中国大模型调用量连续六周霸榜全球

OpenRouter 最新数据显示,中国 AI 大模型周调用量达 14.19 万亿 Token,连续六周超越美国,全球前四均为国产模型。DeepSeek、MiniMax、腾讯、小米占据头部,Claude 系列首次跌出前五。
中国大模型调用量连续六周霸榜全球
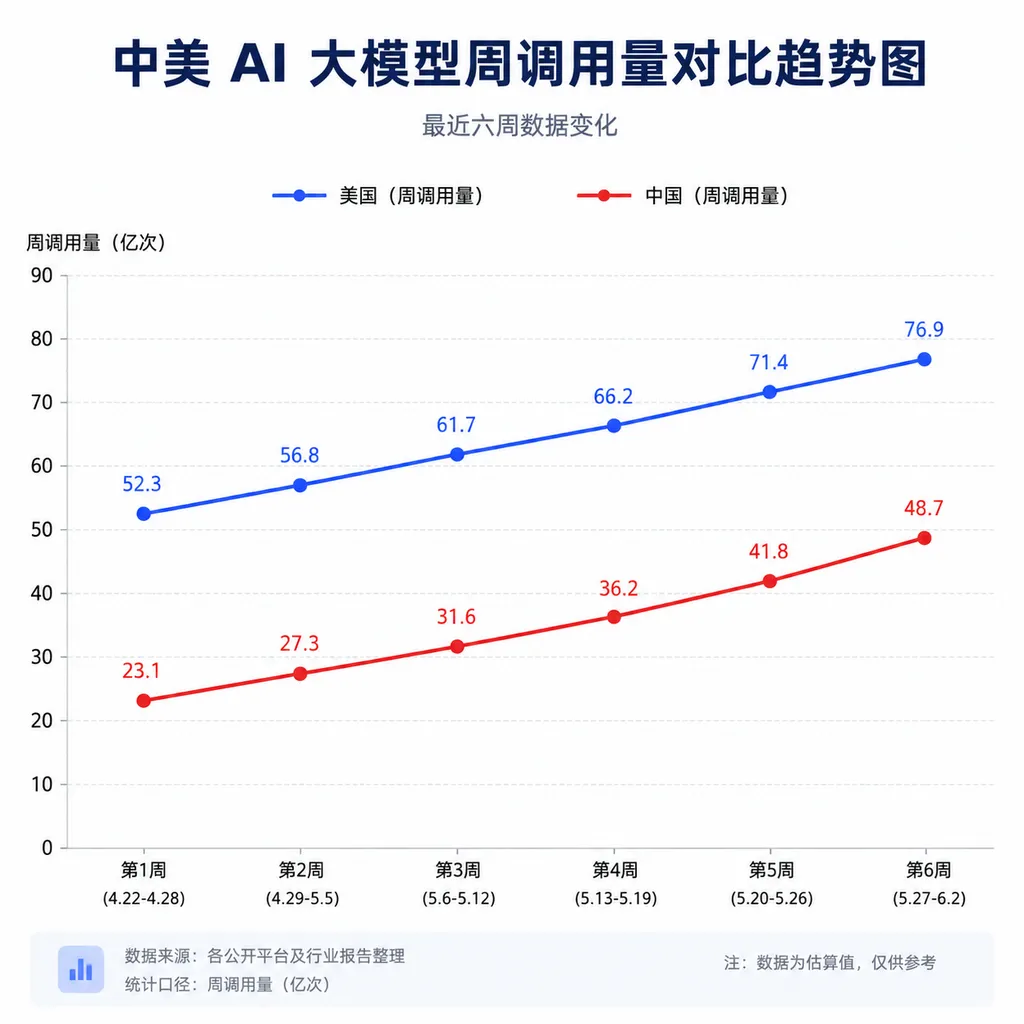
上周(6月1日至7日)全球 AI 大模型调用量达 36.1 万亿 Token,中国以 14.19 万亿 Token 的周调用量连续六周超越美国,环比增长 27.49%。同期美国调用量仅 3.2 万亿 Token,环比下降 24.53%。更关键的是,全球调用量前四名全部被国产模型包揽——这是中国大模型在全球开发者生态中真正站稳脚跟的标志。
这不是简单的数字游戏。调用量反映的是开发者用真金白银在投票,说明国产模型在性能、成本、可用性上已经形成了综合优势。从去年下半年美国还占据绝对优势,到今年连续六周被中国反超,这个逆转速度超出了大部分人的预期。
DeepSeek 连续三周蝉联榜首,MiniMax 异军突起
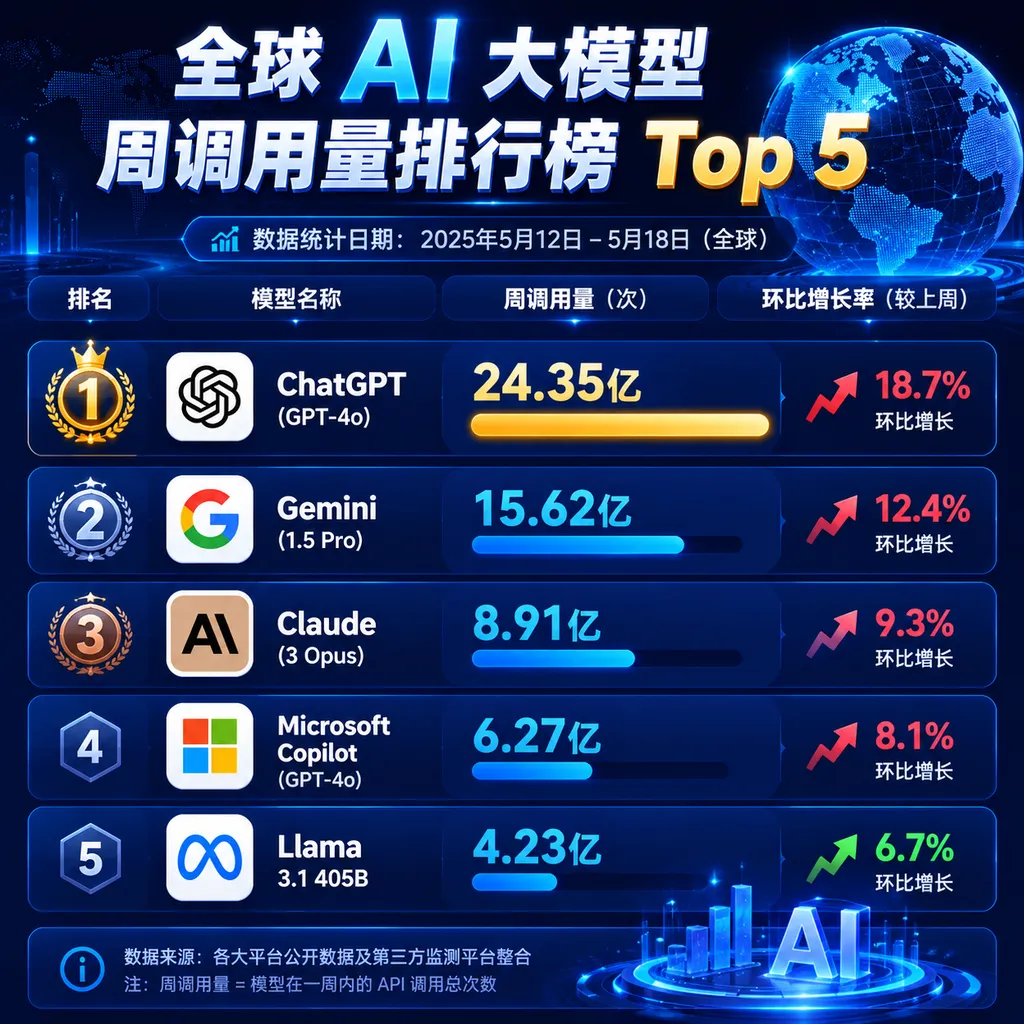
DeepSeek-V4-Flash 以 3.69 万亿 Token 的周调用量连续三周占据榜首,环比增长 19%。这个模型在去年底发布后迅速成为开发者首选,原因很简单:性能接近 GPT-4 级别,但价格只有十分之一,还支持 128K 上下文。对于需要大批量调用的应用场景来说,成本优势是压倒性的。
腾讯 Hy3 preview 连续三周稳居第二,周调用量 2.94 万亿 Token,虽然环比小幅下降 3%,但考虑到这是预览版本,能保持这个体量已经说明产品力足够强。腾讯在多模态理解和长文本处理上的优化,让它在内容审核、客服对话等场景中占据优势。
真正的黑马是 MiniMax M3。首周发布就冲到第三名,周调用量 2.5 万亿 Token。这个模型是国内首个同时具备前沿编程能力、1M 超长上下文窗口和原生多模态能力的大模型。1M 上下文是什么概念?可以一次性处理约 75 万个汉字,相当于一本中等篇幅的小说。对于需要处理长文档、代码库分析、法律合同审查的场景,这个能力是刚需。
小米 MiMo-V2.5 位居第四,周调用量 2.19 万亿 Token,环比激增 50%。小米在 IoT 设备集成和端侧推理上的布局,让它在智能家居、车载系统等场景中找到了差异化路线。但值得注意的是,此前大幅降价的 MiMo-V2.5-Pro 在短暂冲到第八名后迅速跌出榜单,说明单纯靠价格战拉动的调用量并不稳定,开发者更看重性能和稳定性的平衡。
Claude 系列首次跌出前五,美国模型全线回落
Claude Sonnet 4.6 和 Claude Opus 4.7 双双跌出前五,周调用量分别环比下降 9% 和 38%。这是 Claude Sonnet 4.6 近两个月来首次跌出前五,对 Anthropic 来说不是个好信号。
Claude 系列在代码生成和复杂推理任务上一直有口皆碑,但问题在于:第一,价格依然偏高,Opus 4.7 的输入成本是 DeepSeek-V4-Flash 的 20 倍;第二,国内访问不稳定,开发者需要绕过网络限制,增加了接入成本;第三,国产模型在中文理解和本地化场景上的优势越来越明显。
这不是说 Claude 技术不行,而是在全球化竞争中,单纯的技术领先已经不够了。开发者需要的是综合解决方案:性能、价格、可用性、本地化支持缺一不可。国产模型在这几个维度上都在快速追赶甚至反超,Claude 的护城河正在被削弱。
从厂商整体表现看,DeepSeek 旗下模型总调用量达 6.75 万亿 Token,连续四周位居厂商榜首,超过 Anthropic 和 Google。MiniMax 旗下模型总调用量 3.05 万亿 Token,超越小米和腾讯,成为新晋第二梯队领头羊。这两家公司的共同特点是:技术扎实、产品迭代快、定价策略灵活。
调用量激增背后:场景落地和成本优化的双重驱动
中国大模型调用量连续六周超越美国,背后有两个核心驱动力。
第一是场景落地速度快。国内厂商在电商客服、内容审核、代码生成、智能客服等高频场景中快速铺开,这些场景的调用量是天文数字。以电商客服为例,一个中等规模的电商平台每天可能产生数千万次对话,乘以全国数万家电商企业,调用量自然水涨船高。国产模型在中文理解、口语化表达、情感识别上的优势,让它们在这些场景中比英文模型更好用。
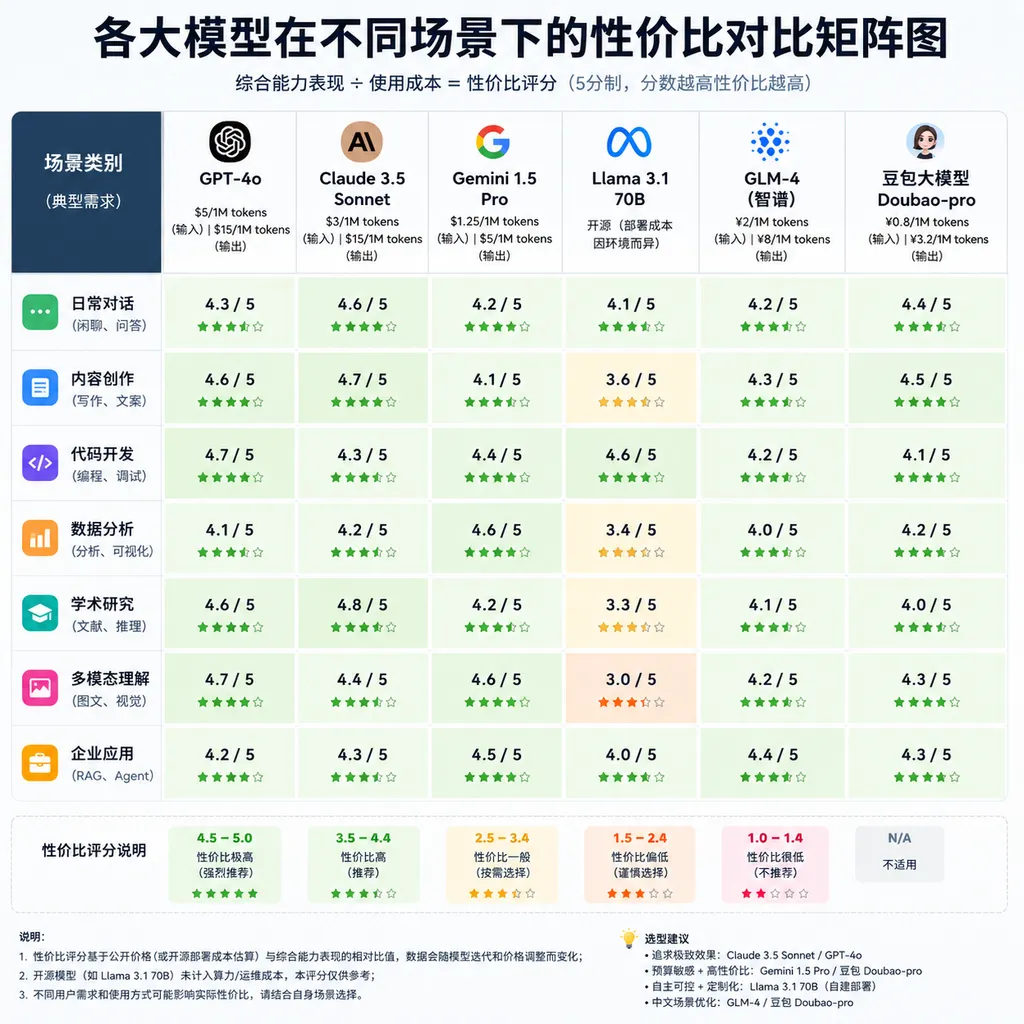
第二是成本优化做到了极致。DeepSeek-V4-Flash 的输入成本是每百万 Token 0.14 美元,输出成本 0.28 美元,而 Claude Opus 4.7 的输入成本是 15 美元,输出成本 75 美元。对于日调用量千万级的应用来说,成本差异是数十倍甚至上百倍。这不是小钱,而是直接影响商业模式能否跑通的关键变量。
价格战当然不是长久之计,但在技术差距缩小的前提下,成本优势会加速市场格局的重塑。开发者不是慈善家,在性能差距不大的情况下,当然选更便宜的那个。国产模型通过 MoE(混合专家)架构、推理优化、自研芯片等手段,把成本压到了一个美国厂商很难匹敌的水平。
还有一个容易被忽视的因素:国内直连。对于中国开发者来说,访问 OpenAI、Anthropic 的 API 需要解决网络问题,这不仅增加了延迟,还带来了合规风险。国产模型天然没有这个问题,部署在国内云服务上,延迟低、稳定性高。对于实时性要求高的应用(比如在线客服、游戏 NPC、直播助手),这是硬性指标。
价格策略的双刃剑:小米的教训
小米 MiMo-V2.5-Pro 在大幅降价后,周调用量曾环比激增 321%,一度冲到第八名。但仅仅一周后就跌出榜单,调用量大幅回落。这个案例很有代表性。
降价确实能快速拉动调用量,但如果产品本身没有足够的竞争力,用户不会留下来。开发者不是冲着便宜来的,而是冲着性价比来的。如果模型性能不够稳定、输出质量不够高、API 响应速度不够快,即使免费也没人用。
反过来看 DeepSeek 和 MiniMax,它们的价格也不贵,但调用量持续增长,说明产品力过硬。开发者愿意为好产品付费,但前提是这个产品真的能解决问题。价格只是敲门砖,长期竞争力还是要靠技术和服务。
全球开发者生态的重心正在转移
OpenRouter 是全球最大的 AI 模型 API 聚合平台,它的调用量数据相对客观,能反映真实的开发者选择。中国模型连续六周霸榜,说明全球开发者生态的重心正在转移。
这个转移不仅仅发生在中国市场。根据 OpenRouter 的数据,来自东南亚、拉美、中东等地区的开发者也在大量使用国产模型。原因很简单:这些地区的开发者对成本更敏感,对英文模型的依赖度没那么高,国产模型的性价比优势更明显。
美国模型在欧美市场依然占据优势,但在全球南方国家,国产模型正在快速渗透。这是一个值得关注的趋势。未来的 AI 竞争不仅仅是技术竞争,更是生态竞争、市场竞争。谁能更好地满足全球开发者的需求,谁就能占据更大的市场份额。
从这个角度看,中国大模型的崛起不是偶然,而是必然。庞大的国内市场提供了足够的训练数据和应用场景,激烈的竞争倒逼厂商快速迭代,成本优化能力让产品更具竞争力。这些因素叠加在一起,形成了一个正向循环。
技术差距还有多大?
需要客观地说,在某些前沿能力上,国产模型和 GPT-4o、Claude Opus 4.7 还有差距。比如在复杂推理、创意写作、多语言混合理解等任务上,顶级美国模型依然占优。但差距在快速缩小。
DeepSeek-V4 在数学推理、代码生成等任务上已经接近甚至超过 GPT-4,MiniMax M3 的 1M 上下文窗口在某些场景下比 GPT-4o 更实用,腾讯 Hy3 在中文多模态理解上比 Claude 表现更好。国产模型的策略是:不追求全面领先,而是在特定场景下做到最好。
这个策略很聪明。AI 大模型不是单一产品,而是工具箱。开发者需要的不是一个万能模型,而是一组能覆盖不同场景的模型矩阵。DeepSeek 主打性价比,MiniMax 主打超长上下文,腾讯主打多模态,小米主打端侧集成,各有各的护城河。
从调用量数据看,开发者已经在用脚投票。他们不在乎模型是哪国的,只在乎能不能解决问题、成本是否可控、服务是否稳定。国产模型在这些维度上已经做得足够好,这才是连续六周霸榜的根本原因。
接下来的变量:多模态和端侧推理
下一阶段的竞争焦点会转向两个方向:多模态和端侧推理。
多模态是刚需。真实世界的信息不只是文字,还有图片、视频、音频、3D 数据。能同时理解和生成多种模态的模型,会在更多场景中占据优势。MiniMax M3 原生支持多模态,腾讯 Hy3 在视频理解上有独特优势,这些能力会在短视频审核、智能监控、医疗影像分析等场景中发挥作用。
端侧推理更关键。把大模型部署在手机、IoT 设备、边缘服务器上,既能降低延迟,又能保护隐私,还能减少云端成本。小米在这个方向上布局最积极,MiMo 系列针对端侧场景做了大量优化。未来随着端侧算力提升和模型压缩技术成熟,越来越多的应用会从云端转向端侧。
美国厂商在这两个方向上也在发力,但国产厂商的优势在于:离场景更近、迭代更快、本地化更好。谁能先在这两个方向上跑通商业闭环,谁就能在下一阶段竞争中占据主动。
对开发者的启示
调用量榜单的变化,对开发者有几个启示。
第一,不要盲目追求最新最贵的模型。性价比才是王道。DeepSeek-V4-Flash 的性能已经能满足 90% 的应用场景,但成本只有顶级模型的十分之一。除非你的应用对推理能力有极致要求,否则没必要为那 10% 的性能提升多花 10 倍的钱。
第二,多模型策略是趋势。没有一个模型能覆盖所有场景,不同任务用不同模型,才能在性能和成本之间找到最佳平衡。比如简单的客服对话用 DeepSeek-V4-Flash,复杂的代码生成用 MiniMax M3,长文本分析用腾讯 Hy3,端侧推理用小米 MiMo。OpenAI Hub 这类聚合平台的价值就在这里,一个 Key 调所有模型,降低接入成本。
第三,关注调用量趋势,但不要被短期波动误导。小米 MiMo-V2.5-Pro 的暴涨暴跌就是典型案例。真正有竞争力的模型,调用量会持续增长,而不是昙花一现。开发者选型时,要看长期趋势,不要被促销活动带偏。
第四,考虑合规和可用性。对于国内应用来说,使用国产模型天然没有网络和合规问题,这是隐性成本。如果你的应用需要高可用性、低延迟,国产模型是更稳妥的选择。
写在最后
中国大模型连续六周霸榜全球调用量,不是靠政策扶持或低价倾销,而是靠真刀真枪的产品竞争力。DeepSeek、MiniMax、腾讯、小米这些厂商,在技术、成本、场景落地上都做对了事情,才能赢得开发者的认可。
Claude 系列跌出前五,不是它变差了,而是竞争对手变强了。这是一个开放的全球市场,开发者会用真金白银投票。美国厂商在某些前沿能力上依然领先,但国产厂商在综合竞争力上已经不落下风。
接下来的竞争会更激烈。多模态、端侧推理、垂直场景优化,每个方向都有机会。对开发者来说,这是好事——有更多选择、更低成本、更好服务。对厂商来说,这是挑战——必须持续创新,才能在这场马拉松中不被淘汰。
全球 AI 大模型的格局正在重塑,中国厂商已经站到了牌桌上。至于最后谁能笑到最后,要看谁能持续为开发者创造价值。调用量只是结果,产品力才是原因。
参考来源
- 中国 AI 大模型周调用量连续六周超越美国,前四名均为国产模型 - IT之家 - OpenRouter 最新监测数据,详细列出各模型调用量和排名变化
- 中国AI大模型周调用量超越美国,包揽全球前三 - 知乎 - 早期数据分析,展示中国大模型崛起趋势


