大晓开悟Kairos世界模型横扫四大评测,4B参数干翻Cosmos 14B

大晓机器人开源具身原生世界模型Kairos 3.0-4B,在RoboTwin 2.0、LIBERO-Plus等四项评测拿下第一,推理速度比英伟达Cosmos 2.5快72倍,7分钟长视频生成把"世界模型"这件事真正拉到了能干活的水平。
一个 4B 的世界模型,把英伟达 Cosmos 14B 摁在地上摩擦
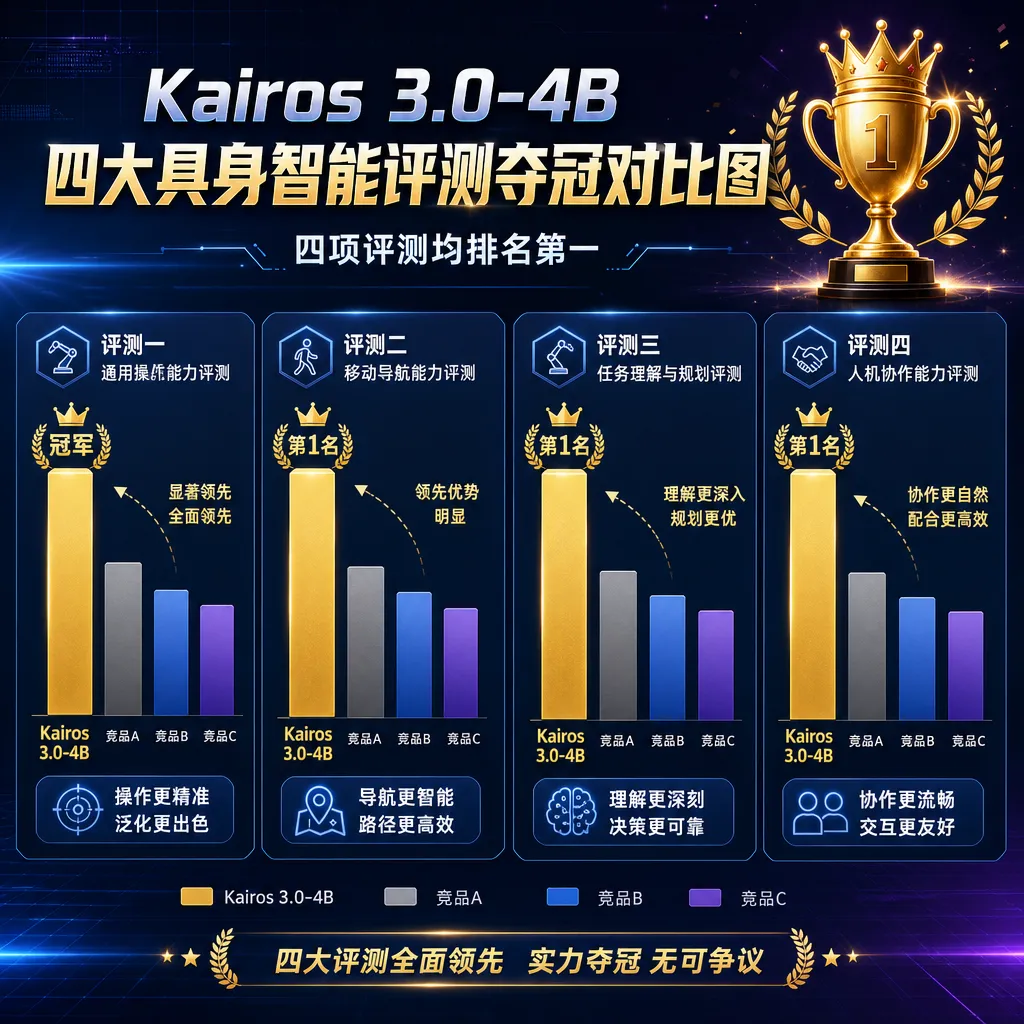
这两天具身智能圈讨论的不是哪家又发了人形机器人,而是大晓机器人的开悟世界模型 Kairos——RoboTwin 2.0、LIBERO-Plus、WorldModelBench Robot、DreamGen,四个目前业内最能打的世界模型/具身评测基准,第一名全被这家公司包圆了。模型权重直接挂上 GitHub 开源,名字叫 Kairos 3.0-4B。
说实话,世界模型这个赛道过去一年有点虚火。英伟达 Cosmos 出来之后,国内外一堆团队跟进,但绝大多数做法都是"在视觉/语言大模型后面接一个动作头",本质还是 VLA 思路的延伸。Kairos 这次的意义在于,它是从架构底层为"物理世界里的因果"重新设计的,而且性能拉爆了 Cosmos 2.5、阿里 Wan 2.2、蚂蚁 Lingbot 这一票竞品——4B 参数打 14B、28B,赢得还不止一点点。
先看数字:72 倍推理加速不是 PPT 数据
在 A800 GPU 的 Benchmark 上,Kairos 3.0-4B 完成 10 秒视频生成任务只用了 9.5 秒——这意味着它实现了云侧 1:1 的实时推理,生成时长基本等于视频时长。对比一下其他几家:
- Cosmos 2.5:687.2 秒(约 72 倍差距)
- 阿里 Wan 2.2:85 秒(约 9 倍差距)
- 蚂蚁 Lingbot:1436 秒(约 151 倍差距)
显存这块也很夸张。4B 参数只吃 23.5GB 显存,跟 5B 的 Wan 2.2 相当,但远低于 14B Cosmos 的 70.2GB、28B Lingbot 的 46.1GB。这个数字背后是大晓自研的"混合时间线性注意力算子"——具体怎么做的论文还没出,但从效果看,他们大概率重写了 attention 在时序维度上的计算路径,把世界模型最吃算力的"长序列+视频"两个维度同时拉下来了。
如果你做过视频生成模型部署,应该懂这个差距有多致命。Cosmos 2.5 14B 跑一个 10 秒视频要 11 分钟,这种速度别说控制机器人,连离线数据增强都嫌慢。Kairos 3.0-4B 的 9.5 秒等于把"世界模型驱动机器人"从一个研究问题变成了工程问题。
评测细节:PAI-Bench-robot 80.03 分,物理一致性领先 70%
四项 Benchmark 拿第一,含金量挨个看:
PAI-Bench-robot(佐治亚理工 + CMU 联合搞的物理 AI 综合基准)
这个基准覆盖 2808 个真实世界案例,是目前物理 AI 领域被引用最多的具身评测框架之一。Kairos 3.0-4B 拿 80.03 分,超过:
- Cosmos 2.5-2B:78.3
- 阿里 Wan 2.2-5B:78.6
- Cosmos 2.5-14B:79.4
- 蚂蚁 Lingbot:79.96
领先幅度看着不大,但要注意——它的参数量比 Cosmos 14B 小了 3.5 倍。
WorldModelBench Robot
这是长时序物理场景理解的硬指标。Kairos 拿 9.08 分,Cosmos 2.5-14B 是 8.94。注意,这个评测是"长时序"——越长的预测,物理误差越容易累积,传统模型在 5 秒之后就开始崩坏,Kairos 能稳到 7 分钟级别。
物理一致性 PA / 指令跟随 IF
- PA(Physical Accuracy):Kairos 0.529,阿里 Wan 2.2 只有 0.314,差距近 70%。
- IF(Instruction Following):Kairos 0.609,比 Cosmos 2.5-14B 提升 27%。
PA 这个指标差 70% 是什么概念?官方放的对比 demo 里有个倒水场景——把水从杯子倒进水槽。Kairos 生成的水流速度平稳、液体总量严格匹配杯子容量,符合质量守恒。Cosmos 2.5 和 Lingbot 的水流速度过快,甚至生成的液体总量远超杯子实际容量,物理逻辑直接崩了。
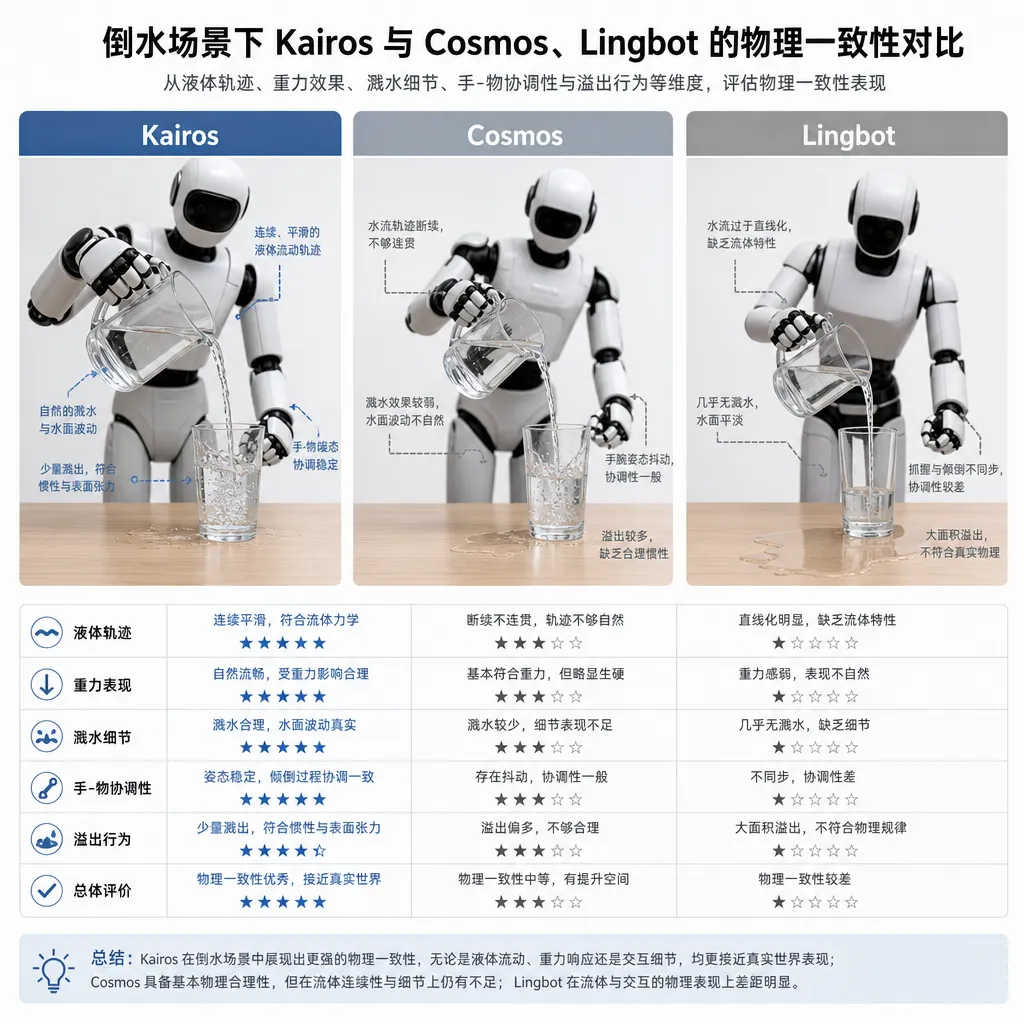
更狠的是叠平衡石场景。Kairos 严格遵循重力与支撑结构,每一块石头都堆在该堆的位置;Cosmos 2.5 生成的石头开始悬浮,Lingbot 直接让最底层石头凭空消失。
这种差距说明一件事:仅靠扩散模型 + 视频数据训练的"通用视频生成模型改款",在物理因果这个维度上是有天花板的。你训练数据里见过再多视频,也学不到"质量守恒"和"刚体力学",这两件事得在架构层面给它一个先验。
架构上做对了什么
Kairos 自称是业内首个实现"多模态理解—生成—预测"一体化的具身原生世界模型。"原生"两个字是关键。
业内目前主流路线分两派:
- VLA 派:在 VLM(视觉语言模型)后面接动作头,代表是 Figure 的 Helix、Physical Intelligence 的 π0。优势是复用 VLM 的语义理解,劣势是物理一致性靠数据堆。
- 视频生成派:把世界模型当作"可控视频生成器",代表是 Cosmos、Wan。优势是视觉真实度高,劣势是不懂因果,预测越长越离谱。
Kairos 走的是第三条路——把"理解—生成—预测"三件事在同一个网络里联合训练,认知根基是物理规律和因果规律本身,而不是视频数据的统计分布。这个思路其实和 LeCun 一直鼓吹的 JEPA 有相通之处,但 Kairos 把它做到了能跑机器人本体控制的程度。
端侧部署这块更有意思。Kairos 3.0-4B 是行业首个在英伟达 Jetson Thor T5000 端侧平台部署的具身世界模型。THOR 端侧算力 517 TFlops,Kairos 在上面达到了 1:1.5 的实时生成(生成时间:视频时长),这意味着机器人可以一边"想象"未来 1 秒会发生什么,一边实时调整动作。
而且模型直接输出机器人从上肢到手指再到下肢的全方位控制指令——没有中间的"世界模型预测→规划器→控制器"转译链。这是把世界模型当大脑用了,不是当模拟器用。
7 分钟长视频生成:长时序终于不崩了
大多数视频生成模型 5 秒以上就开始出现物体消失、属性漂移、物理崩坏。Kairos 3.0 能稳定生成 7 分钟的具身动态交互视频,这背后是它的"层级化任务解析 + 自我反思闭环"机制。
简单说就是:用户给一个复杂指令(比如"做早餐"),Kairos 智能体先把它拆成子任务序列,每个子任务对应一段时空演化的物理预测,生成过程中通过自我反思机制做闭环迭代优化。
官方放的家庭场景 demo 里,机器人完成了一整套全流程自主作业:
- 整理桌面上的杯子和纸巾盒,规划摆放位置
- 自主进入洗衣区,捡衣服、开洗衣机、放进去、启动
- 穿过客厅进厨房,开冰箱取牛奶、开壁橱取麦片、开抽屉取碗勺
- 把麦片和牛奶倒进碗,完成早餐制备
这套流程里,"打开冰箱"和"倒牛奶"之间的因果关系是模型自己推理出来的——这就是世界模型作为"大脑"的能力,VLA 模型靠模仿数据是干不出来的。
对行业意味着什么
说几个判断:
第一,开源策略很狠。 4B 参数 + 23.5GB 显存 = 一张消费级 A6000 甚至 4090 24G 都能跑得动。这种部署门槛意味着学术界和中小团队可以直接基于 Kairos 做二次研究,国内具身智能的研究生态会被显著加速。GitHub 仓库已经放出:github.com/kairos-agi/kairos-sensenova。
第二,Cosmos 的优势没了。 之前国内做世界模型的团队普遍把英伟达 Cosmos 当 baseline,现在 baseline 被一个开源模型反超 72 倍速度+全面碾压物理指标,下一轮工作的对标对象会切换。
第三,端侧实时是真正的拐点。 如果你做过具身智能数据采集,应该知道仿真和遥操作有多痛苦。世界模型能在端侧 1:1.5 实时生成,意味着机器人可以在物理执行前用"想象"做行为预演——这是把强化学习的"试错"成本压到接近零的关键技术。
当然 Kairos 也不是没有质疑空间。比如 7 分钟长视频的物理一致性在哪些任务上能保住?跨本体泛化的"跨本体"边界在哪?这些都得等更多第三方复现的结果出来。但从目前公开的 Benchmark 和 demo 看,这家公司至少把"世界模型驱动具身"这条路推进了一大截。
顺便提一句,对 AI 应用开发者来说,多模型并用已经是常态。OpenAI Hub(openai-hub.com)一个 Key 调 GPT、Claude、Gemini、DeepSeek 这些主流模型,兼容 OpenAI 格式国内直连,做 agent 编排的时候省心不少。开源具身模型这边,本地部署仍然是主流路径,但用云端大模型做高层规划+本地 Kairos 做物理预测的混合架构,已经有团队开始试了。
写在最后
2026 年具身智能这条赛道,最有意思的不是又一台人形机器人发布,而是世界模型这个之前看着像研究玩具的东西,真的开始能让机器人干活。Kairos 这次开源把整个赛道的工程门槛拉到了一个新的水位——4B 参数能跑、A800 实时推理、端侧能控制本体——剩下的事情,就看社区接力了。
参考来源
- Kairos 官方 GitHub 仓库 - 开悟世界模型 Kairos 3.0-4B 开源代码和模型权重


