HiDream-O1-Image-1.5登顶全球第三,中国模型首超谷歌英伟达

智象未来发布的HiDream-O1-Image-1.5在Artificial Analysis文生图榜单中位列全球第三、中国第一,超越Google Nano Banana 2和英伟达Cosmos3,仅次于OpenAI图像模型。这标志着中国企业在视觉生成领域的技术突破。
HiDream-O1-Image-1.5登顶全球第三,中国模型首超谷歌英伟达
智象未来的文生图模型HiDream-O1-Image-1.5刚刚在Artificial Analysis文生图榜单上拿到全球第三、中国第一的位置,超越了Google的Nano Banana 2(Gemini 3.1 Flash Image Preview)和英伟达的Cosmos3-Super-Text2Image。这是中国企业在视觉生成大模型上的一次标志性突破。
直接对标OpenAI,质量接近GPT Image 1.5
Artificial Analysis的榜单向来是文生图模型的试金石。HiDream-O1-Image-1.5在榜单上仅次于OpenAI的图像模型,生成质量与GPT Image 1.5 (high)、Google Nano Banana 2以及英伟达Cosmos3-Super-Text2Image处于同一水平线。但关键在于,它是这个梯队里唯一来自中国的闭源商业模型。
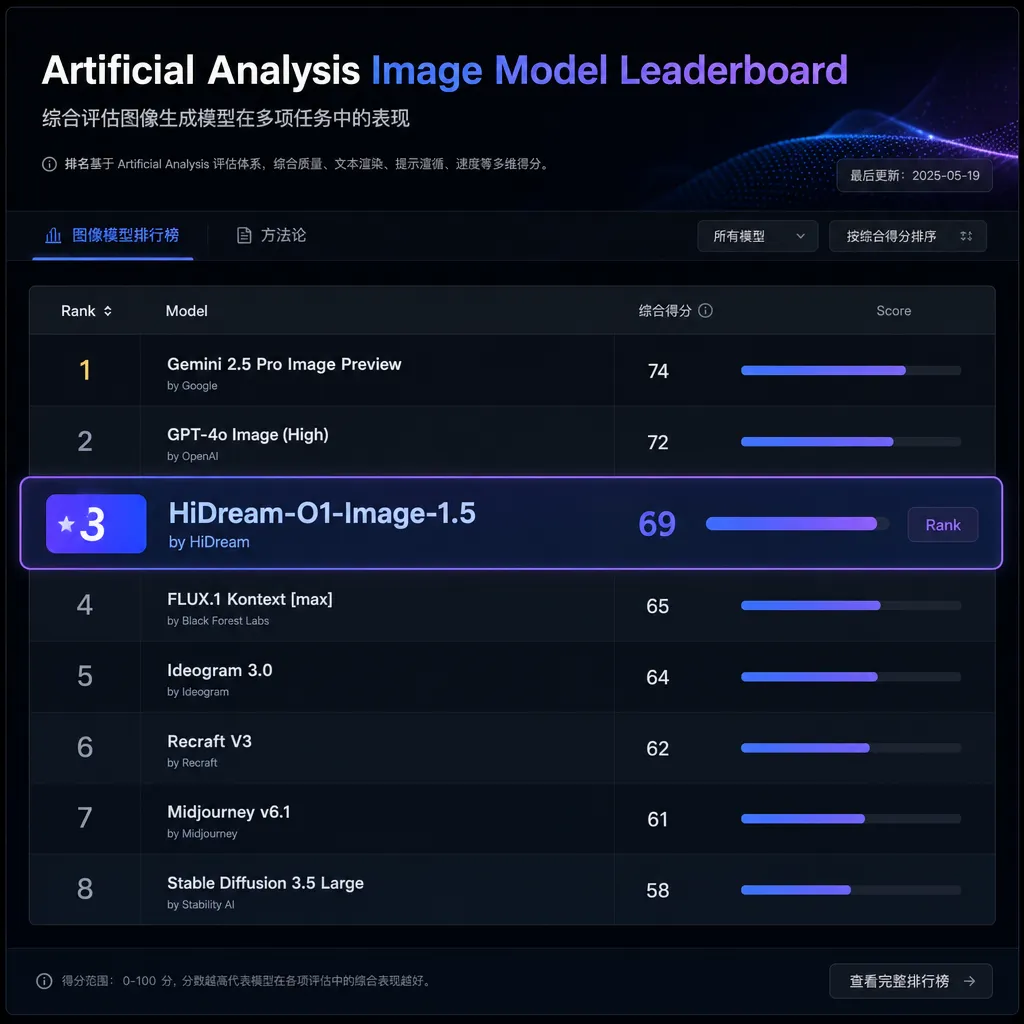
这个排名不是自说自话,而是基于Artificial Analysis的Image Arena真人盲测结果。用户在不知道模型身份的情况下对比图像质量,HiDream-O1-Image-1.5能稳定战胜一众国际大厂的产品,这说明它在美学、细节、prompt理解上都达到了顶尖水准。
技术路线:Unified Transformer架构的差异化打法
HiDream-O1-Image-1.5最值得关注的是它的架构设计。主流文生图模型大多采用「文本编码器+VAE+扩散模型」的分离式架构,比如Stable Diffusion和FLUX系列。而HiDream选择了Unified Transformer(UiT)架构,把原始像素、文本和任务条件统一编码到同一个token空间里,用单个Transformer处理所有模态。
这个思路有点像多模态大语言模型的做法——把图像和文本当作同一种「语言」来处理。好处是模型可以更直接地理解text-to-image任务中文本和图像的对应关系,减少跨模态的信息损耗。但代价是训练难度和计算成本都会更高,这也是为什么业界大部分公司还在走分离式架构的路线。
智象未来在5月就曾开源过HiDream-O1-Image(8B参数版本),当时以匿名身份「Peanut」登上Artificial Analysis榜单,拿到1187 ELO分数,成为开源模型全球第一,压过了Qwen Image(27B)和FLUX.2。现在发布的1.5版本是闭源商业版,参数规模未公开,但从性能上看明显经过了大幅优化。
2K分辨率输出,定价80美元/千张
HiDream-O1-Image-1.5支持最高2K分辨率的图像生成,这在商业模型里算是主流配置。定价是80美元/1000张图,比OpenAI的DALL-E 3(约20美元/1000张标准质量图像)贵不少,但考虑到它在榜单上的位置和输出质量,这个价格还算合理。
目前模型可以通过智象未来自家的HiHarness平台和Vivago平台调用。HiHarness是智象未来的模型推理平台,类似于OpenAI的API服务;Vivago则是一个第三方AI应用平台,整合了多家模型供应商。
值得注意的是,HiDream-O1-Image-1.5是闭源模型,不像5月开源的8B版本那样可以自己部署。对于需要私有化部署或者想研究模型细节的开发者来说,可能还得等后续是否会有开源版本更新。
中国模型在文生图赛道的位置变化
去年这个时候,文生图榜单前十基本被OpenAI、Midjourney、Google、Stability AI这些海外公司占据。国内厂商里,字节的豆包、阿里的通义万相、百度的文心一格都在追,但在国际榜单上的存在感不强。
HiDream-O1-Image系列的出现改变了这个格局。8B开源版本拿下开源第一,1.5闭源版本进全球前三,这是中国企业第一次在文生图领域跟OpenAI、Google、英伟达站在同一个擂台上正面较量。
但也要看到,榜单排名只是一个维度。文生图模型的商业化还涉及API稳定性、推理速度、成本控制、生态整合等多个方面。OpenAI的DALL-E 3虽然在某些盲测中不一定赢HiDream,但它的API已经被集成到无数应用里,开发者生态成熟得多。智象未来要想真正站稳脚跟,还得在工程化和商业落地上继续发力。
开源vs闭源:HiDream的双线策略
智象未来同时维护开源和闭源两条产品线,这个策略值得玩味。
开源的8B版本拿来刷榜、建立技术声誉、吸引开发者关注,这是典型的开源营销打法。Meta用Llama系列证明了这条路的有效性——开源模型可以快速积累用户和社区,形成技术影响力,然后再通过云服务、企业版、技术授权等方式变现。
闭源的1.5版本则是直接商业化,对标OpenAI和Midjourney,服务愿意为高质量内容付费的B端和C端用户。这部分用户不在乎模型开不开源,只关心生成质量和API稳定性。
这种双线策略的风险在于资源分散。开源版本需要持续迭代才能保持竞争力,闭源版本需要投入大量工程资源做优化和运维。智象未来作为一家创业公司,能不能同时支撑两条线,还得看后续的融资和团队扩张情况。
技术细节:UiT架构的优势与挑战
Unified Transformer架构听起来很美好,但实际落地有不少坑。
首先是训练数据的组织方式。传统架构里,文本编码器可以用预训练的CLIP,VAE可以用Stable Diffusion现成的,只需要重点训练扩散模型。但UiT要从头训练一个能同时处理文本和像素的Transformer,这意味着需要更大规模的配对数据,而且数据质量要求更高。
其次是推理效率。Transformer处理图像的计算复杂度是O(n²),n是token数量。一张2K分辨率的图像,如果按patch切分,token数量轻松上千。这对推理速度和成本都是挑战。智象未来在工程上肯定做了不少优化,比如使用Flash Attention、KV cache压缩、量化加速等技术,但这些细节目前都没有公开。
还有一个问题是可控性。分离式架构的好处是每个模块职责清晰,比如想控制风格可以换LoRA,想调整构图可以加ControlNet。UiT把所有东西揉在一起,虽然理论上可以学到更复杂的跨模态关系,但在实际应用中怎么做精细化控制,目前还没看到智象未来公开的方案。
竞品对比:HiDream vs Qwen Image vs FLUX.2
在中国市场,HiDream-O1-Image的主要对手是阿里的Qwen Image和Black Forest Labs(原Stability AI团队)的FLUX.2。
Qwen Image(27B)是开源模型,参数规模比HiDream的8B大得多,但在Artificial Analysis榜单上ELO分数低于HiDream。这说明参数规模不是文生图质量的唯一决定因素,数据质量和训练策略同样重要。Qwen Image的优势在于阿里的生态整合能力,它可以无缝接入通义千问、钉钉、淘宝等产品,这是创业公司很难复制的。
FLUX.2是目前开源社区最热门的文生图模型之一,有pro和dev两个版本。FLUX的架构是改进版的扩散模型,并没有采用UiT路线。在实际使用中,FLUX.2 dev在提示词理解和风格多样性上表现很强,社区里各种微调版本和插件也很丰富。HiDream的开源版本虽然榜单分数更高,但生态还在建设初期。
闭源模型里,HiDream-O1-Image-1.5的直接竞争对手是OpenAI的DALL-E 3/GPT Image和Midjourney。从价格上看,HiDream是最贵的那一档,但质量也确实到了第一梯队。关键差异在于API易用性和稳定性——OpenAI的API文档、SDK、错误处理都经过了几年打磨,Midjourney虽然是Discord bot但用户习惯已经形成。HiDream要抢这部分市场,得在开发者体验上下功夫。
商业化路径:不只是API服务
智象未来不太可能只靠卖API赚钱。文生图市场的商业模式比文本模型复杂:
-
API服务:面向开发者和企业,这是最直接的变现方式。但竞争激烈,价格战风险高。
-
应用层产品:类似Midjourney做Discord bot,或者像Stable Diffusion WebUI那样提供开箱即用的图像生成工具。智象未来如果能做出爆款应用,收益会比纯API高很多。
-
行业解决方案:为电商、广告、游戏、影视等行业定制化,提供高分辨率、批量生成、风格可控的解决方案。这块的客单价高,但需要深入理解行业需求。
-
模型授权和私有化部署:对数据安全要求高的企业(如政府、金融、军工),开源8B版本可能不够用,闭源版的私有化部署授权会是一个可观的收入来源。
从目前的动作看,智象未来在多条路上都有布局。HiHarness平台做API服务,开源版本吸引社区,同时也在跟Vivago这样的第三方平台合作扩大覆盖面。但具体哪条路能跑通,还得看接下来半年的数据。
榜单之外:文生图模型的真实挑战
Artificial Analysis的榜单主要测的是「单张图像生成质量」,但实际应用中,文生图模型要解决的问题远不止这个。
一致性问题:生成连续的图像序列(比如漫画分镜、产品展示的多角度图),怎么保证角色、物体、风格的一致性?这是Midjourney和DALL-E 3都还在努力解决的难题。HiDream有没有针对性的技术方案,目前不清楚。
可控性问题:用户想精确控制构图、光影、细节,纯文本prompt很难做到。Stable Diffusion社区用ControlNet、IP-Adapter这些插件解决,商业模型里Adobe Firefly做了结构化输入界面。HiDream的API和产品形态怎么处理这个需求,值得关注。
版权和安全问题:文生图模型训练数据的版权争议一直没停过,Getty Images起诉Stability AI的案子还在打。另外,生成不当内容(暴力、色情、deepfake)的风险也是监管重点。智象未来作为中国公司,在内容审核和合规上的压力可能比海外公司更大。
推理成本问题:2K分辨率的图像生成,单次推理成本不低。HiDream的定价是80美元/1000张,背后的利润空间有多少,能不能持续优化成本,直接影响商业模式的可持续性。
中国AI的新信号
HiDream-O1-Image-1.5登顶榜单,背后是中国AI公司在视觉生成领域的集体突破。过去一年,字节的豆包、阿里的Qwen Image、百度的文心一格、MiniMax的视频生成模型,都在快速进步。
这波进步有几个共同特点:
-
技术路线的差异化:不再简单跟随OpenAI和Google的架构,而是根据自己的数据和计算资源特点,探索不同的技术路线。HiDream的UiT架构就是一个例子。
-
开源+闭源双轨并行:既用开源刷存在感、建生态,又用闭源做商业化变现。这是Meta用Llama证明有效的策略,中国公司学得很快。
-
国际化意识增强:不只盯着国内市场,而是主动参与国际榜单竞争,对标国际一流产品。智象未来选择在Artificial Analysis上刷榜,就是要在全球市场上证明自己。
但也要看到,榜单排名只是起点。OpenAI、Google、Meta在AI领域的积累不只是模型性能,还有工程能力、生态整合、品牌影响力。中国公司要真正站稳脚跟,还有很长的路要走。
不过至少,HiDream-O1-Image-1.5证明了一件事:在文生图这个赛道上,中国公司已经有能力跟国际巨头同台竞技,而且不落下风。这是个好的开始。
参考来源
- HiDream-O1-Image原生全模态大模型登顶AA开源榜首 - 知乎 - 详细分析HiDream-O1-Image开源版本的技术特点和榜单表现


