小米开源 MiMo Code:把记忆外包给 subagent 的终端 AI 编程助手

小米今日开源 MiMo Code V0.1.0,基于 OpenCode 二次开发,MIT 协议。最大亮点是用独立 subagent 接管记忆管理,解决长会话遗忘问题,并内置限时免费的 MiMo-V2.5 多模态模型。
小米开源 MiMo Code:把记忆外包给 subagent 的终端 AI 编程助手
小米 MiMo 团队昨夜凌晨甩出了 MiMo Code V0.1.0——一个跑在终端里的 AI 编程助手,基于 OpenCode 二次开发,直接 MIT 协议开源到 GitHub。在 Claude Code、Cursor、Cline、Aider 已经把这条赛道挤得满满当当的当口,小米选择把自己定位成「探索性」工具,野心其实不小:不是再做一个 OpenCode 的换皮分发,而是想在长程会话的记忆机制上踩出一条新路。
这是小米 MiMo 系列今年继 V2 Flash 编码模型、V2.5 全模态系列陆续开源之后,把模型能力外延到 Harness 层的第一次正式动作。前几天雷军刚在微博上吹了 V2.5-Pro-UltraSpeed 在 1 万亿参数模型上突破 1000 tokens/s,紧接着配套工具就来了,节奏卡得很紧。
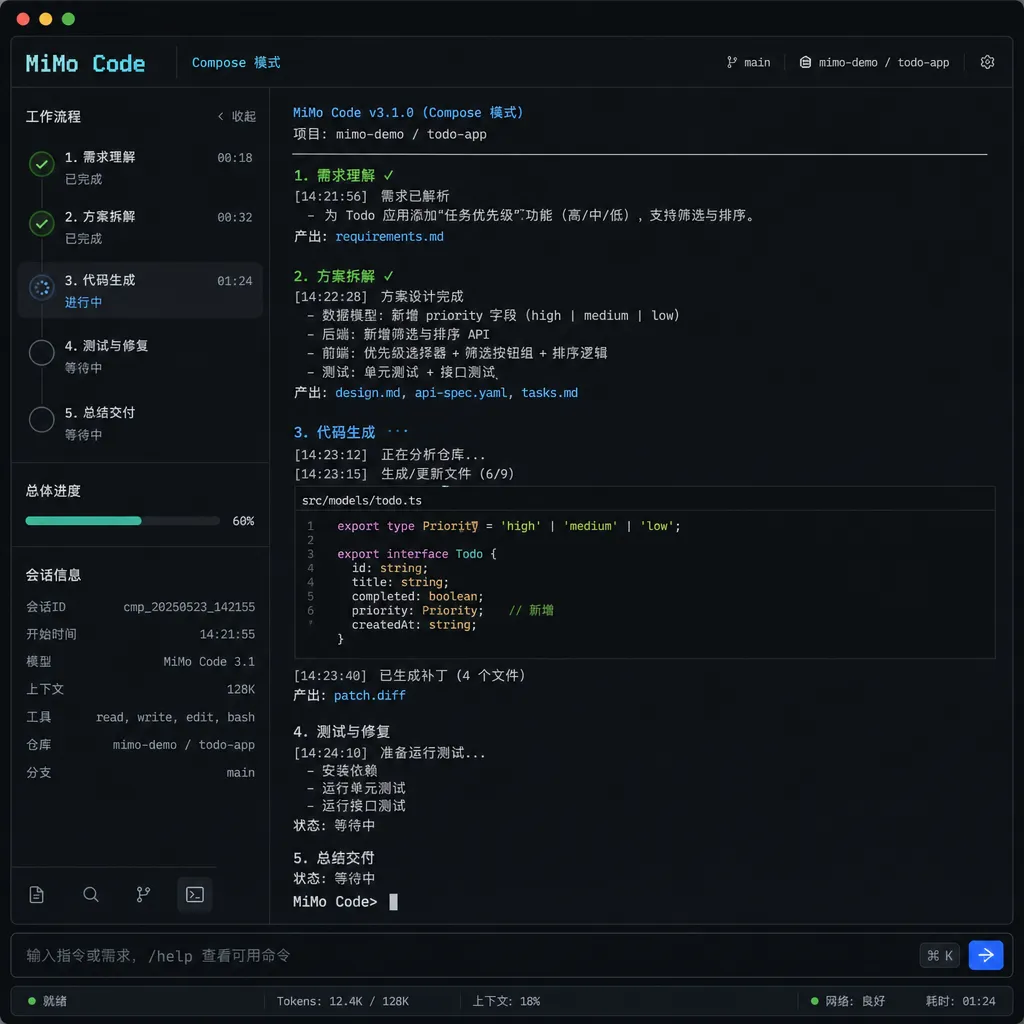
它到底是什么:OpenCode 的「小米味」分叉
先把定位说清楚。MiMo Code 不是从零造轮子,而是 fork 了 OpenCode 这个开源 CLI 编程助手做二次开发。OpenCode 本身在国外开发者圈口碑不错,主打多供应商、可插拔、TUI 界面,跟 Claude Code 是同一个生态位的开源对位。
小米在这之上做了几件事:
- 接入自家 MiMo-V2.5 多模态模型,作为限时免费的默认通道(官方称 MiMo Auto,零配置启动)
- 兼容 DeepSeek、Kimi、GLM 等主流国内模型 API,以及第三方 Token Plan
- 重写了记忆系统,搞了一套独创的三层持久化机制
- 加了 Compose 模式、/dream 命令、语音输入这几个比较有辨识度的功能
- 为 MiMo 系列模型定制了 Harness 系统,做模型-框架的协同优化
安装路径走的是标准 CLI 套路:
# Mac / Linux
curl -fsSL https://mimo.xiaomi.com/install | bash
# Windows
npm install -g @mimo-ai/cli
装好直接在终端敲 mimo 启动。如果你之前用过 OpenCode 或 Claude Code,迁移成本基本为零。
真正值得说的:把记忆「外包」给 subagent
MiMo Code 最值得拿出来聊的,是它处理长会话遗忘的方式。这事儿是所有 Agent 类编程工具的老大难——上下文窗口一满,要么强行截断丢失关键信息,要么塞太多 token 把成本和延迟拉爆,要么靠 RAG 检索但召回质量飘忽。
小米的解法用一句话概括:主 agent 专心干活,记录完全外包。
具体机制是三件套:
- 项目记忆:长期沉淀的项目级理解,包括代码结构、约定、依赖关系
- 会话检查点:阶段性快照,关键决策点的状态固化
- 任务进度:当前任务链条的位置追踪
这三层都不由主 agent 自己维护,而是丢给一个独立的 subagent 后台跑。窗口快满时,subagent 自动生成一份压缩过的「干净简报」,主 agent 拿着简报继续干,不用从零开始重建上下文。
这个设计思路其实挺聪明。传统做法是让模型自己总结上文塞回提示词,但模型一边干活一边压缩自己的记忆,注意力是分散的,压缩质量也不稳定。小米的做法等于让一个专职「秘书」全程记笔记,主 agent 完全无感。代价是会多消耗 token 跑 subagent,但对长项目场景下的输出质量提升应该是显著的。
/dream 命令:让助手「睡一觉再来」
更有意思的是 /dream 命令,每 7 天自动触发一次。
这个 Agent 干的事相当于人脑的睡眠固化——读取这一周的历史会话和现有记忆文件,做四件事:合并重复信息、去重冗余条目、验证文件路径有效性(避免记忆指向已删除的文件)、压缩成更紧凑的当前状态,然后写回全局记忆。
为什么这个设计有意义?因为单纯堆积记忆是会「腐烂」的——昨天还存在的 utils.ts,今天可能被重构没了;上周记下的某个函数签名,可能早就改过了。如果不定期清理,记忆库越大越脏,反而会污染主 agent 的判断。
把这种「记忆维护」做成定时异步任务,而不是每次启动都跑一遍重 IO,是个相当工程化的取舍。Claude Code 和 Cursor 目前都没有类似的机制,靠的还是用户手动维护 CLAUDE.md 或 .cursorrules 之类的静态文件。
Compose 模式:一句话到工业级交付
按 Tab 切换 Compose 模式后,工具的行为模式会切换:不再是一问一答的交互,而是把「设计-规划-编码-测试-审查」整条流水线包起来跑。
小米的官方说法是「1+1>2 的协同效果」。怎么理解?大概率是 Compose 模式下,主 agent 会调起多个专精 subagent 分别处理设计、代码生成、单测、Code Review 等环节,类似 Devin 或 OpenHands 的多 agent 编排,但跑在本地终端里。
这条路其实是当下 AI 编程工具的主流方向——单 agent 的能力天花板已经显现,多 agent 协作 + 任务分解才是从「补全」走向「交付」的关键。小米能不能做出实质性的差异化,得看 Harness 系统跟 MiMo-V2.5 的协同到底有多深。模型和 Harness 都是自家的,理论上调优空间比通用工具大,但能不能转化成实际体验,还要看后续迭代。
语音输入:在终端里嘴替
MiMo Code 还塞了一个看起来略微「炫技」但实际可能很实用的功能——语音输入与控制,底层用的是 MiMo-V2.5-ASR。
场景大致是这样的:写错指令了,不用退格删一长串,直接说「把刚才的文件名改成 user_service」;想执行操作,直接念「发送」「执行」「取消」。从输入到操控全程脱手键盘。
这功能在开放式工位或者结对编程时可能有点尴尬,但单人深度开发时段,配合无线耳麦确实能省不少手指操作。算是一个差异化卖点,但不算核心竞争力。
横向对比:在 Claude Code 和 OpenCode 之间找位置
把 MiMo Code 放到当前的 CLI 编程助手赛道里看:
- vs Claude Code:Anthropic 的 Claude Code 是闭源、强模型驱动、Harness 黑盒;MiMo Code 是开源、可换模型、Harness 透明可改。生态成熟度差很多,但灵活性占优。
- vs OpenCode:本就是 fork 关系。MiMo Code 主要加了记忆系统、Compose 模式、语音和定制 Harness,对国内用户的模型接入也更友好(GLM、Kimi、DeepSeek 都是原生支持)。
- vs Aider/Cline:Aider 偏 Git workflow,Cline 偏 IDE 集成(VS Code 扩展),MiMo Code 是纯终端原生,定位更接近 Claude Code 的形态。
对国内开发者而言,MiMo Code 最大的吸引力其实是两点:一是限时免费的 MiMo-V2.5 通道,零成本上手;二是原生兼容国内主流模型 API,不用折腾代理。开源 + MIT 协议也意味着企业可以放心 fork 内部部署。
顺带一提,OpenAI Hub 已经支持 MiMo-V2.5 系列模型,开发者如果想在 MiMo Code 里用同一个 Key 同时调 GPT、Claude、Gemini、DeepSeek 做 A/B 测试,直接把 base_url 指过去就行,省得一家家申请。
几个还需要观察的点
这个版本号是 V0.1.0,「探索性」三个字也写得很明白——小米自己也没把它当生产级工具发。几个待观察的问题:
- subagent 记忆系统的 token 开销和延迟实际表现如何,特别是 /dream 触发时
- Compose 模式生成的「工业级成品」实际质量,跟 Claude 4.x + Claude Code 的差距有多大
- 限时免费通道结束后的定价策略——参考其他报道,MiMo 编程套餐目前是 29/49/119 元三档,对应不同 prompts 配额
- 跟上游 OpenCode 的同步策略,是定期 rebase 还是逐渐分叉
对国内开发者来说,现在这个时间点尝鲜 MiMo Code 的成本基本为零——开源、免费模型通道、不用魔法上网。即便最后不留下,也能体验一下「记忆外包给 subagent」这套思路在实际编码场景里的手感。这或许才是 MiMo Code 这次发布最值得关注的部分:它不只是又一个 Claude Code 替代品,而是给长会话记忆问题提出了一个有工程美感的答案。
仓库地址在 GitHub XiaomiMiMo/MiMo-Code,感兴趣的可以直接 clone 下来看 Harness 实现。
参考来源
- IT之家:小米 MiMo Code V0.1.0 探索性 AI 编程助手发布并开源 — 首发报道,包含安装命令、记忆系统机制等核心信息
- GitHub:XiaomiMiMo/MiMo-Code — 项目源码与文档,MIT 协议
- Linux.do:小米 MiMo Code 发布并在 GitHub 开源讨论帖 — 社区讨论,含免费通道使用反馈
- 知乎:小米 MiMo-V2-Flash 编程能力测评 — MiMo 系列编码模型背景资料


