腾讯混元HPC-Ops升级:五大算子直击推理痛点

腾讯混元AI Infra团队再次更新开源的HPC-Ops算子库,新增五大关键算子,专门解决Attention长尾延迟、显存搬运和跨卡通信等工程瓶颈,多项指标超越现有开源基线。
腾讯又往HPC-Ops里塞了五个算子,这次是冲着推理工程的真痛点去的
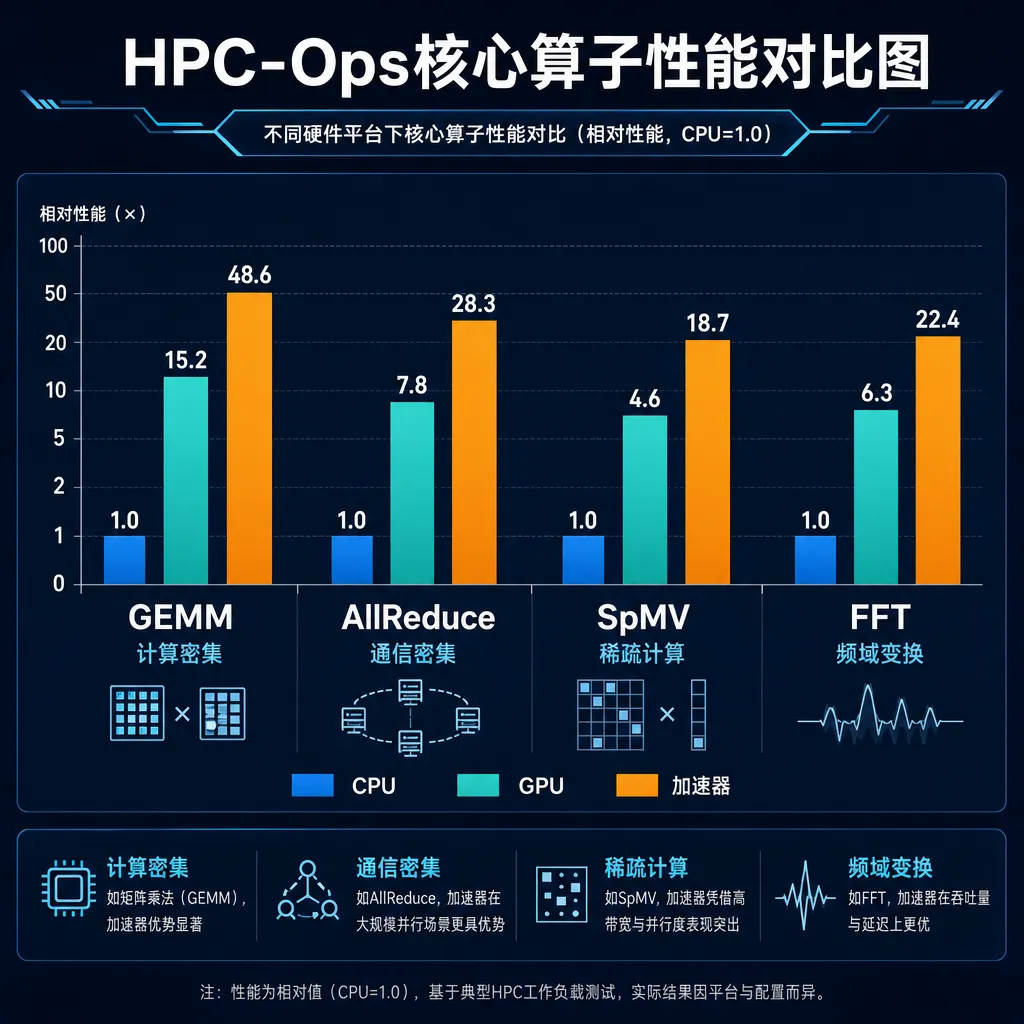
6月11日,腾讯混元AI Infra团队把开源的HPC-Ops算子库又推了一版升级,五个新算子一次性放出。要理解这次升级的分量,得先把时间线拉回今年2月——那时候HPC-Ops首次开源,靠着CUDA和CuTe从零手写,在真实生产场景里把混元模型的推理QPM干上去了30%,DeepSeek也跟着涨了17%。单算子层面,Attention对比FlashInfer/FlashAttention最高2.22倍,GroupGEMM对比DeepGEMM最高1.88倍,FusedMoE对比TensorRT-LLM最高1.49倍。这些数字在当时已经够让圈内人挑挑眉毛了。
四个月过去,新一波升级的目标更直白:把那些上线之后才会暴露的工程瓶颈一个个堵掉。
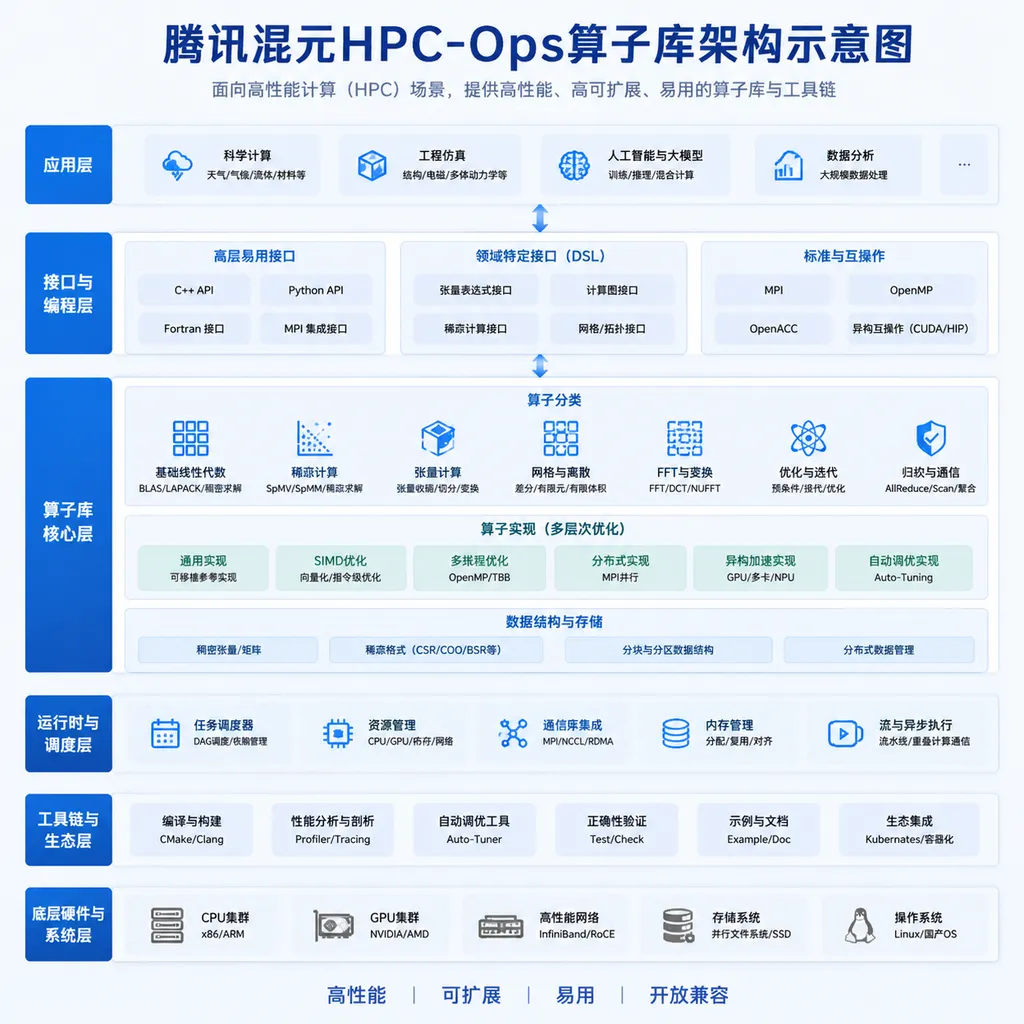
这次为什么是五个算子,而不是更宏大的叙事
做过推理部署的人都清楚一件事:benchmark跑得漂亮和线上扛得住,是两码事。一个算子在白皮书里平均延迟很低,但只要P99尾延迟一抖动,整个服务的SLA就会被拖垮。HPC-Ops这次升级的官方表述里有句话挺关键——「为了进一步满足推理系统对动态业务负载的适应性」。翻译成人话就是:之前那版在静态、规整的workload下打榜很猛,但真实流量是动态的、不规则的、长短交织的,那些场景里依然有油水可榨。
这次官方点名要解决的三类问题,全是工程层面的硬骨头:
- Attention长尾延迟:在变长序列、连续批处理(continuous batching)场景下,长序列请求会拉爆整批的延迟分布
- 显存搬运开销:现代GPU的算力和HBM带宽差距越拉越大,很多时候算子不是被算力卡住,是被搬运卡住的
- 跨卡通信:单机多卡、多机多卡的张量并行/专家并行场景,AllReduce、All-to-All这些通信原语跟计算的重叠程度直接决定吞吐
这三个方向,正好对应HPC-Ops团队此前公布的路线图——稀疏Attention、混合精度量化、计算通信协同优化。这次的五大算子,基本就是把那张路线图往前推了一步。
把算子库当工程项目做,而不是论文项目
要说HPC-Ops跟其他开源算子库最不一样的地方,是它的「出身」。FlashAttention系列、FlashInfer走的是学院派路线,论文先行,跑通学术benchmark;DeepGEMM是DeepSeek开源的,主打FP8 GEMM;TensorRT-LLM是英伟达官方的,闭源核多。HPC-Ops的定位更像是「我们在生产环境踩了无数坑,把解决方案抽出来开源」。
这种出身决定了它的几个特点:
第一,抽象化的工程架构。算子开发这件事,过去要么用CUTLASS这种偏底层的模板库,要么直接写CUDA Kernel,前者门槛高,后者难维护。HPC-Ops的做法是在CuTe基础上做一层抽象,让上层的算子开发者不用每次都跟tile、layout、swizzle这些概念死磕。降低了开发门槛,团队迭代速度也就上来了。
第二,微架构深度适配。Hopper(H100/H800)和Blackwell(B200)这一代GPU,引入了TMA、WGMMA这些新的硬件特性,能不能把它们用好直接决定算子能不能逼近硬件峰值。HPC-Ops在这方面做得相当细,特别是Attention和GroupGEMM上,TMA的异步加载和WGMMA的warp group协作被充分利用起来。
第三,指令级极致优化。这就是脏活累活了——PTX层面的寄存器分配、bank conflict规避、指令调度,一点点抠出来的性能。普通团队没那个耐心,也没那个机会成本去做这件事,混元有真实的混元模型和外部客户的DeepSeek部署场景在压着,做这件事的ROI才打得正。
跟谁比,比的是什么
来对一下竞品。FlashAttention 3已经把Attention推到了H100上接近理论峰值的程度,HPC-Ops能在它基础上再做到2.22倍,听起来匪夷所思,但仔细看就明白——FlashAttention 3的强项是规整长序列,对变长场景的优化是比较克制的。HPC-Ops显然是把变长、稀疏、长尾这些情况单独做了路径优化,所以在某些特定shape下能拉开这么大差距。这也提醒一件事:看benchmark一定要看具体配置,「最高提升2.22倍」是峰值,不是平均。
GroupGEMM对比DeepGEMM也是同理。DeepGEMM主打FP8,是DeepSeek MoE路径上的核心算子,HPC-Ops做到1.88倍,多半是在Group数量大、每个Group的M较小的场景——也就是真实MoE推理时专家激活不均匀那种状况。FusedMoE对比TensorRT-LLM做到1.49倍,这个分量更重,因为TRT-LLM是英伟达官方的,能在它眼皮底下拿到50%的提升,说明HPC-Ops在MoE融合的路径设计上确实有想法。
五大算子覆盖了哪些场景
虽然完整的技术细节要等代码仓库的更新和后续技术博客,但根据官方披露的三个方向,可以推测这次五大算子的大致分布:
- 稀疏/动态Attention类:针对长上下文场景,把KV Cache的访存压力降下来。现在大模型上下文动辄128K、200K,Attention的访存瓶颈才是真问题,算力反倒不缺。
- 量化GEMM/MoE类:混合精度的核心算子。4bit权重+8bit激活、W4A8这种组合在生产里越来越常见,把对应的高性能Kernel开源出来,对小团队部署大模型的友好度很高。
- 计算-通信协同类:把AllReduce、All-to-All融进GEMM或者MoE Kernel里,让通信跑在算力的影子里。这块是分布式推理最难啃的骨头,做好了能省下大量的跨卡等待时间。
# 典型的HPC-Ops算子使用方式(示意)
from hpc_ops import fused_moe, attention
# Fused MoE 调用
out = fused_moe(
hidden_states,
expert_weights,
topk_ids,
topk_weights,
quant_type="w4a8",
overlap_comm=True, # 计算通信重叠
)
# 变长Attention调用
out = attention(
q, k, v,
cu_seqlens,
sparse_pattern="block_sparse", # 稀疏模式
kv_cache_layout="paged",
)
这件事对开发者意味着什么
如果你是在自己机器上跑推理框架的中小团队,HPC-Ops能不能直接拿来用?答案是:可以,但有门槛。
好处是显而易见的:
- 直接节省成本:QPM提升30%意味着同样的GPU能多扛30%的流量,反过来说同样的流量能少买30%的卡。这笔账算下来不是小数。
- 国产模型友好:DeepSeek也吃到了17%的提升,说明HPC-Ops不是只优化自家模型的私货,对开源生态有真实贡献。
- 生产级的稳定性:腾讯内部混元在用,外部已经有客户跑DeepSeek,说明踩坑这件事腾讯帮你做过了。
但门槛也得提一句:
- 硬件要求高,对Hopper及以上架构的GPU优化最好,A100/A800上能跑但收益打折
- 集成到自己的推理框架需要工程能力,不是pip install就能用的程度
- 路线图还在迭代,稀疏Attention这些算子的稳定性还需要时间验证
一个更大的背景
2026年的AI Infra圈子,几个明显的趋势:MoE模型成为大模型主流形态,长上下文推理需求井喷,FP8/INT4等低精度推理从尝鲜变成标配,多卡多机部署成为日常。在这个背景下,推理引擎之间的竞争已经从「能不能跑」卷到了「跑得多快、多稳、多便宜」。
HPC-Ops的开源升级是腾讯在这场竞争里亮的一张牌。它的逻辑很清楚:把底层算子开源出来,让生态用起来,反向推动自家模型的部署效率和影响力。同样的剧本DeepSeek用DeepGEMM演过,英伟达用cuBLAS/cuDNN演过几十年,腾讯这次入场,意味着国内厂商在AI Infra的核心层面,开始有了能拿出来跟国际开源项目正面对线的东西。
对开发者来说,结果是好的——选择更多了,性能更卷了,部署成本更低了。至于HPC-Ops能不能成为下一代主流推理引擎的标配算子库,还得看后续社区接受度和持续迭代能力。但至少从今天放出来的这五个算子看,腾讯混元AI Infra团队是认真在做这件事的,不是冲着发个PR赚波关注。
值得一提的是,OpenAI Hub(openai-hub.com)作为AI API聚合平台,对混元、DeepSeek等主流国产模型一直有完整支持,国内直连,兼容OpenAI格式。如果想直接调用底层用上HPC-Ops优化的推理服务,是个比较省事的路径。
参考来源
- 腾讯混元 AI Infra 核心技术开源,推理吞吐提升 30% - IT之家:IT之家对HPC-Ops首次开源的报道,包含官方性能数据和后续路线图
- 腾讯混元AI Infra核心技术重磅开源:推理吞吐提升30% - 知乎专栏:知乎专栏对HPC-Ops技术细节的解读,包含CUDA/CuTe构建路径的分析


