DeepMind开源DiffusionGemma:H100跑出1000TPS

谷歌DeepMind把扩散架构搬到了文本生成上,开源的DiffusionGemma在单张H100上实现1000+ tokens/秒,比传统自回归模型快4倍,RTX 5090也能跑出700 TPS。本地推理的延迟天花板又被掀了一次。
DeepMind把图像生成的那套架构,塞进了文本模型
6月10日,Google DeepMind开源了DiffusionGemma——一个把扩散(Diffusion)架构用到文本生成上的实验性开放模型。官方给的数据相当扎眼:单张NVIDIA H100上1000+ tokens/秒,NVIDIA RTX 5090上700+ tokens/秒,相比同等规模的自回归Gemma,解码速度提升约4倍。NVIDIA当天也跟着发了博客,宣布从GeForce RTX、RTX PRO平台到DGX Spark都已经做了针对性优化。
听到"扩散+文本"这个组合,做过模型的人第一反应大概率是:又来?过去两年学术界陆陆续续有人尝试过把diffusion往LLM上搬,从SSD-LM到Mercury再到Inception Labs的那批模型,但真正能在工业级场景里把吞吐和质量同时打平自回归基线的,一只手数得过来。DeepMind这次直接开权重、给出可复现的1000 TPS数字,等于把这条技术路线从论文阶段往工程主流推了一大步。
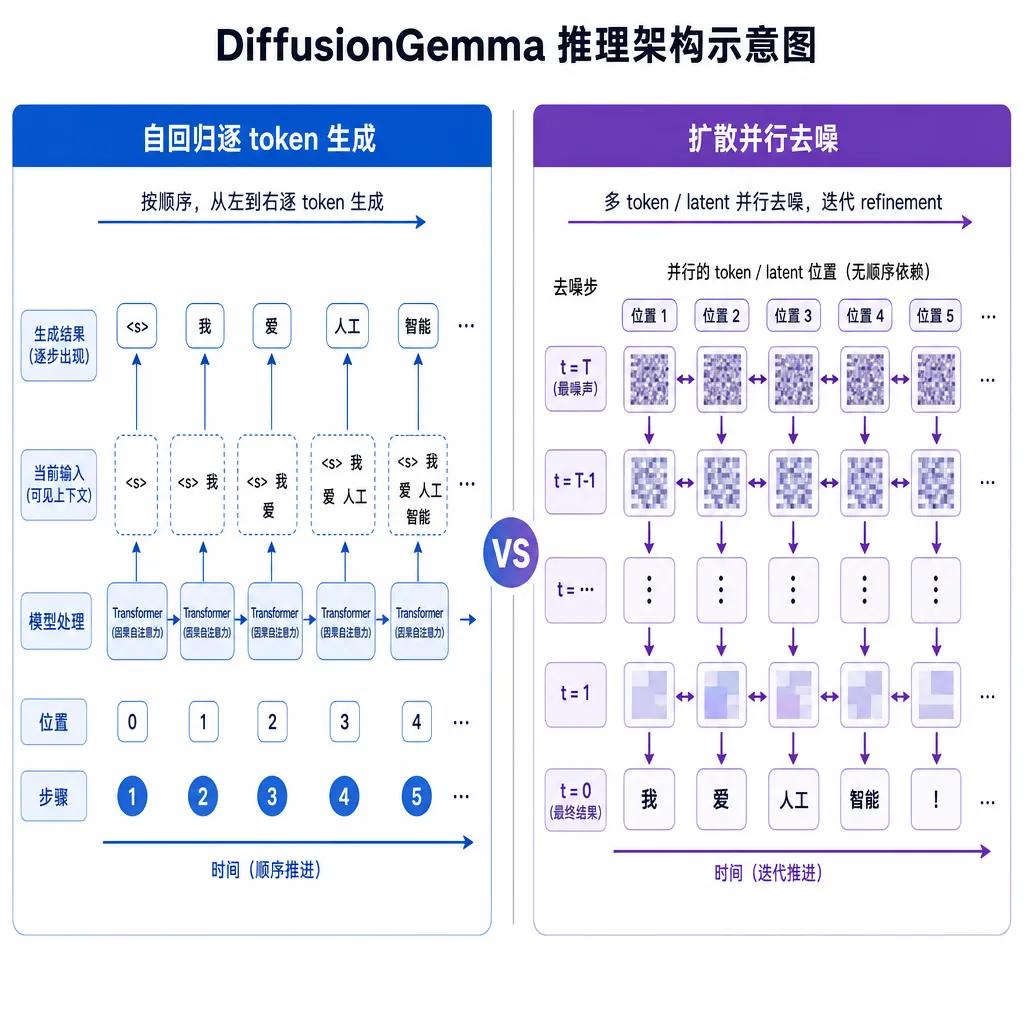
它到底快在哪:从"内存带宽瓶颈"挪到"算力瓶颈"
要理解DiffusionGemma为什么快,得先搞清楚自回归模型现在卡在哪。
传统的Next Token Prediction(NTP)架构,每生成一个token,都要把数十亿参数从显存里读一遍,做一次完整前向。问题是,单token的计算量极小,GPU的TensorCore绝大部分时间都在等显存——这是典型的memory-bound场景。一张H100,FP16理论算力将近1000 TFLOPS,但跑70亿参数的自回归推理,算力利用率经常只有个位数百分比。剩下的全在等HBM。
扩散模型走的是另一条路。它不是从左到右一个token一个token地吐,而是给定一段固定长度的空白(带噪声)token序列,模型一次性预测整段内容,然后通过多步去噪迭代纠错,最终收敛到一个干净的输出。
这套机制带来两个直接结果:
- 并行度起来了。每一步去噪都是对整块区域同时操作,矩阵运算密度大幅提升,GPU终于有活干了。
- 瓶颈从带宽切到了算力。原本闲置的TensorCore被吃满,H100的硬件特性才真正发挥出来。
所以1000 TPS不是单纯靠"模型变小"或者"量化"堆出来的,而是架构层面把GPU的脾气摸顺了。这点和上个月Gemma 4那个MTP(Multi-Token Prediction)起草器是不同思路——MTP本质还是推测解码,用小模型起草、大模型并行验证,最多3倍提速;DiffusionGemma是把底层范式换掉了。
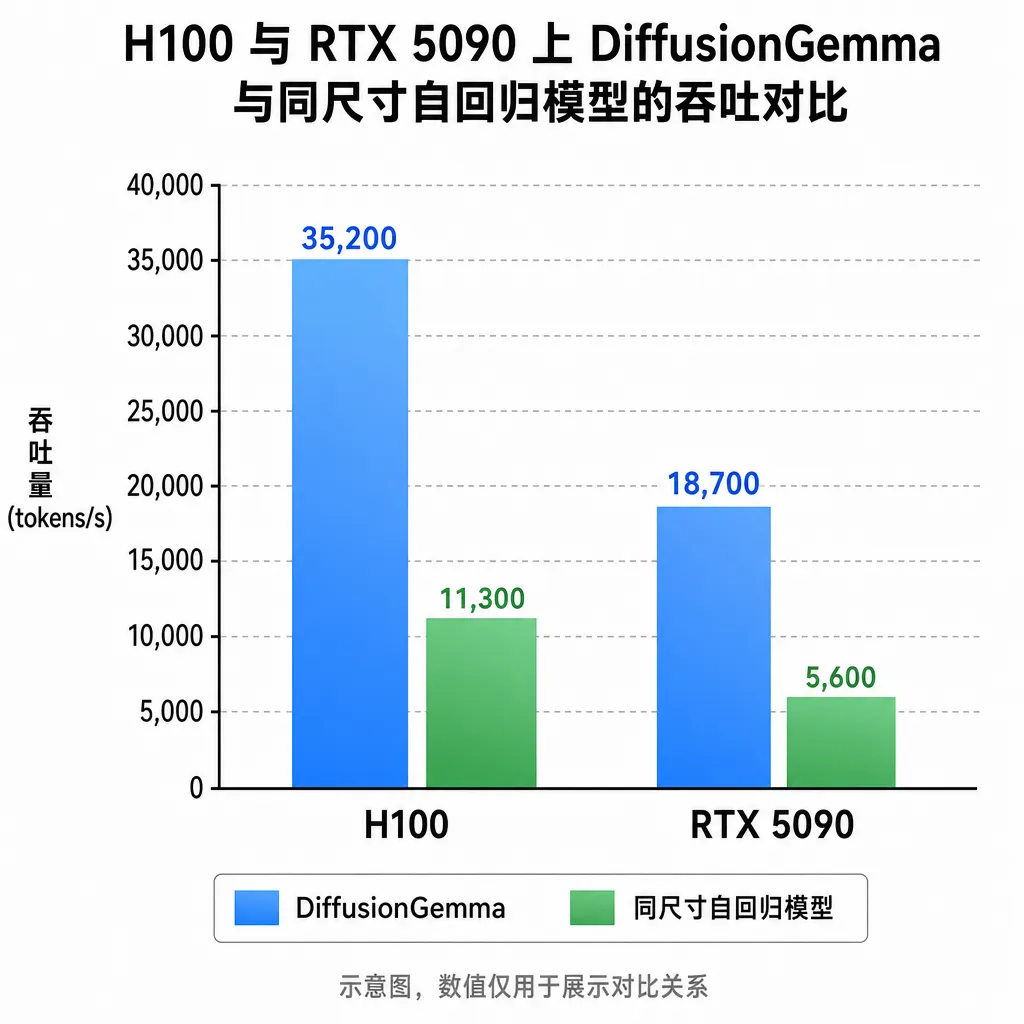
实测数字怎么看:1000 TPS 是什么概念
给个对比坐标。当前在H100上跑Llama 3 8B或者Gemma 2 9B的自回归推理,单用户场景下通常在150-250 TPS区间,开了vLLM、PagedAttention这些优化,能压到300左右就算优秀。1000 TPS意味着什么?
- 用户体感上,几乎是"瞬间出答案"。一段500 token的回复,0.5秒内完成。
- 对Agent场景特别友好。多轮工具调用、ReAct循环、代码执行反馈——这些以前因为延迟堆叠让人头疼的链路,现在每一跳都能压到亚秒级。
- 消费级显卡也吃得下。RTX 5090的700 TPS数据更关键,意味着这不只是数据中心的特权,本地开发机就能跑出过去需要A100/H100集群才有的体验。
NVIDIA这次的优化幅度也值得提一句。他们针对Blackwell架构做了kernel级的调优,把扩散过程里那些反复的注意力计算和去噪步骤融合到了一起,避免了中间显存读写。DGX Spark那条产品线大概率会把这个模型作为出货卖点之一。
质量呢?这才是关键问题
速度好讲,质量难讲。扩散文本模型历史上最大的争议就是:生成结果的连贯性、推理能力、长文本一致性,能不能跟自回归打平?
DeepMind在博客里给出的说法是,DiffusionGemma在主流基准上的表现"与同规模自回归Gemma相当"。但所谓相当的范围有多宽,目前公开的细节还不够。从社区已经做的初步测试看:
- 短上下文、确定性任务(分类、抽取、摘要、代码补全):基本没差距,速度优势直接转化为体验优势。
- 多步推理、长链思考:扩散的迭代去噪天然不擅长"逻辑严密的链式推理",这块还需要更多benchmark验证。
- 超长生成:扩散需要预先确定输出长度,对开放式长文本生成不如自回归灵活。这是范式层面的天然约束。
所以,把DiffusionGemma当万能解药并不现实。它更像是为延迟敏感、吞吐优先的场景准备的另一种选择——客服、实时翻译、IDE内联补全、Agent工具调用——这些场景里多花200毫秒可能就是用户流失,而推理深度反而不是核心需求。
对开发者意味着什么
几个我觉得比较实在的影响:
- 本地推理的天花板被抬高了。以前在RTX 4090上跑7B模型撑死200 TPS,现在5090上700 TPS,体验差距是质变不是量变。本地Copilot、本地Agent的可玩性突然就上来了。
- 推理服务商的成本结构会被重估。如果同样的GPU能跑出4倍吞吐,单token成本理论上也是1/4。这对Together、Fireworks这些inference platform是利好,对自建推理的团队也是。
- 架构多样性回来了。过去三年LLM赛道实在太"Transformer + 自回归"了,Mamba、RWKV、Diffusion这些路线一直在边缘探索。DeepMind这次用开源的方式给Diffusion文本模型注入了一针强心剂,预计接下来半年会有一波跟进。
顺便提一句,OpenAI Hub(openai-hub.com)这边的开源模型聚合也会跟进DiffusionGemma的接入,开发者可以用同一个Key在GPT、Claude、Gemini、DeepSeek这些主流模型之间切换测试,对比不同架构在自己业务上的实际表现,省去多家API管理的麻烦。
几个还没回答的问题
这是一个experimental release,DeepMind自己也说了是"实验性"。有些事情还需要继续观察:
- 长上下文支持。当前版本的max context长度官方没大力宣传,扩散对超长上下文的支持成本可能比自回归更高。
- 微调生态。LoRA、QLoRA这些工具链能不能直接套用?扩散过程里加adapter的最佳实践还没成型。
- 推理框架适配。vLLM、TensorRT-LLM、llama.cpp这些主流框架对扩散文本模型的支持目前还很初级,社区跟进速度会决定它的实际落地半径。
但话说回来,开源出来本身就是最大的信号。让社区去填坑、去试错、去拓展——这是Gemma系列一贯的玩法,也是为什么从去年开始Gemma的下载量能在几周内冲到6000万次。DiffusionGemma放出来这几天,HuggingFace上的下载曲线已经很陡了。
至于它最终是会成为Transformer之外的第二条主流路线,还是又一个停留在benchmark表现不错但工程落地受限的实验品,6个月之后再回头看就有答案了。
参考来源
- linux.do - 谷歌开源Diffusion Gemma,可在h100上跑出1000tps - 中文社区的第一手讨论和实测反馈
- Reddit - Google says Multi-Token Prediction makes Gemma 4 faster - 上一代Gemma 4 MTP的实测讨论,可作为速度优化的对比参照
- 知乎 - Gemma 4 谷歌开源的字节效率之王 - Gemma系列开源模型的整体架构与定位分析


