Kimi 派出 300 个 Agent 去赌世界杯:多智能体推理的一次公开实战

月之暗面宣布用 Agent 集群同时调度 300 个子智能体,并行预测 2026 美加墨世界杯全部 104 场比赛,并公开复盘。一个发现是:德国队的夺冠概率可能被市场低估。
6 月 8 日,2026 美加墨世界杯开幕在即。月之暗面今天扔出一个略带"行为艺术"色彩的项目:用 Kimi 的 Agent 集群(Agent Swarm)公开预测这届扩军到 48 队、总计 104 场的世界杯赛事,每轮赛前出预测,赛后做复盘,错了也认。
这不是发个 PPT 的事。Kimi 把自己 1 月发布、4 月在 K2.6 上做过一次大升级的 Agent Swarm 架构,直接拉到一个所有人都能验证对错的场景里——足球比赛的结果是不能 PR 的。
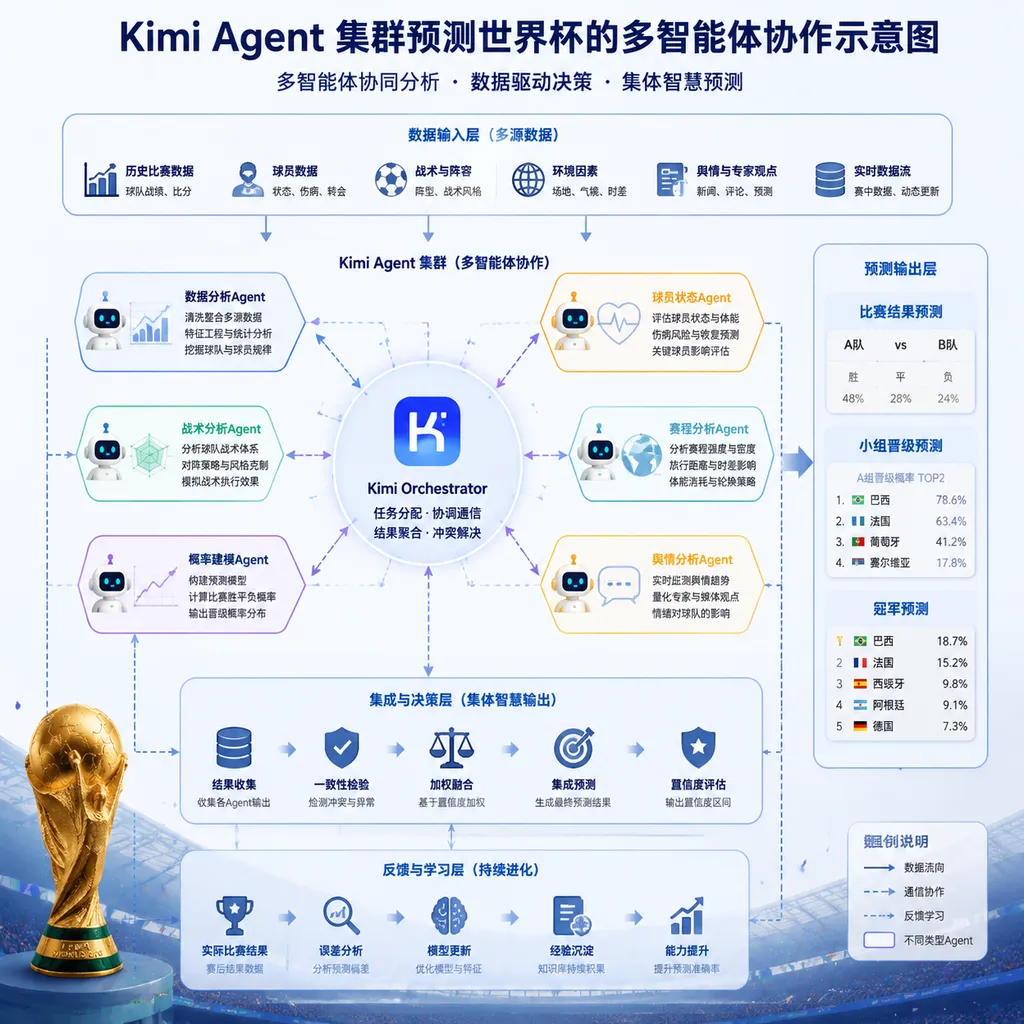
一次性 300 个子 Agent 同时开工
按 Kimi 官方的说法,这次预测的运行方式是:主 Agent 监督 15 个左右的关键步骤,下面最多可调度 300 个子 Agent 并行推理,整个工作流可以拉到 4000 步的量级。每个子 Agent 拿一个独立视角去啃同一场比赛,最后把结论收上来融合。
视角是真的"分工到牙齿"的程度:
- 强度派:盯 Elo 评分和 FIFA 排名,给两支球队一个底层的实力锚
- 数据派:用 xG(预期进球)、xT(预期威胁)去衡量球队进攻和防守的"质量",而不是只看比分
- 战术派:分析高位压迫 vs 低位防守、反击和定位球的相互克制
- 环境派:旅行距离、气候(美加墨跨纬度极大)、休息天数
- 阵容派:跟踪伤病、停赛、主力出场时间
- 市场派:盯赔率和隐含概率的偏离,找 model-vs-market 的 gap
- 黑天鹅派:评估红牌、点球、VAR、门将临场发挥这种偏随机的因素
每个子 Agent 提交的不是一个"我觉得 A 队赢",而是一个结构化的四元组:结论 + 证据 + 置信度 + 反方解释。最后汇总时,Kimi 明确表示不采用多数投票——这点挺关键,后面再说为什么。
这套架构到底有什么不一样
要理解为什么 Kimi 要把这件事拿来做公开演示,得回到 Agent Swarm 本身的设计哲学。
传统的多智能体系统,多数是人手工搭工作流:你预先定义好"调研员"、"分析师"、"写作者"几个角色,定好谁调用谁、什么时候调用,本质上是用 LLM 当螺丝刀去拧一个流程图。
Agent Swarm 走的是另一条路——让模型自己决定要不要并行、雇谁、怎么分工。月之暗面团队讲过一个起源故事:一位成员当时想让 Kimi 帮自己每天扫股票,写到 100 行 if-else 时突然意识到:"我在手写一个多智能体系统,为什么不让模型自己写?"
这个想法在工程上的兑现,就是用 PARL(Parallel-Agent Reinforcement Learning)这种并行的 RL 方法去训练编排器(orchestrator),让它学会判断哪些子任务可以铺开、铺多大宽度、什么时候该收。子 Agent 是冻结的,编排器是可训练的——一个会指挥的脑袋,配一群干活的手。
效率上的收益看官方数据:相比单 Agent 顺序执行,关键步骤减少 3 到 4.5 倍,端到端时间在大型搜索任务上最高缩短 4.5 倍。BrowseComp 这种深度信息检索 benchmark 上的提升尤为明显。
世界杯预测刚好是这个架构的"舒适区":
- 任务高度可并行:104 场比赛之间几乎无依赖,每场又能拆成十几个独立维度
- 信息源极度分散:球队官网、伤病新闻、博彩公司赔率、气象、社媒舆情,靠单 Agent 一个个爬要爬到决赛结束
- 结果可验证:90 分钟后就有 ground truth,不像写报告那样需要主观打分
不是一个模型,是一堆模型的合议
看到"AI 预测足球"四个字,很容易以为就是丢进 LLM 让它吐个结果。Kimi 这次披露的方法栈比想象中要硬核:
- Elo / FIFA 强度模型:给球队打基础分
- Poisson / Dixon-Coles 进球分布模型:足球预测里几十年的经典方法,建模进球数的概率分布
- xG / xT 指标体系:现代足球数据分析的事实标准
- 机器学习增强模型:在传统统计模型基础上做残差修正
- Monte Carlo 模拟:跑出大量赛果分布,特别用于淘汰赛阶段的递推
- 市场-模型偏差分析:把博彩市场的隐含概率作为一个外部信号源,识别系统性偏差
- 贝叶斯动态更新:每轮比赛打完,先验跟着更新
LLM 在这里不是"裁判",更像一个统筹工——分发任务、调用合适的方法、收集证据、做不确定性的语言化表达。这套组合的价值,按 Kimi 自己的话讲,"不在于消除不确定性,而在于更系统地识别不确定性"。
这种态度其实蛮难得。多数 AI 演示项目都在拼"我的模型多准",Kimi 这次反复强调的反而是"我们会错":
- 高置信度预测,历史回测准确率 85%–90%
- 中等置信度,55%–65%
- 低置信度,接近随机
言下之意——只要题目难度上去了,AI 不会突然变神。这话对开发者比对吃瓜群众有用得多。
德国队那段为什么值得拎出来说
各家主流模型目前给西班牙和法国挂的夺冠概率最高,Kimi 也认同这俩是第一梯队。但它的集群在跑完之后冒出一个观察:德国队的夺冠概率可能被市场低估。
这句话乍一看像标题党,仔细看 Kimi 的措辞——"模型识别到了一个可能存在的概率偏差,值得公开记录和后续验证"——其实是个非常 Bayesian 的表达。
它说的不是"德国会赢",而是"市场赔率隐含的概率,和我们模型算出来的概率之间,存在一个值得标注的 gap"。这恰恰是 Agent Swarm 不采用多数投票的价值体现:如果走投票,一个明显的"少数派 + 强证据"的结论会被多数派淹没;而强制每个子 Agent 给出反方解释、最后做加权融合,少数派意见反而有机会浮出水面。
从架构层面,这是 Kimi 在帮助文档里反复提到的一点——Agent Swarm 可以"从结构上避免群体思维(Groupthink)"。换到金融、医疗诊断、产品决策这些更严肃的场景,少数派意见的可见性可能比"算得快"重要得多。
给开发者的几点观察
抛开世界杯本身的趣味性,这次 demo 里有几个对做 Agent 应用的同学比较有参考价值的点:
1. 并行的边界在哪。 300 个子 Agent 听上去很猛,但实际上不是所有任务都能这么拆。Kimi 在文档里反复强调"关键步骤"这个概念——衡量并行有没有真的省时间,看的是关键路径上的步骤数,而不是总调用数。盲目拆任务只会增加协调开销。
2. 子 Agent 不需要都很强。 Swarm 的子 Agent 是冻结模型,强的是编排器。这其实是个工程上很务实的判断:大规模并行时,子任务通常都不复杂,让一个被 RL 训练过的"指挥官"做好分工,比让每个执行单元都顶配要划算得多。
3. 输出结构化是基础工程。 强制每个子 Agent 给出 结论 / 证据 / 置信度 / 反方 的四元组,看起来是产品设计,实际上是让上层融合算法能做的事——没这个结构,主 Agent 就只能"看感觉"加权。
4. 不确定性的语言化是产品力。 把 60% 的概率说成 60%,比说"很可能"重要得多。世界杯预测这件事公开做出来,最大的看点之一就是:能不能让一个大模型驱动的系统,长时间保持概率语言的纪律。
顺带一提,Kimi K2.6 模型本身是开源的,Agent Swarm 这套架构目前是月之暗面在自家平台上的 Beta 能力,给 Allegretto/Allegro 会员开放。如果想在自己的应用里同时调用 Kimi 以及 GPT、Claude、Gemini、DeepSeek 等模型做对比实验,OpenAI Hub 这类聚合平台用一个 Key 走 OpenAI 兼容格式直连国内可用,省去配多套 SDK 的麻烦。
接下来看什么
世界杯 6 月开赛,到 7 月中旬决赛,Kimi 会公开每一轮的预测概率和赛后复盘。这件事的看点不在于它最后猜中了几场——按它自己说的回测数据,肯定会错一堆——而在于:
- 高置信度预测的实际命中率,能不能撑住 85% 这个区间
- 集群发现的"被低估的德国"这类反市场结论,事后看是有效信号还是噪声
- 当淘汰赛阶段不确定性骤增、样本变少时,贝叶斯更新能不能稳定收敛
这些问题的答案,比任何一份 benchmark 都更能说明:把多智能体推理放到真实世界里到底有多顶用。一个月后我们会知道。
参考来源
- IT之家:用 AI 猜胜负,Kimi 官宣将公开预测 104 场世界杯赛事 — 本次 Agent 集群世界杯预测项目的官宣报道
- 知乎:Kimi Agent Swarm 如何实现 100 个 AI 智能体同时工作 — Agent Swarm 架构与 PARL 训练方法的中文解读


