时。物理增强神经网络可以加速超导量子比特、拓扑量子比特的结构优化。
先进光学器件:超透镜、光学超表面、集成光子芯片的设计,都涉及复杂的光场调控。现在这些器件的设计周期能大幅缩短。
材料科学:预测新材料的电学、磁学、热学性质,传统方法依赖密度泛函理论(DFT)计算,计算成本高。把量子力学约束嵌入神经网络,能在保证物理正确性的前提下加速材料筛选。
流体力学和气动设计:飞机机翼、涡轮叶片的优化需要大量CFD(计算流体动力学)模拟。物理增强神经网络可以大幅减少模拟次数。
类似的思路在其他领域也有苗头。2025年9月Nature发过一篇关于"物理神经网络"(Physical Neural Networks)的综述,讨论的是用光、电、振动等物理系统直接做计算,绕开传统GPU。查尔姆斯这个工作虽然还是在数字硬件上跑,但核心思想一致:利用物理规律本身来降低计算复杂度。
这个方向的局限
物理增强神经网络不是银弹。它的前提是你对问题的物理有足够清晰的理解,能把支配方程写出来。对于物理机制尚不明确的复杂系统(比如生物系统、社会网络),这套方法就不适用了。
另一个问题是泛化性。传统神经网络虽然需要大量数据,但训练好的模型在相似问题上泛化能力强。物理增强模型因为嵌入了特定的物理约束,换一个问题可能需要重新设计网络结构。
还有工程实现的难度。把麦克斯韦方程组或薛定谔方程编码进神经网络,不是简单加几层全连接层的事。需要对微分方程数值解法、自动微分框架有深入理解,开发门槛比标准深度学习高。
但这些局限不改变一个事实:在物理规律明确、模拟成本高昂的领域,物理增强神经网络已经证明了自己的价值。查尔姆斯团队把训练时间压到1/10,不是终点,而是起点。
AI和物理的新关系
过去几年AI发展的主旋律是"数据和算力解决一切"。大模型、Transformer、GPT,核心都是暴力:堆数据、堆参数、堆算力,让模型自己从海量样本中提取规律。
这条路在自然语言处理、计算机视觉上确实走通了,因为这些领域的"规律"本身就是模糊的、统计的。但在科学计算和工程设计领域,物理定律是确定的、精确的。让模型从数据里重新"发现"牛顿定律、麦克斯韦方程组,既低效又不可靠。
查尔姆斯团队的工作代表了另一个方向:把人类已有的科学知识编码进AI系统,让模型站在前人肩膀上而不是从头摸索。这不是对深度学习的否定,而是对它的补充和升级。
类似的思路在药物设计、蛋白质折叠预测(AlphaFold就嵌入了物理和化学约束)、气候模拟等领域都在探索。未来几年,这种"知识增强AI"可能会在科学研究和工程应用中占据越来越重要的位置。
对开发者来说,这意味着单纯的机器学习技能不够了。你得懂你要解决的问题的物理本质,才能设计出真正高效的模型。跨学科能力——深度学习+物理+数学+领域知识——会变得越来越关键。
参考来源
- 科技日报 - 数字"超级大脑"大幅提升光学材料筛选速度 - 官方报道,提供了研究团队背景和技术细节
- 智源社区 - 摆脱GPU依赖!Nature发布「物理神经网络」综述 - Nature综述解读,讨论物理神经网络的更广泛背景和未来方向


