SILX AI 抛出 Quasar-Preview:18B MoE 撑起 500 万 Token 上下文

SILX AI 今日开源 Quasar-Preview,18B 总参/2B 激活的 MoE 架构搭配实验性 5M 上下文窗口,明确表示不参与刷榜,目标是把一套面向长记忆系统的混合架构公开给社区检验。
今天 SILX AI 把酝酿已久的 Quasar 系列基础模型推出了第一版公开预览——Quasar-Preview,直接以 MIT 协议丢上 Hugging Face。和最近几个月动辄宣称"刷爆榜单"的发布不同,SILX 这次开门见山地告诉所有人:这玩意儿不是来打榜的,是来验架构的。
这种坦白其实挺少见。过去一年里,从 DeepSeek-V4-Pro 到百度文心 5.1,再到智谱 GLM-5.1,国内一线团队的发布会基本都在卷分数、卷激活参数效率、卷价格。而 SILX 选了一条相对学术的路:把一套还没跑完训练的混合架构提前开源,让研究者自己拿去拆。
18B 总参、2B 激活,但重点不在这里
先把规格拉一遍:
- 总参数:约 18B,混合专家(MoE)架构
- 激活参数:2B 级别
- 上下文窗口:实验性 5M Token
- 训练 Token:当前累计 1T–1.5T,其中长上下文扩展路径不足 1B
- 协议:MIT,完全开源
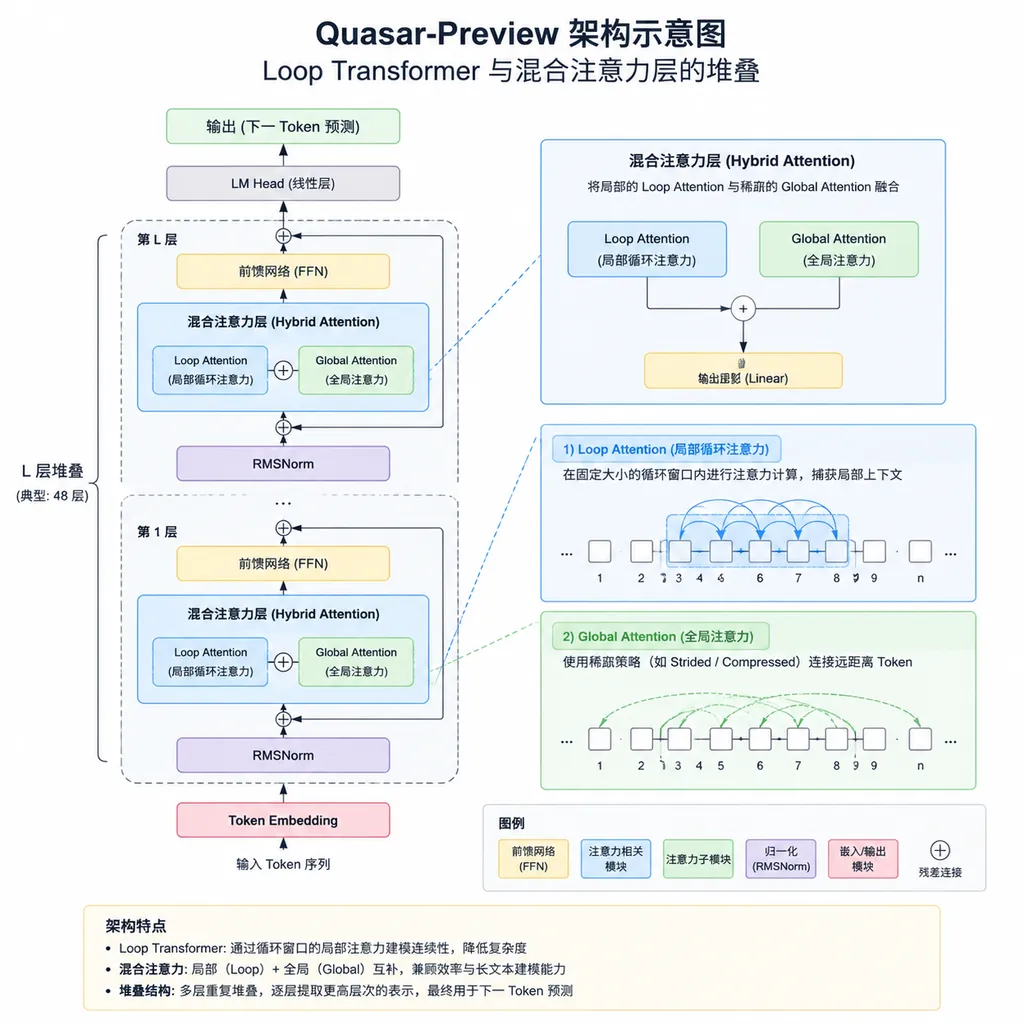
18B/2B 这个组合放在 2026 年并不算稀奇。Qwen3、DeepSeek 系列、甚至快手前阵子开源的 Keye-VL-2.0-30B-A3B,都在玩"小激活撑大模型"的把戏。真正值得拉出来单说的是后面那串架构名词:Loop Transformer + Quasar 混合注意力 + Quasar/Raven/GLA 混合层 + 稀疏 MoE 路由。
这套搭配看着挺花,但目标只有一个——让长上下文不再是"塞进去就完事"的伪能力。
5M 上下文,怎么实现、又意味着什么
5M Token 这个数字得拆开看。它不是简单地把 RoPE 频率拉一拉、然后宣布"支持"。SILX 用的是 Safe NoPE / DrOPE 风格的阶段性扩展方法——一种近年在长上下文研究里逐渐被验证的路径,核心思路是分阶段地把位置编码"退化"或者"丢弃",让模型在超长序列下不至于在位置先验上崩盘。
对比一下行业坐标:
- 2024 年 3 月,Kimi 把无损上下文做到 200 万字时,业界已经觉得是"数量级突破"
- Gemini 系列长期把上下文卡在 1M-2M 区间
- 快手 Keye-VL-2.0 这种新世代多模态模型,256K 已经算"超长"
Quasar-Preview 直接报出 5M,听上去夸张,但 SILX 自己写得很清楚:长上下文扩展路径目前只灌了不到 1B Token。换句话说,这个 5M 现在更像是架构上能跑通的容量上限,而不是工程意义上的"可用质量"。
这也是为什么官方反复强调一句话:Preview 不代表 Quasar 的最终质量。
Loop Transformer 与混合注意力:押注"内存系统"
架构选型里最值得玩味的是 Loop Transformer。这是一个相对小众但思路独特的方向——通过循环展开的方式,让同一组参数在推理时反复处理同一段上下文,从而在不增加参数量的前提下榨取深度。
配合 Quasar 自研的混合注意力,加上 GLA(Gated Linear Attention)这种已经被多家团队验证过的线性注意力变体,整体的取舍逻辑就比较清楚了:
- 稀疏 MoE 负责拓宽容量——18B 总参提供知识广度
- GLA 等线性注意力负责拉长上下文——把 5M 这件事在显存上跑通
- Loop Transformer 负责加深推理深度——在不堆参数的前提下增强推理
- Quasar/Raven 混合层负责保留全注意力的精度——避免完全线性化后的能力损失
说白了,SILX 想要的是一个为基于记忆的系统(memory-based systems)量身定制的底座。这跟当下 Agent、长程任务、个人助理这类应用的实际需求是对得上的——你不需要模型每次都重新理解 500 万 Token,你需要它能把一段超长状态"装进去",然后在循环里反复访问。
训练量只有 1.5T Token,意味着什么
参考当下旗舰级开源模型的训练量动辄 10T-20T Token 起步,Quasar-Preview 现在的 1T-1.5T 显然处于"早期"阶段。SILX 自己列出的下一步 roadmap 也印证了这一点:
- 迭代式子网训练与知识蒸馏
- 更长的训练周期与更强的后训练
- 进一步的长上下文扩展训练以及架构更新
从工程节奏看,这个 Preview 更像是一份**"架构白皮书的可执行版"**。研究者可以拿去做 ablation、可以测注意力机制的失效模式、可以验证 Loop Transformer 在 MoE 路由下的稳定性——这些都是论文里跑不动、但工业训练里又值得验证的东西。
跟最近这一波"小激活 MoE"放在一起看
2026 年到目前为止,开源圈的主旋律有两条:一是激活参数越来越小(DeepSeek-V4-Pro 直接把 API 价格砍到原定价的 1/4,背后就是激活效率的红利),二是上下文越拉越长(快手 Keye 的 256K、智谱 GLM-5.1 系列对长文本场景的强化)。
Quasar-Preview 同时押了这两条,但走得更激进:
| 维度 | 主流做法 | Quasar-Preview | |------|---------|----------------| | 激活参数 | 3B-7B | 2B | | 上下文 | 128K-1M | 5M(实验性)| | 注意力 | 全注意力 + 稀疏 | Quasar/Raven/GLA 混合 | | 深度策略 | 堆层 | Loop Transformer 循环 | | 训练成熟度 | 充分预训练 | 1T-1.5T 早期 |
这个对比也解释了为什么 SILX 反复给自己降预期——同时押 4 个未充分验证的方向,意味着这个模型在零样本基准上大概率打不过同体量的成熟模型。但作为一份开源给社区拆解的架构原型,它的信息量比一个跑分高 2 分的常规模型大得多。
给开发者的几条实用建议
如果你今天就打算把 Quasar-Preview 拉下来玩,几个心理预期得先调好:
- 别拿它跟 GPT、Claude 比对话质量——训练量摆在那
- 5M 上下文可以试,但别指望它在 4M 之后还保持稳定的检索能力——长上下文路径才喂了不到 1B Token
- 架构验证价值 > 直接落地价值——更适合做 research 和 finetune 起点,而不是直接上生产
- 关注后续版本的迭代节奏——MIT 协议加完全开源,意味着这个系列大概率会有 v0.2、v0.3 持续放出
对国内开发者来说,模型可以直接从 Hugging Face 拉取权重做本地推理;如果你日常用的是聚合类 API(比如 OpenAI Hub 这种一个 Key 调 GPT、Claude、Gemini、DeepSeek 的平台),Quasar 这种早期开源模型大概率短期内不会上托管,等它训练量爬到可用区间再说。
写在最后
2026 年的大模型发布会越来越像一场预先编排好的剧本——发布、跑分、PR、降价、API、开源。Quasar-Preview 在这个语境里其实显得有点"不合时宜":它没有刻意美化的 benchmark,没有令人惊艳的 demo,甚至连训练都还没跑完。SILX 选择把一个半成品丢出来,赌的是社区对架构本身的兴趣。
这种赌法不一定能赢,但起码诚实。对一个想做"内存原生"的模型系列来说,把 5M 上下文的实验路径公开,让研究者帮自己验证那些训练成本太高、单个团队跑不完的方向——这条路其实比闷头训到 10T Token 再放一个 "Quasar-1.0" 出来要聪明得多。
至于这个架构能不能成、Loop Transformer 在 MoE 上有没有戏、5M 上下文是不是真能落地——答案得等 SILX 把训练量灌到 10T 以上再说。今天这个 Preview,只是把那张牌摊开给所有人看了一眼。
参考来源
- SILX AI 正式发布 Quasar-Preview:18B MoE 架构的早期预览版 拥有 5M 上下文长度 - linux.do — 本次发布的中文社区原始讨论帖,包含完整规格说明
- silx-ai/Quasar-Preview · Hugging Face — 模型权重与官方说明,MIT 协议开源
- AI 早报 2026 长上下文模型整理 - 知乎 — 近期 MoE 与长上下文模型的横向参考


