国家数据局首发高质量数据集建设方案,AI训练数据进入「工业化」时代

国家数据局今日发布行业高质量数据集建设实施方案,首次从国家层面系统部署数据赋能AI发展。方案聚焦智能体、具身智能等前沿方向,部署六大专项行动,目标到2028年建成覆盖重点领域的数据集体系,数据产业年均增速超20%。
国家数据局首发高质量数据集建设方案,AI训练数据进入「工业化」时代
国家数据局今天发布《关于推进行业高质量数据集建设行动的实施方案》,这是国家层面首次对数据赋能人工智能发展作出的系统性部署。
这份方案不是喊口号。它围绕数据集供给、流通、应用等关键环节,部署了强基扩容、标注攻坚、提质增效、应用赋能、管理服务、价值释放六大专项行动。核心逻辑很明确:面向人工智能应用需求,持续推进文本、图像、音视频等多模态高质量数据集建设;聚焦智能体、具身智能和世界模型等重点方向,加快推进数据集建设;引导具备条件的地区因地制宜开展数据标注创新试验区建设。
AI大模型时代,数据从「燃料」变成「战略资产」
过去几年,大模型训练的重点是「重点优化模型架构」。现在范式已经变了,转向「模型与数据协同优化」。数据不再是一次性收集处理后就束之高阁的静态文件,而是需要持续投资、管理、监控和优化的动态资产。
这种转变背后有几个关键变化:
自动化数据处理流水线取代手工作业。用可编程、可扩展的数据处理流程,系统性处理海量数据,提升数据质量。这不是简单的工具升级,而是数据生产方式的根本变革。
领域专家直接整合到数据处理链条。拥有深厚行业知识的主题专家被用来定义数据标准、标注复杂案例、识别数据中的细微偏差,将领域智慧注入数据。医疗领域的肺结节检测模型,仅用1万多例数据和亚毫米级病灶边界勾画,就让早期肺癌筛查的假阳性率大幅下降。工业质检场景中,某企业通过合成数据生成10万种极端缺陷样本,弥补真实生产中罕见缺陷数据不足,缺陷识别覆盖率大幅提升。
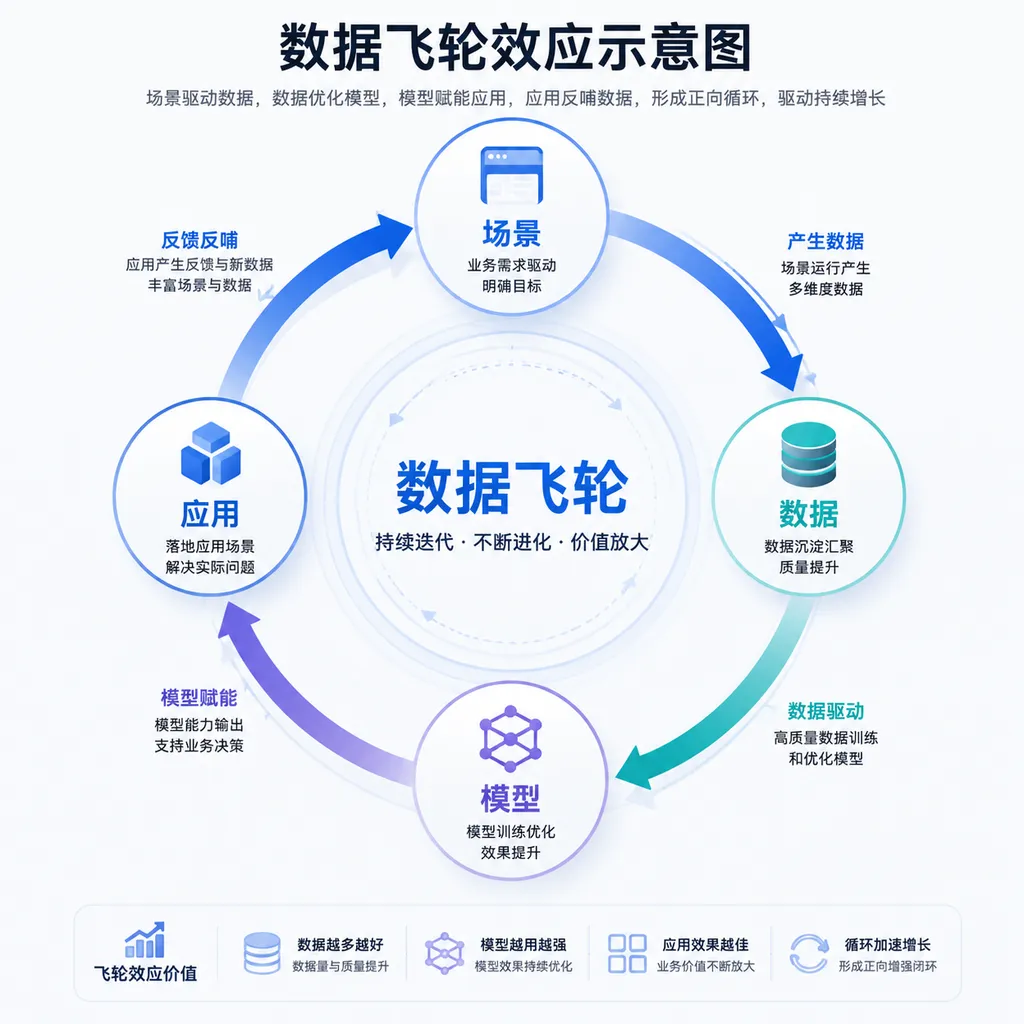
模型反馈闭环形成「数据飞轮」。把模型在实际应用中的错误作为诊断信号,发现数据中的问题(标签错误、数据分布不均、边界案例缺失),然后有针对性地改进数据集。更好的数据训练出更好的模型,更好的模型反过来帮助获得更好的数据。
OpenAI和DeepSeek的成功都验证了这个逻辑。OpenAI通过强化微调等技术,依托小规模但高度精准、精细化、结构化的数据集,实现大模型在垂直领域的专业化。DeepSeek的R1模型在复杂逻辑推理任务中突破,源于其采用的数学推理数据集不仅要求答案正确,更对解题步骤的规范性、逻辑链的完整性提出严格标准。
数据标注从「人海战术」到「专家+AI协同」
数据标注是将知识和经验注入到训练数据的过程,是数据集建设不可或缺的关键环节。方案推动数据标注从以人为主向人机协同、专家深度参与的多层次标注模式转变。
具体怎么做?
发展智能化标注服务。采用「模型预标注+人工校准」、「人工标注+模型检验」、「模型预标注+模型检验」等模式,提升标注效率和质量。这不是简单的自动化,而是人类经验与AI能力的深度融合。
建立专家型标注体系。建立行业专家认证注册机制,推动专家深度参与指令微调、强化学习等阶段的专业知识标注,生产逻辑推理、领域知识等高质量数据集。医疗影像标注需要影像科医生,法律文本标注需要执业律师,工业缺陷检测需要质检专家。
梯次布局数据标注创新试验区。首批七个承担数据标注先行先试任务的城市持续做强做深。面向创新能力强、发展基础好、产业特色优的地区,梯次布局试验区。方案特别强调避免一哄而上,防止同质化、低水平重复建设。
人才供给也在同步推进。支持院校增设数据标注相关课程,依托产教融合、校企协同培育专业人才。开展数据标注职业技能等级认定,畅通人才发展通道。建设专职与兼职相结合的专业标注人才队伍。
六大专项行动,构建从供给到价值释放的完整链条
方案部署的六大专项行动覆盖数据全生命周期:
强基扩容行动聚焦科学研究、工业制造、医疗卫生、金融服务等18个重点领域,以及低空经济、具身智能、智能驾驶等创新领域,体系化推进数据集建设。梳理数据资源底数和应用场景,建立数据资源清单和数据集需求清单。强化链主单位牵引带动作用,推动产业链上下游协同共建。
标注攻坚行动就是前面说的智能化标注和专家标注体系建设。
提质增效行动推动构建符合结构完整性、内容多样性、标注准确性、模型适配性等质量标准的数据集。加强数据清洗、增强、标注、对齐、质检等关键技术攻关。针对行业特定场景,运用数据智能过滤与配比技术,构建高知识密度数据集,降低训练推理成本。发挥数据合成作用,解决稀缺场景数据集构造难、真实场景数据采集成本高的问题。
应用赋能行动打造「场景—数据—模型」协同发展的良性循环。以模型应用牵引数据供给,以数据驱动模型迭代。打造集「数据集生产加工和流通利用、支撑模型训练应用」于一体的数据赋能工场。打造「数据×智能体」示范工程,树立高质量数据集成功驱动智能体解决实际问题的样板。
管理服务行动加强覆盖数据采集、处理、标注、质检、测评、迭代、审计等全生命周期的管理服务能力建设。建设「物理分散、逻辑集中」的国家数据集管理平台,实现数据集目录、供需等信息互联互通。支持地方、行业依托国家平台设置专区,支持已有平台与国家平台对接。
价值释放行动推动数据集商业化、资产化,培育为数据付费的市场共识。发展「订阅模式」、「商场模式」、「定制模式」等多元服务形态。探索词元交易等新型交易模式,构建以词元为基础、可量化、可定价的数据集价值体系。探索数据集质押融资、作价入股、资产证券化等多元化资产化创新模式。
目标明确:2028年数据产业年均增速超20%
方案设定的目标很具体:到2028年底,建成一批覆盖重点领域、经过应用验证的行业高质量数据集,打造300个以上示范性强、显示度高、带动性广的典型应用场景,培育一批创新能力强、成长性好的数据商和第三方专业服务机构,数据产业年均增速超过20%,数据交易规模倍增。
这个增速目标不低。作为对比,2024年中国数字经济增速约10%。数据产业要实现两倍于数字经济整体的增速,意味着从数据供给、流通到应用的整个链条都要实现跃升。
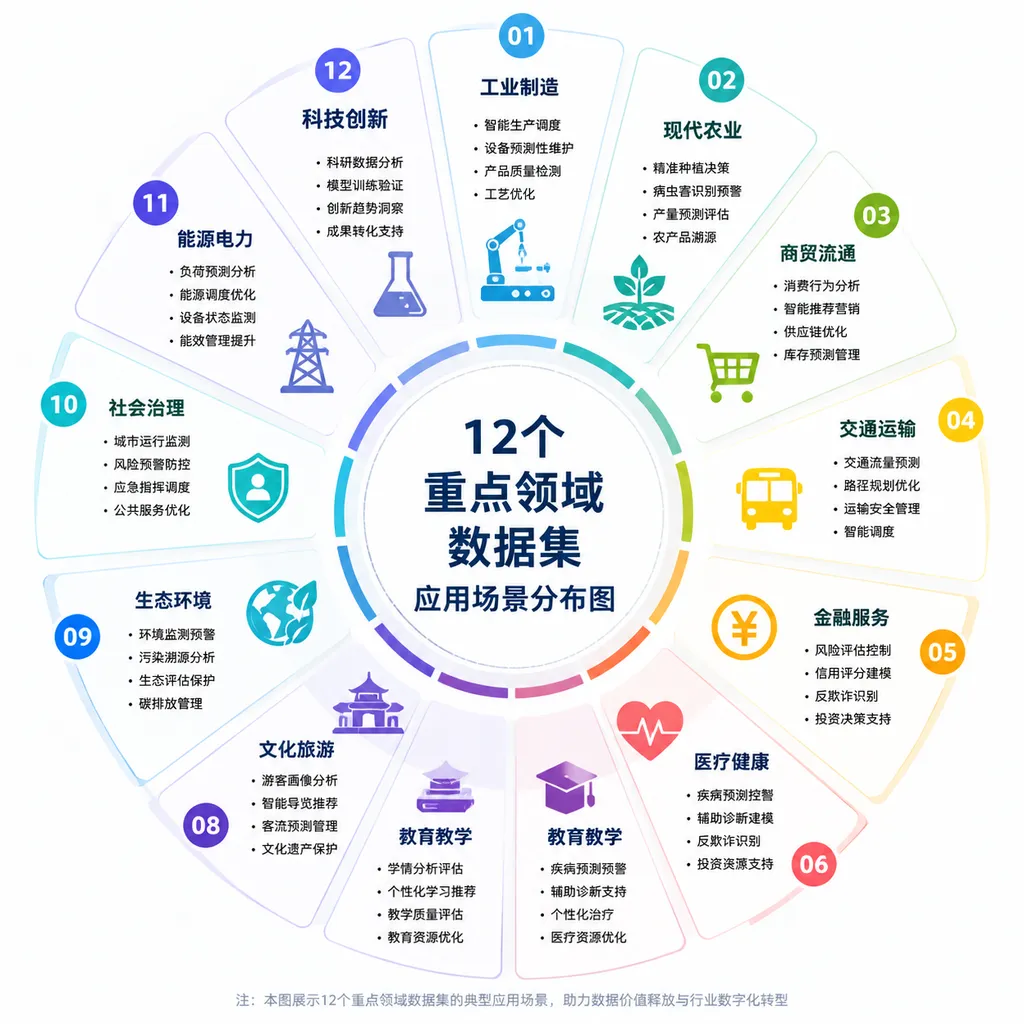
具体到应用场景,方案列出了12个重点领域的数据集应用需求,从工业制造到智慧农业,从商贸流通到科学研究。每个领域都有明确的数据融合应用方向。比如工业制造领域,支持企业融合设计、仿真、实验验证数据,培育数据驱动型产品研发新模式;推动产能、采购、库存、物流数据流通,提升产业链供应链监测预警能力。
医疗卫生领域,探索推进电子病历数据共享,在医疗机构间推广检查检验结果数据标准统一和共享互认;加强中医药预防、治疗、康复等健康服务全流程的多源数据融合,推进中医药高质量发展。
交通运输领域,推进货运寄递数据、运单数据、结算数据等共享互认,实现多式联运一次委托、一次结算;支持自动驾驶汽车在特定区域、特定时段进行商业化试运营试点,打通车企、第三方平台、运输企业等主体间的数据壁垒。
三个关键问题:数据权益、安全合规、价值分配
方案也直面几个核心问题:
数据权益配置。按照数据持有权、使用权、经营权三权分置原则,明确数据集产权配置方案。在保障合法权益前提下,适度拓展版权合理使用边界。兼顾产权保护与创新发展需求,在AI训练阶段探索弹性监管体系。这个表述很微妙,实际上是在AI训练使用版权数据这个全球争议话题上,给出了中国方案的探索方向。
安全合规底线。坚持伦理先行与公平普惠,研究探索高质量数据集伦理道德规范,严禁非法收集或使用敏感数据。防范数据集建设全流程产生数据偏见与歧视。强化安全保障,建立全流程安全治理机制,防范数据投毒、数据篡改、数据泄露等风险。
价值分配机制。建立健全市场化利益分配机制,确保数据供给、加工、流通、应用等各环节主体均能获得市场化价值回报。充分发挥政府部门、国有企业、模型企业等单位的示范引领作用,推动数据采买纳入预算编制,率先开展数据采购实践,带动形成数据有偿使用市场共识。
最后这一点很关键。当前AI行业对训练数据的付费意愿普遍不高,大量依赖互联网公开数据。要建立健康可持续的数据生态,必须让数据供给方获得合理回报。方案明确提出培育为数据付费的市场共识,并要求政府部门、国企带头示范,这是在用政策和资金引导市场行为转变。
对开发者意味着什么?
这个方案对AI开发者和企业有几个直接影响:
高质量行业数据集供给会显著增加。过去你想训练一个垂直领域模型,数据采集和标注是最大的瓶颈。现在国家层面推动18个重点领域的数据集建设,意味着工业制造、医疗、金融、交通等领域会有更多高质量、标准化的数据集可用。
数据标注服务会更专业、更智能。如果你的项目需要专业标注,未来能找到的不只是按件计费的标注工人,而是懂行业、用AI辅助的专业标注团队。标注质量和效率都会提升,成本有望降低。
数据合规和流通会更规范。方案推动建立覆盖数据全生命周期的管理服务体系,运用隐私保护计算、可信数据空间等技术,让数据在可管、可控、可追溯的前提下流通。这对需要多方数据融合的项目是利好。
数据付费会成为常态。如果你是数据供给方,这是好消息——你的数据资产有望获得市场化回报。如果你是数据需求方,要做好付费采购数据的预算准备。免费午餐会越来越少。
智能体和具身智能场景会迎来数据红利。方案明确聚焦智能体、具身智能、世界模型等前沿方向,加快复杂任务规划、长程推理、人机交互、决策执行、物理交互、环境感知、运动控制等数据集建设。如果你在做这些方向,未来会有更多针对性的数据集支持。
从「数据大国」到「数据强国」的关键一步
中国不缺数据。我们有全球最大的互联网用户规模,最丰富的应用场景,最完整的工业体系。但长期以来,数据资源「大而不强」——数据质量参差不齐,标注标准不统一,流通机制不畅,价值释放不够。
这个方案是要系统性解决这些问题。它不是简单地要求各部门各地方建数据集,而是从顶层设计出发,构建从数据供给、标注加工、质量测评、流通交易到应用赋能、价值释放的完整体系。
更重要的是,它把数据集建设与AI应用深度绑定,打造「场景牵引数据、数据驱动模型、模型赋能应用、应用创造价值」的数据飞轮。这种思路跳出了过去「先建数据库再找应用」的路径依赖,而是让应用需求倒逼数据供给,让模型反馈优化数据质量,形成真正的闭环。
从全球竞争格局看,美国在高质量数据集建设上起步更早,OpenAI、Anthropic等公司在数据工程方面积累深厚。欧盟通过GDPR等法规建立了严格的数据治理体系。中国这次从国家层面系统部署,发挥制度优势和超大规模市场优势,有机会在数据要素与AI协同发展上走出自己的路径。
当然,方案落地还面临不少挑战。数据权益配置、跨部门跨地区数据共享、数据安全与利用的平衡、市场化价值分配机制的建立,每一项都不容易。但方向是对的,路径是清晰的,资源投入和政策支持也在跟上。
接下来两年半,看各地各部门如何把这个方案变成实实在在的数据集、应用场景和产业生态。300个示范场景、20%的年均增速、数据交易规模倍增,这些目标能不能实现,将直接影响中国AI产业的发展质量和国际竞争力。
参考来源
- 国家数据局官网 - 《关于推进行业高质量数据集建设行动的实施方案》 - 方案全文及配套文件
- 36氪 - 事关数据赋能人工智能发展,国家层面首次系统部署 - 方案发布快讯
- 国家数据局 - 高质量数据集建设指引(PDF) - 数据集建设技术指引和行业案例


