DiffusionGemma来了:扩散模型杀进文本生成,速度提了4倍

Google DeepMind今天放出DiffusionGemma实验版开源模型,把图像扩散那套并行生成的思路搬到了文本上,单次吐出整块token而非逐字生成,相比同尺寸自回归模型推理快约4倍,NVIDIA同步完成RTX全家桶的优化适配。
谷歌把扩散模型搬进了文本生成
今天(6月10日)凌晨,Google DeepMind 在官方博客挂出了 DiffusionGemma——一个走扩散路线的实验性开源文本模型。官方给出的核心数字只有一个:相同尺寸下,文本生成速度比传统自回归模型快 4 倍。
这不是谷歌第一次在扩散语言模型上下注。回头看 2025 年 I/O 上首次亮相的 Gemini Diffusion 闭源 demo,跑出过 1479 tokens/s 的离谱速度,但那东西一直关在 AI Studio 里没放出来。整整一年之后,DeepMind 终于决定把这条技术路线开源化、Gemma 化,丢给社区折腾——这是过去一年 Gemma 家族下载量破 4 亿、衍生模型超 10 万个之后,DeepMind 顺手做的一次架构层面的试水。
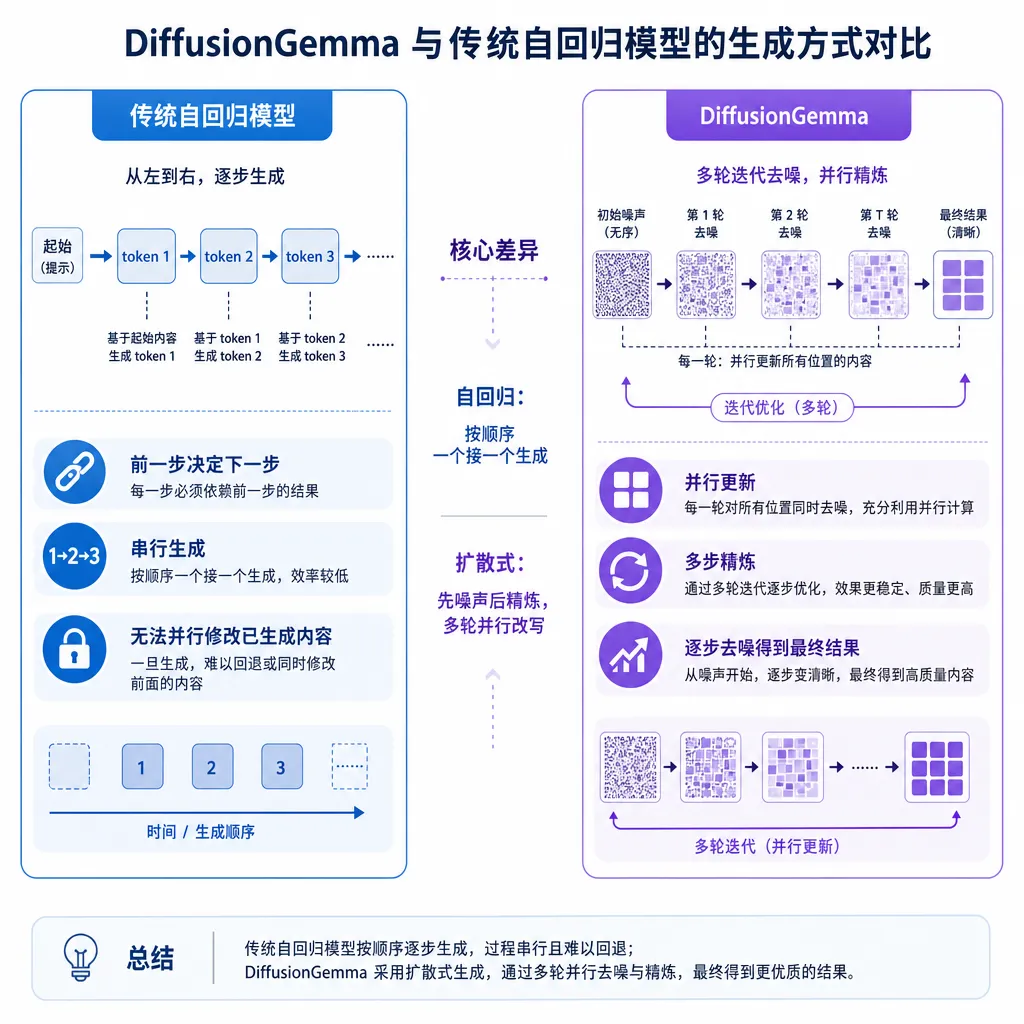
为什么扩散能跑得比自回归快
要理解 DiffusionGemma 的意义,得先回到自回归(autoregressive)这个 LLM 标配的范式上。GPT、Claude、Llama、Qwen,所有你叫得上名字的主流大模型,干的都是同一件事:给定前面 N 个 token,预测第 N+1 个。一个字一个字往外蹦,蹦完一个再算一次注意力。
这个范式的天花板很清楚:
- 延迟天然受限。生成 1000 个 token,就要做 1000 次前向传播,没法并行
- 批量推理友好,单用户体验糟糕。一个人用的时候 GPU 利用率低得可怜
- 错误会沿序列传播。前面写错了一个词,后面只能将错就错
扩散模型走的是另一条路。它从一段被高度噪声化的"乱码"开始,通过若干步迭代去噪,最终还原成一段连贯文本。关键在于:每一步去噪都是对整段文本并行完成的。换句话说,DiffusionGemma 不是一字一字写,而是先打个糊糊的草稿,再一遍遍润色——每一遍都同时润色所有位置。
这套思路在图像生成那边早就被 Stable Diffusion 们玩透了,但放到离散的文本 token 上一直不顺利,主要卡在两点:一是离散空间的扩散过程怎么定义,二是文本对局部一致性的要求远比图像苛刻——图像糊一块还能看,文本错一个介词就崩了。DeepMind 这次的版本,是把过去两年学术界的几条工程优化(mask-based diffusion、self-conditioning、可变步数采样)整合在 Gemma 架构上的一次工程化收敛。
4 倍速度从哪里来
谷歌官方博客给出的对比是同参数量级下的 Gemma 自回归模型。需要拆开看:
1. 并行解码带来的吞吐红利
一次推理可以同时生成一整个 block 的 token——根据 NVIDIA 那篇适配博客的描述,DiffusionGemma 是 "outputs whole blocks of text",不是逐 token 流式输出。这对单用户场景(developer 本地跑、IDE 内联补全、agent 任务)是降维打击,因为这类场景的瓶颈本来就是 latency 而不是 throughput。
2. 步数远少于 token 数
传统自回归生成 1000 token 要 1000 步。DiffusionGemma 在去噪步数上做了大量压缩,典型配置下几十步就能输出整段。算下来每步要做更重的计算,但总步数大幅减少,端到端依然更快。
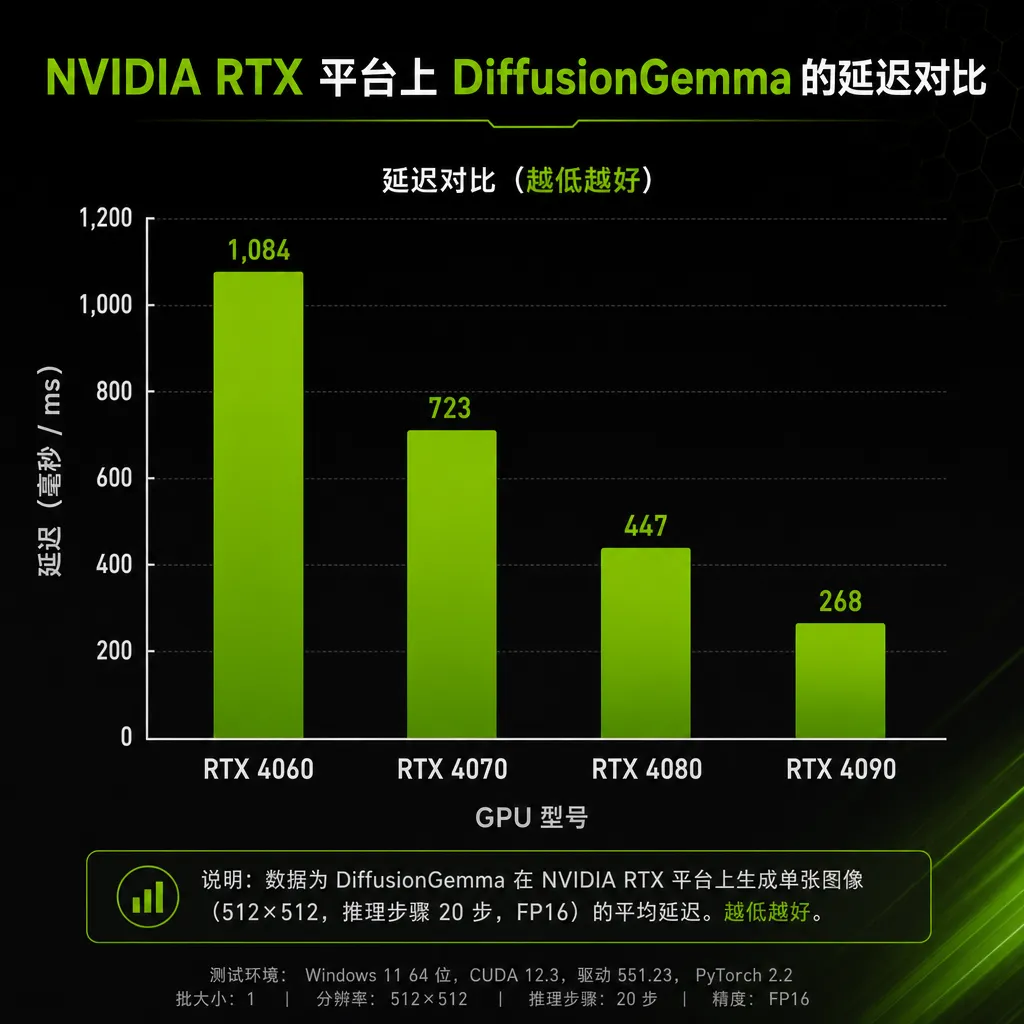
3. RTX 端侧优化压榨硬件
NVIDIA 几乎是和 DeepMind 同步官宣,已经把 DiffusionGemma 在 GeForce RTX、RTX PRO 工作站、以及 DGX Spark 三条产品线上做了内核级优化。RTX 的 Tensor Core 在做并行 token 推理时的利用率,比逐字自回归高出一大截。这意味着开发者在自己的 4090、5090 上跑 DiffusionGemma,体感会比同尺寸 Gemma 流畅得多。
它真的能用吗:质量这关
速度故事讲完,问题是质量。扩散语言模型过去几年一直在学术界打转、迟迟没有走向生产,核心原因就是写出来的东西不够"顺"。
参考去年 Gemini Diffusion 在 HumanEval 上 89.6% 的成绩——和 Gemini 2.0 Flash-Lite 的 90.2% 基本打平。这个分数挺有意思:扩散模型在强结构性任务(代码、数学、JSON 这种有明确语法约束的)上表现接近甚至持平自回归,但在自由长文本生成(创意写作、长对话)上还是会暴露问题——主要是长程一致性和前后呼应。
DiffusionGemma 作为 Gemma 家族里第一个非自回归成员,目前定位明确是"实验性"。从博客措辞看,谷歌也没打算让它取代主线 Gemma,更像是给社区一个新玩具:
- 适合做:代码补全、结构化输出、约束生成、低延迟交互式应用
- 不太适合:长文创作、复杂多轮推理、需要严格事实性的问答
这定位其实挺务实。扩散模型的"块输出"特性,意味着它对 prompt 的整体语义把握可能更好(因为它一开始就在所有位置上同时思考),但代价是失去了自回归那种"边写边调整"的灵活度。
对开发者意味着什么
这事的实际影响要分两层看。
短期:又一个能本地跑的开源模型,但场景特殊。 DiffusionGemma 已经放上 Hugging Face,权重开源,本地推理友好。如果你正在做需要低延迟、流式响应不那么重要、输出有结构约束的应用——比如 IDE 里的代码块补全、表单填充、批量数据清洗——这个模型值得跑一下 benchmark。在 RTX 4090 这一档消费级显卡上的体感优势,会比纸面数字更明显。
长期:自回归不是唯一答案。 过去三年所有人都默认 Transformer + autoregressive = LLM,但今年从 Mamba 类 SSM 到现在的扩散语言模型,可以看到大厂在悄悄探索范式外的可能性。DiffusionGemma 把这条路从论文推进到了开源生产可用,意义不在于它今天能干什么,而在于它把扩散语言模型这个赛道的下限抬高了。
顺带提一句,OpenAI Hub 这边主线模型(GPT、Claude、Gemini、DeepSeek)的 API 聚合还是常态服务,但 Gemma 这种本地优先的开源模型,更建议大家直接拉权重在自己机器上玩——毕竟扩散模型的低延迟优势,得在端侧才能完整吃到。
还需要看清楚的几件事
- 上下文长度:官方目前没披露 DiffusionGemma 的最大上下文,扩散模型在长上下文下的计算开销缩放规律和自回归不同,这块得等社区实测
- 微调生态:Gemma 系列的杀手锏是社区微调,DiffusionGemma 能不能复刻这一套(LoRA、QLoRA、各种领域适配)还要看 DeepMind 后续放出的训练脚本
- 量化兼容性:扩散模型的多步推理对量化误差更敏感,INT4/INT8 量化后会不会掉点,是它能不能真正下沉到消费级硬件的关键
这几个问题,估计未来一两周 Hugging Face 上的讨论区会有答案。DiffusionGemma 今天放出来的更像是一个"工程预览版",真正的考验是接下来三个月社区拿它能跑出什么花样。
参考来源
- Gemini Diffusion 速度爆表的技术解读 - 知乎:去年 I/O 上 Gemini Diffusion 首发时的中文技术分析
- Gemma 4 系列模型动态 - 社区讨论:Gemma 系列在 Hugging Face 上的官方模型卡和社区衍生模型生态


