苹果把CoreML埋了,CoreAI接棒押注端侧大模型
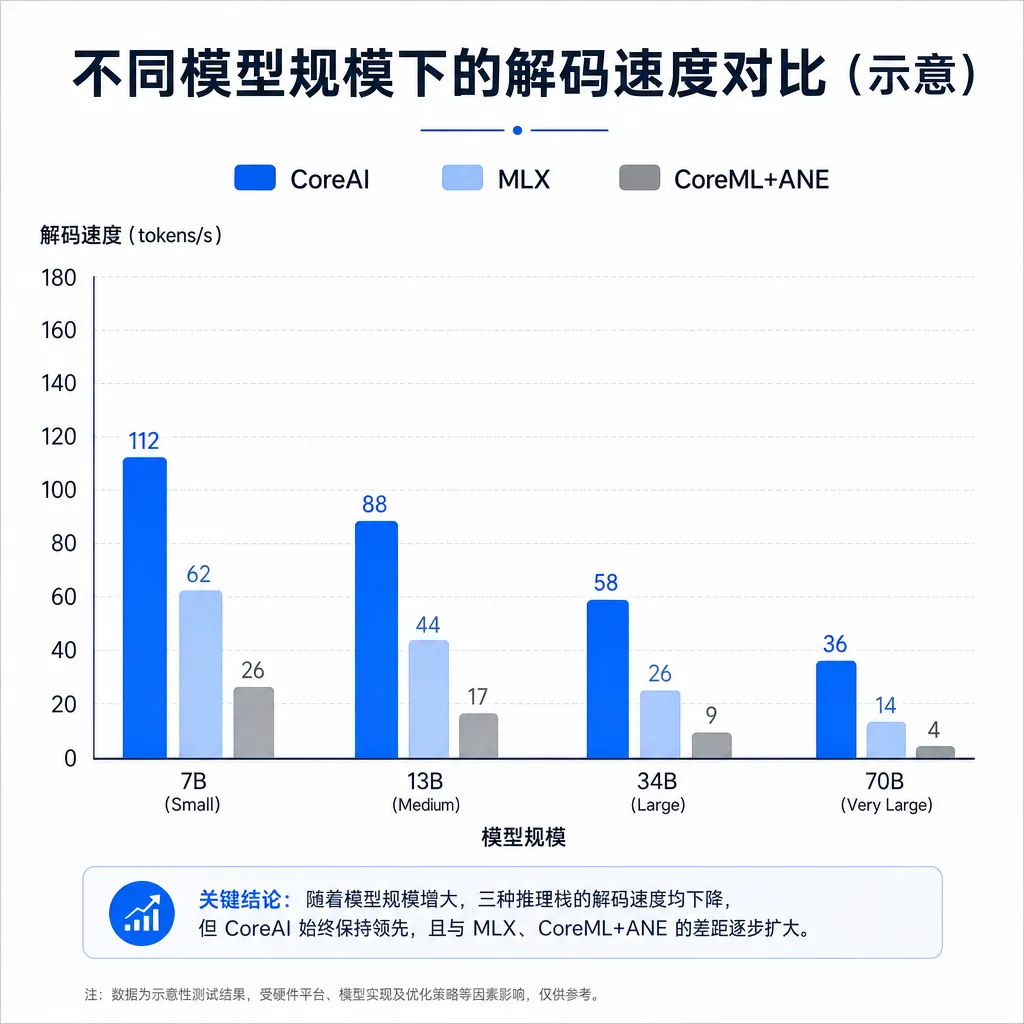
WWDC 2026上,苹果用CoreAI替换了服役九年的CoreML,专门为端侧大语言模型推理设计。首批基准测试显示,M4 Mac跑Qwen3 0.6B时,CoreAI解码速度是MLX的2.47倍,但模型一旦上到8B,优势就只剩5%。
苹果在 WWDC 2026 上把 CoreML 送进了博物馆。
6 月 10 日,库比蒂诺正式发布了 CoreAI 推理引擎,接替服役了整整九年的 CoreML 框架。这不是一次例行版本号迭代,而是底层架构换血——CoreML 当年是给 iOS 11 的图像分类、人脸识别这类小型静态任务准备的,2017 年的算力假设拿到 2026 年看大语言模型,已经是两个时代的产物。CoreAI 的目标只有一个:让端侧大模型在 Apple Silicon 上跑得动、跑得快。
从首批第三方基准来看,苹果这次没有完全交白卷,但也算不上交了一份惊艳的卷子。
小模型场景:CoreAI 把 MLX 按在地上
先说最亮眼的数据。在 M4 芯片的 Mac 上运行 Qwen3 0.6B,CoreAI 的解码速度大约是 MLX 的 2.47 倍。换到 iPhone 17 Pro 上,这个优势收窄到 1.6 倍,但依旧明显。
解码速度(tok/s)这个指标对开发者来说不用解释——它直接决定了用户按下回车后,到底要等屏幕一个字一个字蹦多久。0.6B 这种规模的模型,在端侧的典型场景是文本补全、邮件摘要、本地搜索意图理解,对延迟敏感、调用频率高。CoreAI 在这个量级上能拉开 2 倍多的差距,意味着同样的产品体验,可以省下一半电量,或者让一台 M1 时代的旧设备也能跑得起来。
这里要插一句 MLX 的定位。MLX 是苹果 2023 年底推出的机器学习框架,但它从一开始就更偏研究和训练侧,开发者社区拿它来跑本地大模型,多少有点"借来的车开高速"的意思。CoreAI 是专门为推理而生的,针对苹果统一内存架构、Metal 后端、ANE 神经引擎做了端到端优化,跑赢 MLX 在工程上属于预期内。
大模型场景:优势曲线急速收窄
但故事到了 8B 量级就开始变味。
在 M4 Max 上跑 Qwen3 8B,CoreAI 只比 MLX 快了 5%。这个数字在统计意义上几乎可以忽略——任何一次系统后台进程的扰动都能吃掉这 5% 的优势。
这意味着什么?意味着 CoreAI 当前版本的优化红利集中在小模型路径上,可能跟它对动态形状、KV cache 复用、小批量推理的针对性优化有关。一旦模型规模上去,矩阵乘法本身的带宽和算力成为瓶颈,框架层面能做的文章就少了,大家都在拼底层硬件的极限。
这其实给苹果的产品策略画出了一条清晰的边界:苹果的算盘是把 0.5B-3B 这个区间的模型做成系统级能力——Apple Intelligence 的本地模型、写作工具、Siri 的本地推理路径,全部落在 CoreAI 擅长的甜蜜点上。至于开发者想在 Mac 上跑 8B、14B 甚至更大的模型,老老实实用 MLX 也不会吃太多亏。
ANE 还是 GPU?iPhone 17 Pro 暴露的温控老问题
更有意思的一组数据来自持续负载测试。iPhone 17 Pro 在长时间推理后,GPU 路线会比较快触发温控降频,吞吐量明显回落。而 CoreML 配合 ANE(Apple Neural Engine,苹果神经引擎)的老组合,反倒在性能保持率上完成了反超。
这是一个老生常谈但被反复忽略的问题:在手机上跑大模型,峰值性能不重要,稳态性能才重要。用户问一个长问题,模型要连续生成 30 秒文本,前 5 秒飞快、后 25 秒像便秘的体验,比从头到尾稳定中速更糟糕。
ANE 路线为什么稳?因为它是定点低精度计算单元,功耗墙天花板低、单位算力的发热量小;GPU 走的是浮点高吞吐路线,跑得快但热得也快。CoreAI 当前主推 GPU 路径换取吞吐,但在移动设备这个发热敏感的场景,可能需要把 ANE 重新纳入调度策略,做成"短任务上 GPU、长任务回落 ANE"的混合方案。
横向对比:谷歌 LiteRT-LM 才是真正的隐藏王者
如果只看苹果自家的内卷,CoreAI 算是交差了。但拉到行业坐标系里看,问题就出来了。
谷歌的 LiteRT-LM 在 iPhone 17 Pro 上跑 Gemma 模型,每秒 55.4 tokens,内存占用仅 641 MB。作为对照,苹果 MLX 跑同等规模的负载,内存占用 2900 MB,是前者的 4.5 倍。
这是一个相当尴尬的对比。一个跨平台框架,在苹果自家的硬件上,做出了比苹果自家工具链更高效的内存表现。原因也不复杂——LiteRT-LM 是针对 Gemma 系列做深度定制的"模型专用引擎",量化策略、算子融合、KV cache 布局全部为 Gemma 量身打造。CoreAI 和 MLX 走的是通用路线,要照顾任意模型结构,必然要在普适性和极限性能之间妥协。
这件事的潜台词是:端侧 AI 的下一个战场不是通用框架,而是"模型-引擎"垂直一体化优化。面壁智能的 MiniCPM4 用自研 CPM.cu 框架配合 InfLLMv2 稀疏注意力,把长文本推理加速做到 5 倍;小米小爱团队用投机推理在端侧做到 7-10 倍解码加速。这些方案都不通用,但都比通用方案快得多。
苹果如果想在端侧 AI 上真正领跑,CoreAI 之外可能还需要做出"苹果自家模型 + CoreAI"的深度绑定组合——就像谷歌 Pixel 上 Gemini Nano 的那种紧耦合关系。
开发者视角:CoreAI 值不值得迁移
对正在做端侧 AI 应用的开发者来说,这次更换的实际影响有几条值得划重点:
- 模型格式更灵活:CoreAI 放宽了对模型格式的支持,CoreML 时代那种"必须先转 .mlmodel"的痛苦工作流大概率能简化。
- 内存上限提高:CoreML 早期对大模型的内存映射支持有限,CoreAI 在这块明显是冲着 7B-13B 模型设计的。
- MLX 不会被废弃:苹果在大会上明确 MLX 继续作为研究和训练侧的工具链存在,CoreAI 主打推理部署。两套体系并行,类似 PyTorch 训练 + ONNX Runtime 部署的关系。
- 小模型迁移收益最大:如果你的产品恰好在 1B 以下规模、对延迟敏感,迁移 CoreAI 大概率立刻能拿到 1.6 倍以上的性能提升。8B 及以上规模,迁不迁差别不大。
一个略显克制的进步
平心而论,CoreAI 不是革命,是补课。苹果在 2024-2025 这两年里端侧 AI 战略一直被外界批评"雷声大雨点小"——Apple Intelligence 跳票、Siri 升级延期、第三方开发者拿不到趁手的工具。CoreAI 至少把开发者侧的工具链欠账还上了一部分。
但要把这件事说成"苹果重新定义端侧推理",就有点过誉了。小模型上的 2.47 倍优势,是对自家 MLX 的胜利,不是对行业最优解的胜利;持续负载下被自家老框架 CoreML+ANE 反超,更说明 GPU 路线在移动端的天花板真实存在。
苹果端侧 AI 的真正考验,是 iOS 19 上线后,那些跑在 CoreAI 上的系统级 AI 功能能不能让普通用户感受到"哦,我的 iPhone 真的变聪明了"。框架性能再漂亮,最后都要落到产品体验上接受用户用脚投票。
顺带一提,开发者如果想在端侧部署 Qwen3、Gemma 这类模型之前,先用云端 API 跑通业务逻辑、做产品原型,OpenAI Hub(openai-hub.com)兼容 OpenAI 格式、一个 Key 同时调 GPT、Claude、Gemini、DeepSeek 和 Qwen 系列,国内直连不用折腾代理,可以省掉前期对比选型的不少时间。端侧和云端的协同,本来就是未来的常态。
参考来源
- 苹果 CoreAI 端侧 AI 架构测试:M4 Mac 上 Qwen3 0.6B 解码速度是 MLX 的 2.47 倍 - IT之家 — IT之家关于 WWDC 2026 CoreAI 发布及首批基准测试结果的详细报道


