清华团队搞了个能读心率的基座模型,给机器装上「读人」的眼睛

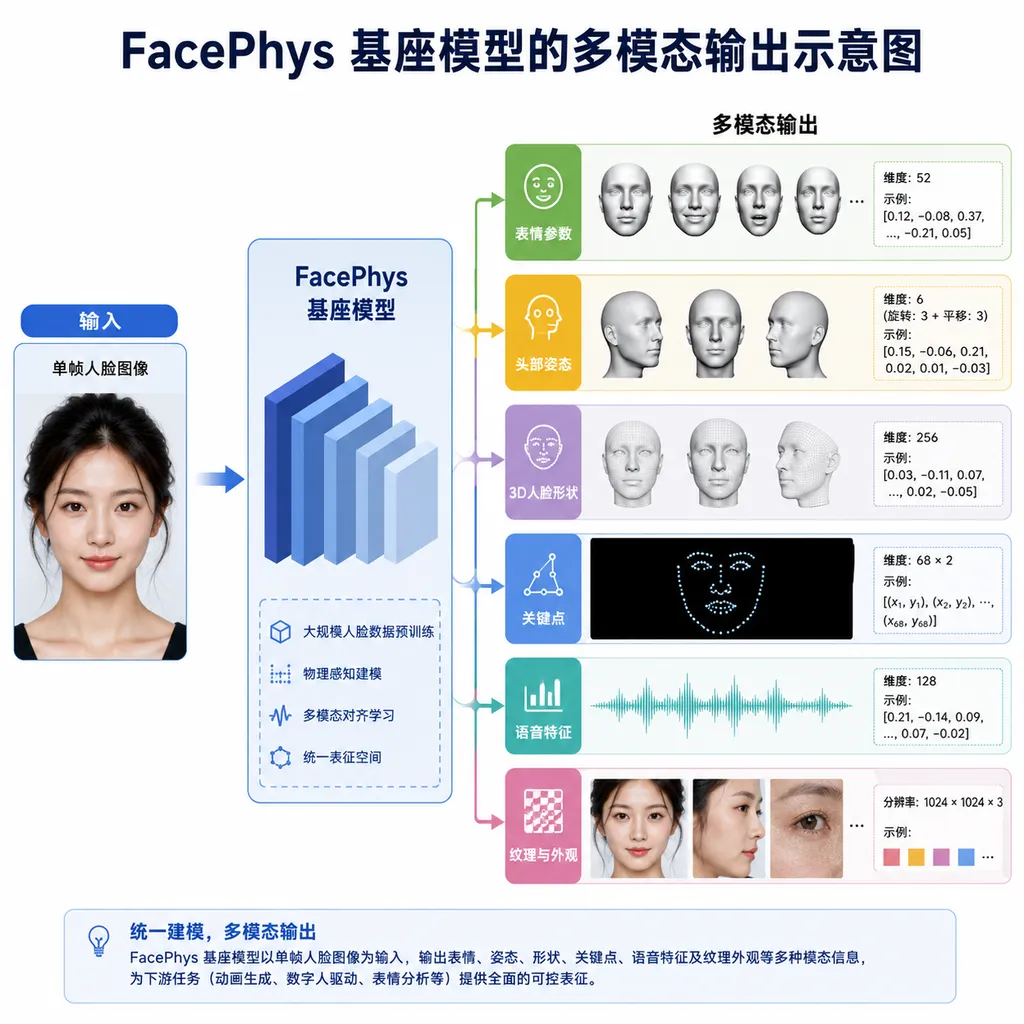
微面科技推出 FacePhys,全球首个实时输出生理与情绪指标的基座模型,靠普通摄像头就能在 10ms 内吐出 120+ 项人体状态参数,刚拿到顺为数百万美元融资。
一个清华博士生团队,决定给机器人装上一双能「读人」的眼睛。
6 月 10 日前后,北京微面科技(FacePhys)完成数百万美元融资,顺为资本领投。这家公司做的事情,用一句话概括:让一颗普通摄像头实时看出你的心率、呼吸、心率变异性,再结合表情眼动判断你是真笑还是假笑、是不是已经累到极限——而且全程不接触、本地端侧推理、延迟低于 10 毫秒。
他们把这个能力打包成了一个基座模型,叫 FacePhys,号称是「全球首个实时理解生理与情绪的基座模型」。这个 claim 不算虚——rPPG(远程光电容积描记)这条技术线学术界搞了十几年,但能把心率精度做到医疗级、把模型压到 0.2M 参数跑在普通手机上、并且按照基座模型的范式去训练的,目前确实少见。
AI 交互的隐形天花板,是「看不见你」
先聊聊这事的底层逻辑,为什么现在突然有人在做这个方向。
过去两三年大模型的演进有个明显的偏科:语言能力暴涨,视觉理解也在追,但对「人本身」的感知近乎为零。你跟 ChatGPT 聊天,它不知道你此刻在生气还是焦虑;具身机器人能识别你做了什么动作,但读不出你心里在想什么。研究里有个常被引用的数字——人类表达中 55% 是非语言信息。这部分对现在的 AI 来说基本是黑箱。
结果就是,所有 AI 交互都极度依赖用户的「显性输入」。你不打字、不说话、不做明显的动作,模型就只能干等。这种被动响应的范式,本质上限制了 Agent 也好、机器人也好的「主动共情」能力。
微面科技的判断是:要打破这个天花板,得给大模型补一个「生理情绪数据入口」。换句话说,先让机器看懂你这个人,再谈交互。
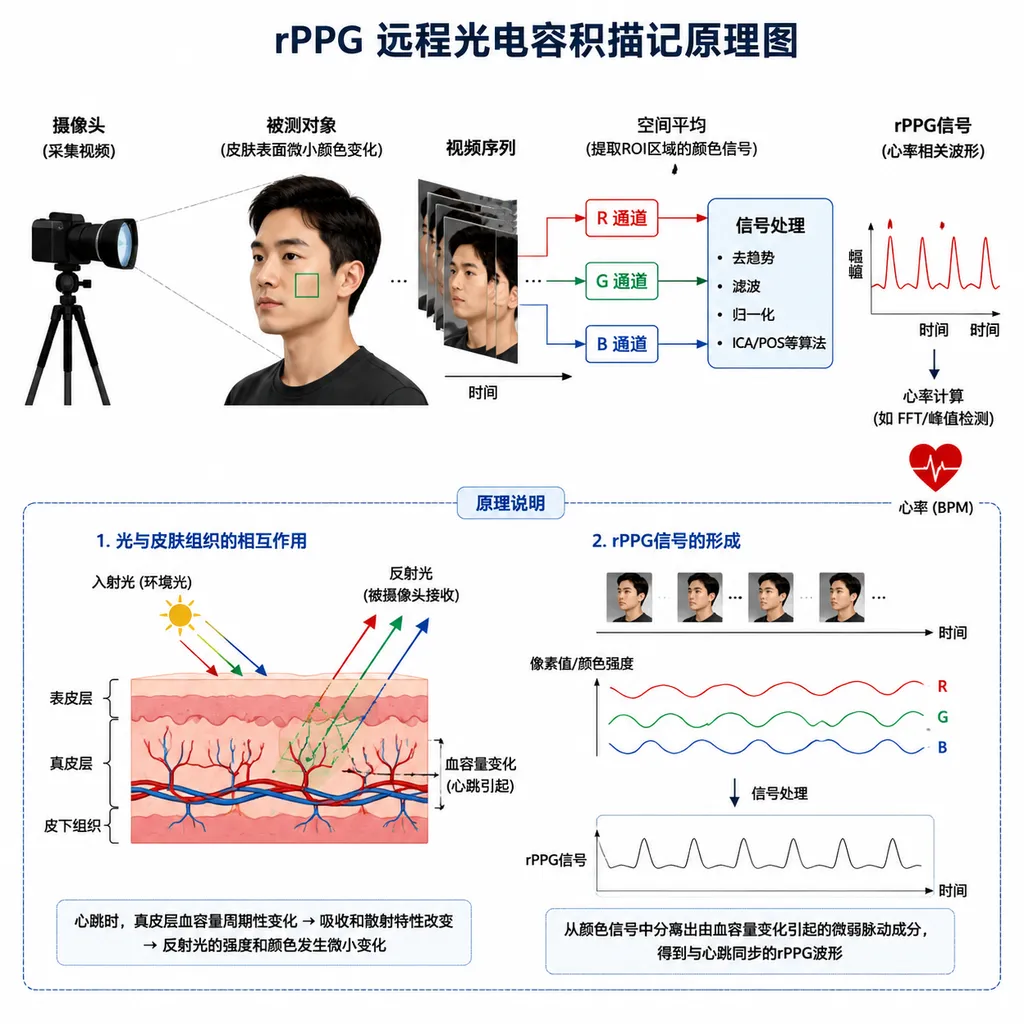
rPPG 不是新东西,难的是把噪声打掉
远程光电容积描记(rPPG)的原理其实挺巧妙。心脏每跳一次,血液流过皮肤微血管,会让皮肤反射光发生周期性变化。变化幅度极小,人眼看不出来,但摄像头能捕捉到。把这个信号提出来,就能反推心率、呼吸率、血氧。
听起来简单,做起来全是坑。这套信号的强度只占总背景光的 0.1%–1%,稍微有点干扰就被淹没。微面科技创始人唐健凯在采访里直接说过:「实验室里很完美,一到现实环境,人稍作移动、光照一变,精度就大幅下降。」
他们解决这个问题的路径有两条:
第一条是堆数据。团队搞了一个万人级临床标注数据集,数千万采样点,覆盖不同肤色、不同光照、不同运动状态,又拉着安贞医院做了上千人规模的临床队列验证。这种数据规模在 rPPG 学术圈里是少见的——大多数论文还在用几百人的公开数据集刷分。
第二条是模型范式的切换。这是更有意思的地方。他们把「状态空间模型」(State Space Model)引入了生理信号建模。
唐健凯把这个类比讲得很清楚:大语言模型预测下一个 Token,FacePhys 预测的是「人体下一时刻的生理行为状态」。心跳不再是被切成离散视频帧的拼接,而是被建模成一个连续的物理过程。这种建模方式对时间动态特征的捕捉更准,也更符合心脏搏动本身的物理规律。
这套思路最终交出的数字:
- 心率检测误差 < 0.7 BPM(团队公布的最新数据),已达医疗级标准
- 端侧推理延迟 ≤ 10ms
- 端侧小模型参数量 0.2M,可直接跑在普通手机和摄像头上
- 单帧实时输出 120+ 项指标,覆盖心率、HRV、呼吸率、面部动作单元(AU)、眼动特征、情绪维度、语音特征
0.2M 这个参数规模值得多说一句。现在动辄数十亿参数的视觉模型扎堆,把生理感知能力压到这个量级、还能在端侧实时跑,意味着它具备成为「标准化感知组件」的工程基础——而不是又一个只能跑 demo 的研究项目。
关键武器:HRV 情绪生理晴雨表
光测心率没什么稀奇,市面上的智能手表都能干。FacePhys 真正想做的是「读情绪」,而它的杀手锏叫HRV 情绪生理晴雨表。
HRV(心率变异性)指的是连续心跳间隔的微小时间变化。这个指标在医学界已经被反复验证——它是自主神经系统功能的非侵入式指标,跟抑郁、长期压力呈显著负相关。简单说:一个长期处于高压、情绪压抑状态的人,HRV 通常偏低,而且这个值你装不出来。
FacePhys 把 HRV 跟急剧情绪绑定,再叠加面部动作单元和眼动数据,可以做到一件之前的情绪识别系统做不到的事——区分假笑和真笑、识别压抑情绪。
这个能力的价值在于它的「不可伪造性」。传统基于表情的情绪识别,本质上是在读你脸上的表演;HRV 读的是你身体的真实反应。当 AI 拿到的是「客观生理真相」而不是「主观表演」,整个交互的可信度就不一样了。
真正的目标客户:机器人
微面科技的商业化路径已经铺得比较开了:婴儿监护(红外补光夜间监测心率呼吸)、智能座舱(疲劳驾驶预警 + 车内婴幼儿监护,已有车企在下一代「健康汽车」集成)、医院临床(与安贞医院合作的「健康镜」)、以及个人 App 和浏览器版的实时监测系统。
但这些都是垂直场景,唐健凯真正押注的是机器人赛道。
他的逻辑是:服务机器人、康养陪护机器人、人形机器人,都迫切需要「读懂使用者生理状态与情绪意图」的能力。一个没有这个能力的机器人,就只能是个会动的工具人。FacePhys 想做的,是把自己变成机器人厂商的标准化感知模块——就像激光雷达对自动驾驶的角色一样。
这个判断在当下的时间点是讲得通的。2026 年人形机器人量产正在爬坡,但行业普遍卡在「机器人能干活,但不会看人脸色」。如果一个 rPPG 模组能让陪护机器人发现老人血氧异常、让服务机器人感知到用户的不耐烦——这种「软感知能力」是硬件参数堆不出来的。
微面目前给到行业的集成方案有三种:
- 云端 API/SDK:零硬件改动,两周对接,SaaS 订阅
- 整组模式:完整摄像头模组交付,算法固化到芯片,低延迟低功耗,适配旗舰量产
- 插件模式:串联现有摄像头,不改原有架构
这三档基本覆盖了从轻量试水到深度量产的全部场景。
一个 reality check
吹得差不多了,说点不那么乐观的。
rPPG 这个赛道学术界做了很多年,工业化落地一直不温不火,原因不光是技术——更多是商业模式。微面科技 2024 年也走过弯路,曾经做过一个对标海外的线上问诊抽成平台,结果撞上了中国医疗体系跟海外完全不同的现实:国内线下问诊效率高,轻问诊需求远不如美国。这一仗他们打输了。
后来的转向(深耕非接触生理情绪感知 + 给机器人做感知模组)方向是对的,但本质上是 to B 的硬件配件生意。这种生意的天花板取决于下游——如果人形机器人的爆发节奏不及预期,rPPG 模组的渗透率也会跟着卡住。
另一个潜在风险是隐私。一颗摄像头持续读你的心率、判断你的情绪,哪怕端侧不上传,用户的接受度依然是问号。微面强调端侧本地化部署、底层规避隐私泄露,这是必要的,但还不够——监管会怎么界定「非接触生理数据」的合规边界,目前是空白。
给大模型的启示
抛开微面这家公司本身,FacePhys 这套范式对大模型行业是有借鉴意义的。
过去两年,多模态大模型都在卷 vision-language,但视觉这一支基本停留在「物体识别 + 场景理解」。FacePhys 提供了一个新的视角:视觉模态里还有一层「生理信号」,它跟语言、图像是正交的信息。如果未来的基座模型能把这一层接进来,AI 对人的理解会上升一个维度。
想象一下,一个 Agent 在和你协作完成任务时,它能感知到你在某个步骤明显焦虑、于是主动暂停解释;一个陪伴机器人发现老人 HRV 持续偏低、情绪压抑,主动建议联系子女——这种「主动共情」的闭环,是单纯靠语言模型实现不了的。
FacePhys 走的是把这个能力做成「数据入口」、再嵌入大模型生态的路线。后续值不值得期待,关键看两点:一是它和主流大模型的接入会以什么形式发生(API?多模态对齐?),二是机器人厂商有没有意愿把它纳入标配。
顺便提一句,OpenAI Hub 这边一直在跟进多模态模型的接入,FacePhys 这类提供生理情绪输入的基座模型如果开放接口,也会是有价值的补充——让一个 Key 调到的不只是会说话的模型,还可能是会读人的模型。
这个方向比卷参数有意思多了。
参考来源
本文涉及的外部公开报道与研究素材来源于多家科技媒体的独家报道与采访资料,包括对微面科技创始团队的访谈、产品技术参数披露及融资信息。由于源链接受限,建议读者通过搜索「微面科技 FacePhys」「清华 rPPG 基座模型」获取更多一手资料。


