摩尔线程开源 MusaCoder:国产 GPU 跑出 KernelBench 93.2%

摩尔线程发布并开源 MusaCoder 代码大模型,含 9B 和 27B 两个版本,全链路训练在国产 MTT S5000 集群完成。在 KernelBench 上以 Pass@8 93.2% 击败 Claude Opus 4.7、DeepSeek-V4 Pro 等闭源 SOTA。
6 月 10 日,摩尔线程把一件不太容易的事干完了:发布并开源了 MusaCoder——一个专门用来"写 GPU 算子"的代码大模型。9B 和 27B 两个尺寸,权重已经挂上 Hugging Face。论文同步挂到 arXiv。
这件事真正的看点不是又多了一个开源代码模型,而是两个细节:第一,MusaCoder 的全链路后训练,是在基于 MTT S5000 的夸娥智算集群上跑完的,从 SFT、拒绝采样微调,到强化学习的异步 rollout、在线编译执行、reward 计算,一条龙没出国产 GPU 这个圈;第二,在 KernelBench 这个公认偏硬核的算子生成评测上,27B 版本的 RL 模型把 Claude Opus 4.7、DeepSeek-V4 Pro、GLM-5.1、Kimi K2.6 全部按了下去。
这是国产 GPU 第一次在"训练—验证—评测"这个完整闭环里,独立带出一个性能领先的专用代码模型。
不是通用代码模型,是冲着 GPU Kernel 来的
先把定位说清楚。MusaCoder 不是又一个对标 Claude Code、Cursor 的通用编程助手,它的目标场景非常窄也非常硬:从 PyTorch 标准算子,自动生成高性能的 CUDA / MUSA 原生 Kernel 代码。
做过 GPU 算子的开发者都知道,这事写起来痛苦在哪。Kernel 不像普通函数,写出来"能跑"只是第一步——
- 并行计算的线程组织得对
- shared memory、寄存器、global memory 的访问模式要友好
- 索引映射不能错位
- 数值精度要过验证
- 最后还得真比 PyTorch baseline 快
通用代码模型在这里普遍翻车。它们可以漂亮地补全一段 Python,但让它写一段融合算子的 CUDA Kernel,多数时候要么编不过,要么编过了跑错,要么跑对了比 torch.compile 还慢——那等于白写。
这是 MusaCoder 的切入口。摩尔线程把它定义成一个"针对底层算子生成任务"的专用模型,配套了一整套面向 GPU 原生算子的后训练方法论。
训练方法论:把"能跑"训成"跑得对而且快"
论文里这套流程分三段:有监督预热、任务对齐、执行反馈驱动的 RL。听起来是常规配方,但魔鬼在细节。
数据构建:把 Shape 信息显式注入
Kernel 生成最容易翻车的地方是张量形状和索引关系。MusaCoder 在数据构建阶段做了两件事:一是结构化推理过程,让模型先推 shape 再写代码;二是显式 Shape 信息注入,强行把张量形状、内存布局这些原本要模型自己脑补的东西摆到上下文里。
这种"灌"出来的先验,目的是解决从通用代码能力迁移到 Kernel 生成时的冷启动——你不能指望模型靠看 GitHub 上的 .cu 文件就学会理解 stride 和 offset。
MooreEval:分布式执行验证
这部分是整套训练能跑起来的关键基础设施。
MooreEval 是摩尔线程自己搭的一套分布式执行验证系统,承担四件事:
- 自动编译
- 执行 + 正确性验证
- 性能基准测试(对比 PyTorch Eager 和 torch.compile)
- 反作弊检测
最后一项尤其值得说。代码生成的 RL 训练里,模型很容易学会"投机取巧"——比如直接调用底层库绕过实现、给出退化版本骗过 reward。MooreEval 把这些路径堵掉,逼模型老老实实写 Kernel。
RL 阶段:PrimeEcho、MirrorPop、BDR
强化学习是 MusaCoder 最有意思的部分。GPU Kernel 任务对 RL 训练特别不友好:
- 多轮修复场景信号稀疏
- 长尾困难样本会让所有 rollout 全失败,梯度全是零
- 训练稳定性差
摩尔线程给出了三个机制:
- PrimeEcho:用于首轮锚定的多轮奖励,让多轮调试场景下的反馈不至于飘
- Buffered Dynamic Retry (BDR):专治"全失败"困难样本——把样本缓存起来反复尝试,从里面榨出训练信号
- MirrorPop:离策略序列过滤,稳定 GRPO 训练
这套组合拳打下来,模型形成了从 SFT → RFT → 执行反馈 RL 的完整闭环。
跑分:把闭源旗舰按下去
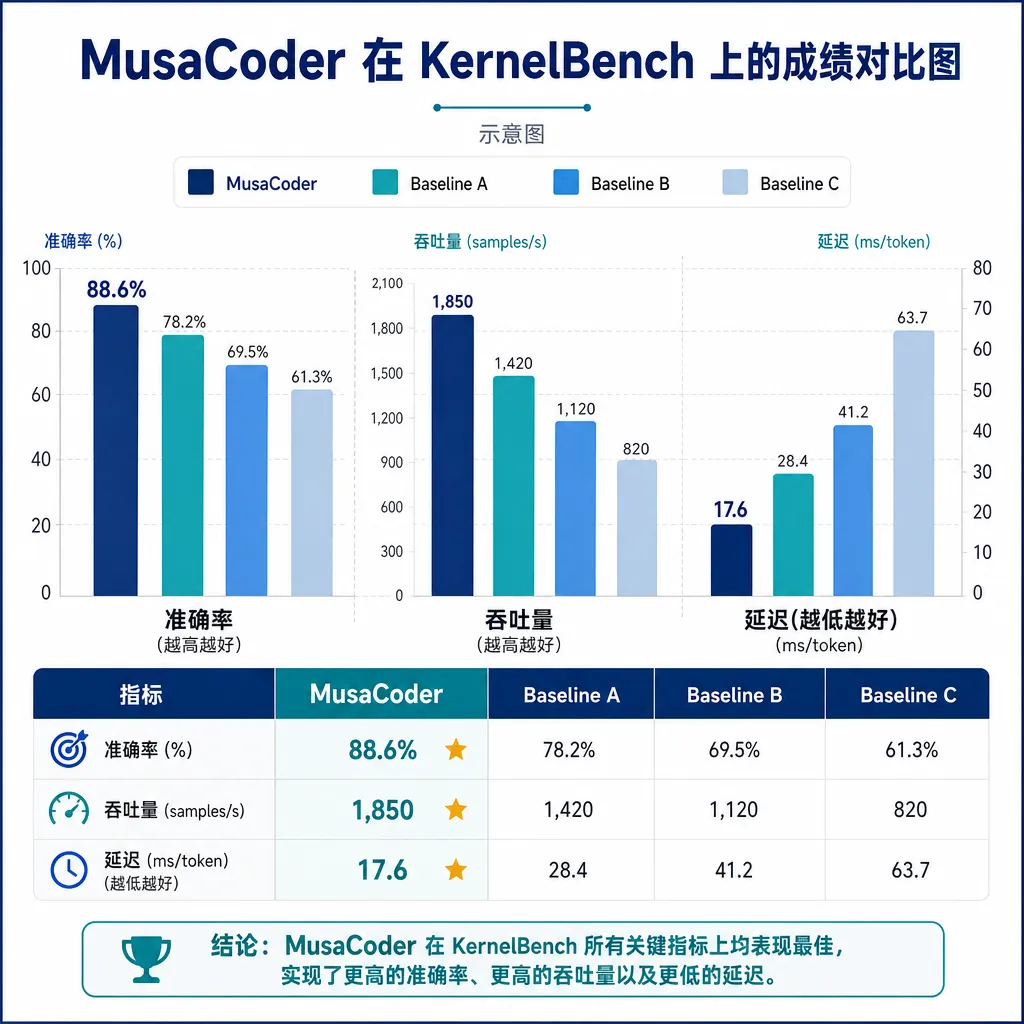
直接看 KernelBench 的数据。这个评测的规则是 Pass@8(8 次采样里有至少 1 次通过验证)和 Avg.@8(8 次的平均正确率):
| 模型 | Overall Pass@8 | Overall Avg.@8 | |---|---|---| | MusaCoder-27B-RL | 93.2% | 88.60% | | Claude Opus 4.7 | 87.2% | 77.30% | | DeepSeek-V4 Pro | — | — | | GLM-5.1 | — | — | | Kimi K2.6 | — | — |
比 Claude Opus 4.7 高了 6 个点的 Pass@8 和 11 个点的 Avg.@8。
更关键的是 Level 3 任务——KernelBench 里最难的那档,涉及复杂 shape 推导、索引映射和多算子组合。在这一档上 MusaCoder-27B-RL 的 Pass@8 和 Avg.@8 分别领先 Claude Opus 4.7 18 个百分点和 26.5 个百分点。
这种领先幅度不是"调参数胜出"能解释的,是任务专用模型对通用模型的结构性优势。
再看一个更"硬"的指标——Faster Rate。一份生成的 Kernel,要同时通过正确性、合法性,并且确实比 PyTorch baseline 跑得快,才会被计入:
- MusaCoder-27B-RL:vs. PyTorch Eager 15.0%,vs. torch.compile 9.2%
- Claude Opus 4.7:11.8% / 7.5%
意思是 MusaCoder 不只写得对,写出来还真有加速效果。这才是 Kernel 工程师真正在意的东西。
国产 GPU 这次撑住了"训练全周期"
抛开模型本身,这次发布最有信号意义的是另一件事:整个后训练流程没有用英伟达的卡。
SFT、RFT、RL、异步 rollout、在线编译执行验证、reward 计算——全部跑在 MTT S5000 构建的夸娥智算集群上。
听起来像例行公事,但对国产 GPU 是一次真实的压力测试。Kernel 生成任务的训练,远比常规大模型微调难伺候:每一步 rollout 都要触发代码生成、编译、执行、性能测量、反馈回写。这对硬件、编译栈、运行时、调度系统、评测基础设施的要求是叠加的——任何一环掉链子,整个 RL pipeline 就崩。
之前国产 GPU 普遍被诟病"推理可以、微调勉强、复杂训练翻车"。MusaCoder 这次相当于公开打了个样:国产卡能撑住一个完整的、带在线执行反馈的强化学习训练流程。
配合摩尔线程之前公开的夸娥集群数据——Dense 大模型 MFU 60%、MoE 40%、有效训练时长 90%、8000 卡线性扩展效率 95%——这条路径开始有迹可循。
这件事对开发者意味着什么
实用层面,MusaCoder 是给两类人准备的:
第一类,做 GPU 高性能计算的工程师。手写 CUDA/MUSA Kernel 这件事的门槛和心智成本一直很高,AI 辅助写算子的工具一直缺位。MusaCoder 的定位刚好补这个洞——给你一段 PyTorch 参考实现,它出 Kernel 代码,配合 MooreEval 这种执行验证环境,闭环就转起来了。
第二类,做异构计算研究的高校和科研机构。摩尔线程把这套东西开源出来(含 9B、27B 权重和论文),实际上是给 AI 编译优化、自动化 Kernel 生成这条研究方向送了一个开放的实验平台。
对 MUSA 生态来说,这是一次定位重塑。之前 MUSA SDK 5.1.0 对标 CUDA 12.8,强调的是"100% 兼容 PyTorch 全算子"——本质上还是跟随者。MusaCoder 把叙事换了:从"CUDA 上能做的我也能做"变成"我有一个 CUDA 上没有的、针对 Kernel 生成的专用模型"。
这是 MUSA 第一次提供了"做某件事比在 CUDA 上更方便"的差异化体验。能不能滚雪球,要看后续会不会有 IDE 插件、profiling 工具、自动调试工具链跟进——摩尔线程已经把这写进路线图。
一点冷静的判断
几个值得保留的怀疑:
- Benchmark 局限。KernelBench 是公开评测,但毕竟是单一基准。MusaCoder-27B-RL 在 Level 3 上的巨大优势,部分可能来自训练数据分布对评测任务的覆盖。真实生产环境中遇到的 Kernel 远比 benchmark 复杂。
- 27B 的部署成本。一个专门写算子的模型要 27B,对小团队不太友好。9B 版本的实际表现和 27B 之间的差距会决定它的普及度。
- MUSA Kernel 的实际需求量。这个模型对 CUDA 开发者也有用,但生态意义上摩尔线程肯定希望它带动 MUSA Kernel 的写作。MUSA 开发者基数比 CUDA 小一个数量级,模型能反哺生态多少,还得看时间。
但抛开这些保留,MusaCoder 整体上是个扎实的工作。把一个国产 GPU 公司从"卖卡"做到"卖卡 + 训出 SOTA 专用模型",至少在 AI Infra 这个细分赛道里,摩尔线程已经把生态闭环搭起来了。
模型已经在 Hugging Face 上线,对算子生成感兴趣的开发者可以直接拉来玩。
开源模型方面,OpenAI Hub 也在持续接入主流的开源代码模型,方便开发者用统一接口对比测试,需要的话可以顺手把 MusaCoder 和 Claude、DeepSeek 这些放在一起跑跑实际任务。
参考来源
- IT之家:摩尔线程开源 MusaCoder:首个基于国产全功能 GPU 全栈训练的代码大模型 — MusaCoder 发布与开源主要报道,含 KernelBench 评测数据
- Hugging Face:MooreThreads/MusaCoder-27B — MusaCoder 27B 模型权重与卡片信息


