OpenAI酝酿Token大降价,被Anthropic和DeepSeek逼到墙角了

6月11日消息,OpenAI正考虑大幅下调Token收费,以应对Anthropic预期中的降价动作。背后是DeepSeek-V4-Pro把价格打到GPT-5.5的十分之一,整个API市场的定价逻辑正在被推倒重来。
OpenAI要降价了,这次是被逼的
6月11日,财联社援引消息人士报道,OpenAI正在内部讨论一轮幅度可观的Token价格下调,目标对手很明确——Anthropic。后者据传也在准备一波降价,OpenAI想抢在前面动手,把用户和开发者锁在自己这边。
这事的潜台词比新闻本身更值得品。过去两年OpenAI从来不是靠价格说话的那家公司,GPT-4刚上线的时候输入端60美元/百万Token,敢这么定价是因为没人能替代它。现在它开始认真考虑价格战,说明市场结构变了。
变化的核心信号有两个:一是Anthropic在Coding场景把Claude Code推成了头部工具,企业客户的Token消耗量正在向Anthropic倾斜;二是DeepSeek-V4-Pro在5月底那波永久降价之后,整个API市场的锚定价格被拉下了一个量级。OpenAI想守住份额,光靠模型能力已经不够了。
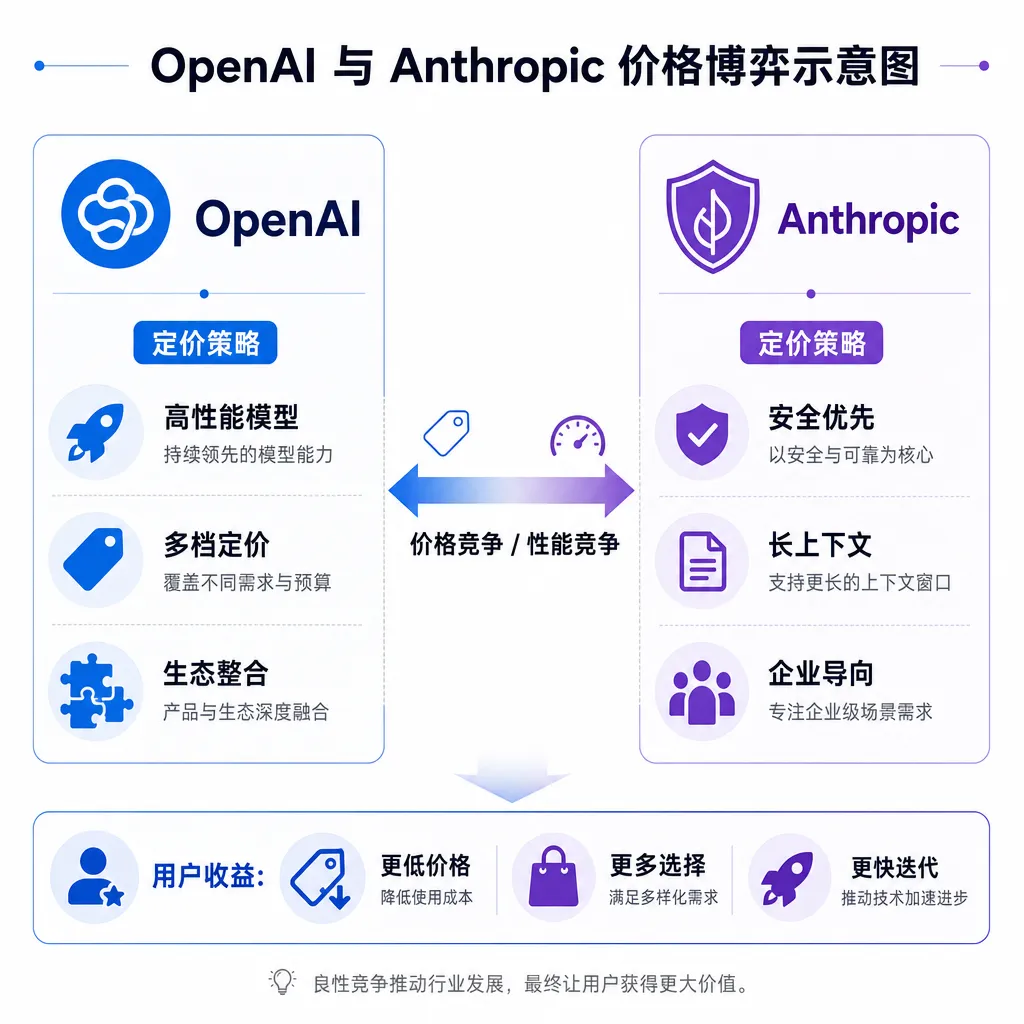
价格表对比:差距已经离谱到不像同一个行业
先把现在的牌面摆出来。截至本周,主流闭源大模型的标准计费是这样的(每百万Token,美元):
| 模型 | 输入价 | 输出价 | 缓存输入 | |------|--------|--------|----------| | GPT-5.5 | 5.00 | 30.00 | 1.25 | | Claude Opus 4.7 | 5.00 | 25.00 | 0.50 | | DeepSeek-V4-Pro | 0.435 | 0.87 | 0.003625 |
输入端,GPT-5.5是DeepSeek的11.5倍;输出端这个倍数被放大到34.5倍。这不是溢价,这是断代。
更关键的是,DeepSeek-V4-Pro这次直接做了OpenAI和Anthropic两套API格式兼容,意思是开发者迁移成本几乎为零——把base_url和key换掉,原来的代码不用动。这种"无痛切换"的产品策略,比单纯降价杀伤力大得多。
OpenAI如果不动,等于把价格敏感型的工作负载——日志分析、批量处理、长上下文RAG、Agent循环调用——全部让出去。这些场景每天烧的Token量是按亿计的,谁便宜谁拿走。
Anthropic的"暗涨"和OpenAI的"明升"
更微妙的是Anthropic这一年在定价上的小动作。表面看Claude Opus 4.7的名义价格没动,但5月份它换了一套新的Tokenizer,同样一段中文文本,新分词器切出来的Token数最多能比旧版多35%。也就是说账面价格不变,实际账单悄悄涨了三成。
这种"暗涨"的玩法之前在SaaS行业很常见——SKU不变、配额缩水。但放到大模型API领域,开发者一对账就能算出来,所以这两周技术社区里关于Claude新分词器的吐槽帖明显多了起来。
OpenAI那边走的是另一条路。Codex在4月从"按消息条数"转向了"按Token用量"计费,订阅制的折扣窗口被收窄;同时100美元的Pro档位被推出来,把原本200美元那一档的高端用户往下压一压。明面上是"降低高端服务门槛",实际操作里也是"提高ARPU"——把按消息时代被折扣覆盖掉的重度用户,按Token实打实地收回来。
两家加起来的结论是:包月折扣时代基本结束了,回到按量计费。这对开发者其实是好事,但前提是按量计费的单价得讲道理。现在OpenAI准备主动降价,就是承认当前这个单价已经不讲道理了。
算力账:降价的空间到底有多大
外界关心OpenAI能降多少。这里有两条约束:
第一条是推理成本。OpenAI从今年初开始把推理负载逐步迁到自研的Stargate集群和博通定制芯片上,单位Token的电力+硬件折旧成本,根据SemiAnalysis的拆解,相比纯H100集群下降了大概40%。这部分省下来的钱,理论上可以全部反映在价格上。
第二条是现金流。OpenAI今年的资本开支预计超过400亿美元,光是数据中心建设和长期算力承诺就是个无底洞。它没法像DeepSeek那样真正把价格干到地板上——后者背靠幻方的自有资金和相对克制的扩张节奏,OpenAI每降一美分都要算到模型投入产出曲线上。
所以这次大概率的剧本是:
- 主力模型(GPT-5.5、GPT-5.5-mini)输入端下调30%-50%
- 输出端动作更激进,可能腰斩
- 缓存输入继续做文章,把高频复用场景的价格压到极低
- 旗舰推理模型(o系列)维持高价,作为"专业版"留给企业
这套打法的意思是:日常工作负载我接住,高端推理我守住毛利。和Anthropic拼的是中间那一段——Coding、Agent、长文档处理。
对开发者意味着什么
降价这种事,开发者乐见其成,但要谨慎对待几个细节:
1. Tokenizer的猫腻得自己算。 Anthropic那个分词器涨35%的教训摆在那里,OpenAI如果一边宣布降价一边悄悄换分词器,账单未必会下来。建议在切换模型版本之前,用自己业务里的真实样本跑一遍tiktoken和对应模型的分词器,看看每千字到底分出多少Token。
2. 缓存命中率决定真实成本。 现在主流API的缓存输入价格普遍是标准输入的1/4到1/100。如果你的Prompt结构稳定(比如固定的System Prompt + 工具描述 + 用户输入),命中率能拉到80%以上,实际单价比报价表上的数字低得多。降价之后这个差距可能会被进一步放大。
3. 多模型路由会变成标配。 当价格差距从2倍拉到10倍,单一模型架构在经济性上就站不住脚了。简单任务走DeepSeek或者GPT-5.5-mini,复杂推理走Claude Opus或者o系列,已经是过去半年里成熟团队的默认架构。OpenAI这次降价如果落地,会让"GPT做兜底"重新变成一个合理选项。
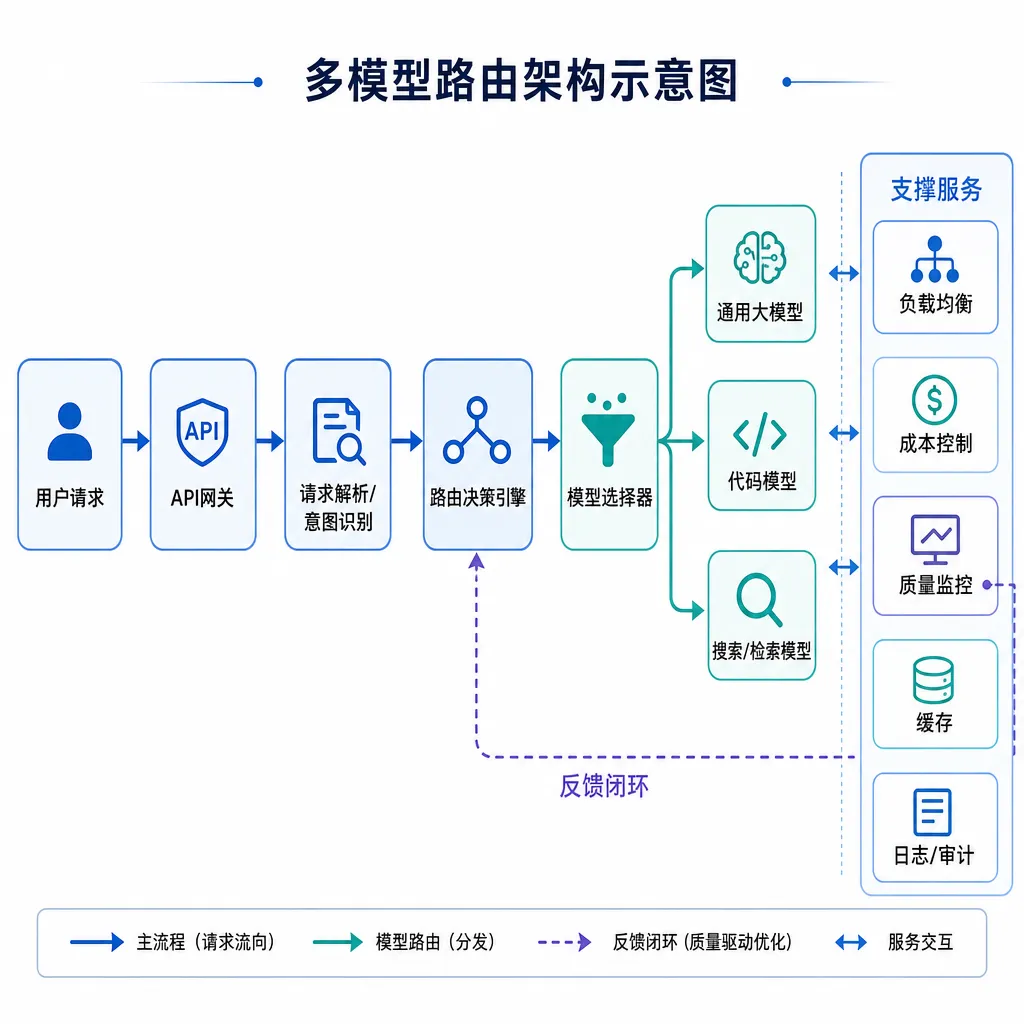
平台侧的反应
这种价格震荡对聚合平台是利好。OpenAI Hub(openai-hub.com)这种用一个Key打通GPT、Claude、Gemini、DeepSeek的平台,本质上就是帮开发者吃下"模型套利"的红利——哪家便宜走哪家,哪家好用走哪家,统一OpenAI格式,国内直连不用折腾代理。
如果OpenAI这轮降价落地,聚合平台的路由层会更有意思:同一个gpt-5.5的请求,根据实时价格和延迟自动选择最优供给路径,开发者那边只看到一个端点。这种玩法在去年还显得有点超前,今年已经是不得不做的事情。
谁会先扛不住
往下看半年,最难的不是OpenAI,也不是Anthropic,而是夹在中间的二线闭源模型。Cohere、Mistral的闭源旗舰、AI21这些玩家,定价比OpenAI低不了多少,能力又追不上头部,DeepSeek这种开源高性能模型从底下顶上来,OpenAI Anthropic从上面压下来,他们的生存空间在被压缩。
Google Gemini相对特殊,靠TPU的成本结构和Google Cloud的捆绑销售,能在价格战里多撑几轮。但Gemini 2.5/3.0这一代在Coding和Agent场景的口碑还没完全打开,企业Token消耗主要还在OpenAI和Anthropic两家。
至于国内一线(Qwen、GLM、豆包、Kimi),价格本来就不高,DeepSeek这波降价之后大概率会跟一轮。开发者侧的体感是,国产模型API的边际成本正在快速逼近零。
写在最后
OpenAI考虑大幅降价这件事,传递出来的信号比降价本身更重要:大模型API正在从"独家技术溢价"变成"算力服务商品"。能力差距还在,但已经不足以支撑10倍以上的价格差。
这对整个开发者生态是好事。当调用一次GPT的钱从一杯咖啡降到一颗糖,很多原本因为成本算不过来而放弃的应用场景会重新被点亮——批量内容审核、全量日志分析、AI驱动的BI、长周期Agent任务。这些场景在过去两年一直停留在Demo阶段,不是技术不行,是单位经济模型跑不通。
2026年下半年的看点,是OpenAI这次降价的幅度和节奏。如果只是象征性地砍个20%,Anthropic不会跟;如果一刀下去40%-50%,整个行业的价格表会在两周内全部刷新。
现在就看奥特曼那边到底有多焦虑了。
参考来源
- OpenAI明升,Anthropic暗涨:AI包月折扣没了 - 知乎专栏 - 关于Anthropic新Tokenizer带来的隐性涨价分析,以及OpenAI Codex从按消息转向按Token的计费变化


