商汤开源 SenseNova U1:把理解和生成揉成一个大脑

商汤开源原生统一多模态模型 SenseNova U1,基于自研 NEO-unify 架构,干掉视觉编码器和 VAE,让理解、推理、生成在同一个表征空间里跑。8B 版本就能对标 Qwen-Image 2.0 Pro、Seedream 4.5 等闭源大模型。
商汤把多模态模型的"中间商"砍掉了
4 月底商汤把 SenseNova U1 系列开源出来的时候,圈里讨论了一阵,但真正能上手跑模型、看到图文交错效果的,是最近几周才陆续多起来的——HuggingFace 上的下载量这一个多月翻了好几倍,Discord 里发图文交错内测码的频率也明显加快。这事值得单独拎出来说一下,因为它解决的是一个老问题:理解和生成的割裂。
做过多模态的人都清楚,传统方案基本是个"接力赛":视觉编码器(VE,比如 CLIP、SigLIP)负责把图像翻译成 token,语言模型负责理解和推理,要画图的时候再丢给扩散模型(带 VAE)去生成。三段拼接,每一段都是独立训练的领域,中间靠 adapter 缝合。这种架构在工程上很务实,但天花板也清楚——理解的时候图像信息已经被压缩过一次,生成的时候语义又要从 LLM 的 hidden state 重新"翻译"成视觉控制信号,损耗叠损耗。
商汤这次的 SenseNova U1 走的是另一条路:NEO-unify 架构,把 VE 和 VAE 都扔了。语言和视觉信息共享一个表征空间,从底层就当作一个复合体来建模,理解任务和生成任务在同一组参数里完成。
听上去像理想化的方案,但他们真把 8B 规模的模型跑出了对标闭源大模型的效果——这就有意思了。
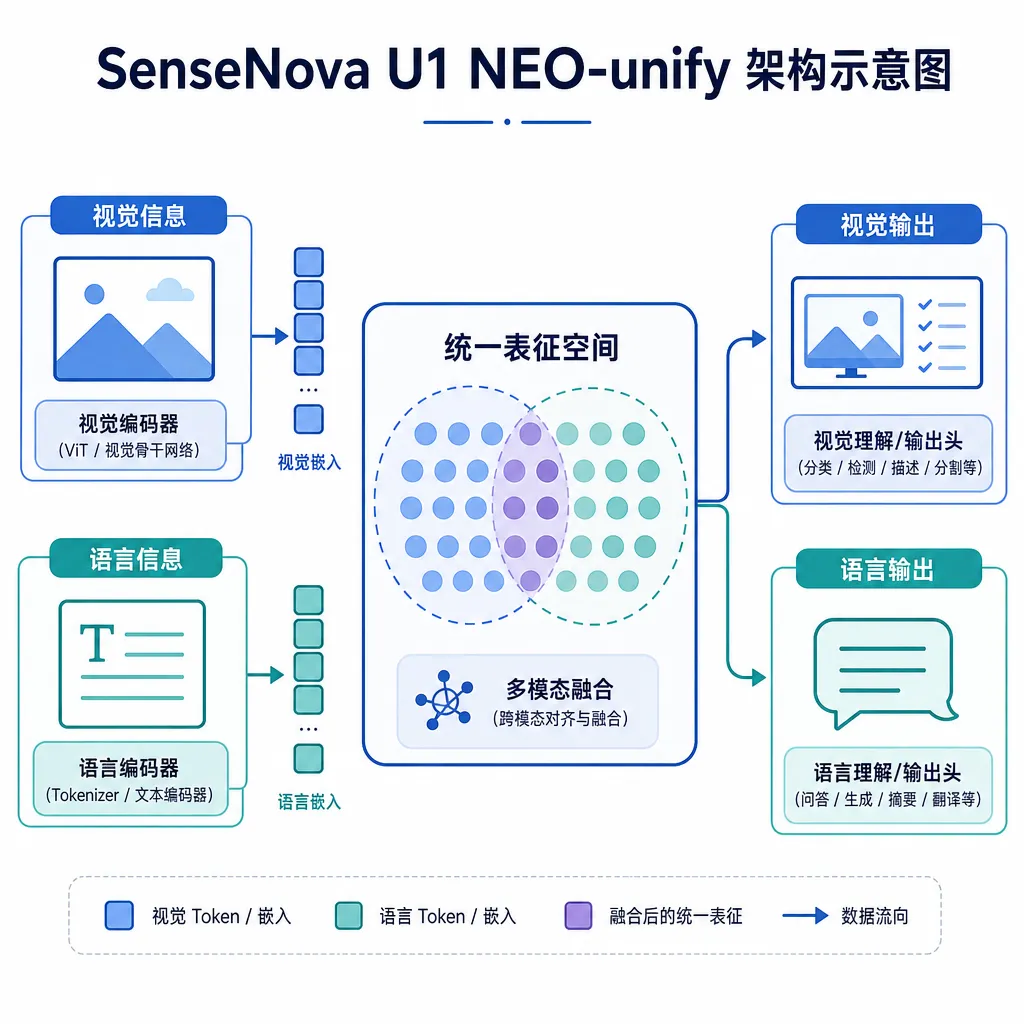
NEO-unify 到底改了什么
这里得把架构这件事讲透一点,否则容易跟"多模态大一统"这种口号混为一谈。市面上喊"统一多模态"的不止商汤一家,但路线分歧很大。
大致有三条路:
- 拼接派:LLaVA、InternVL、Qwen-VL 这一类,视觉编码器 + LLM + 可选的扩散头。优点是工程成熟,缺点是理解强、生成弱,或者反过来。
- 离散 token 派:把图像 VQ 化成离散 token,跟文本 token 混在一起喂给 Transformer,比如 Chameleon、Emu3。统一性强了,但图像质量普遍上不去——VQ 重建本身就是有损的。
- 原生连续派:图像和文本都用连续表征,从架构层面就不区分模态。NEO-unify 属于这一派,且更激进,连 VAE 这个"压缩-解压"的中间环节也省了。
商汤的描述是"模型不需要依赖单纯堆大参数来弥补中间转换的损耗,而是通过统一的内部表征,把不同模态的信息以更紧凑、更高密度的方式组织起来"。这话听着像 PR,但有个直接证据——8B 参数能对标 Qwen-Image 2.0 Pro 和 Seedream 4.5 这种十几倍大的闭源模型。如果信息流没被压扁、被翻译,参数的利用效率确实会高很多。
打个比方:传统架构像是公司里"视觉部"画图、"语言部"写文案,中间靠 PPT 沟通;NEO-unify 像一个全栈设计师,脑子里图文是一回事,直接出成品。少了开会环节,效率自然上去。
开源了哪两个版本
这次首批开源的是 Lite 系列,两个规格:
- SenseNova-U1-8B-MoT:稠密骨干,8B 激活全开,适合追求质量上限、显存充裕的场景
- SenseNova-U1-A3B-MoT:MoE 架构,激活参数约 3B,推理成本更低,适合规模化部署
MoT 是商汤自己用的命名(Mixture-of-Tokens 之类),核心还是统一表征 + 多模态联合训练。两个模型都是同一架构下的不同骨干选择,能力覆盖图像理解、文生图、图像编辑、空间推理、图文交错生成。
仓库地址都在:
- GitHub:
OpenSenseNova/SenseNova-U1 - HuggingFace:
sensenova的 SenseNova-U1 collection
另外还放出了 8 步 LoRA 加速版本(SenseNova-U1-8B-MoT-LoRA-8step-V1.0.safetensors),把生成步数从 50 步压到 8 步——这对实际部署来说很关键,原版 50 步走完一张高分辨率信息图,3090 上得等几十秒,8 步 LoRA 基本能压到秒级。
实测下来什么感受
我让它跑了几个比较典型的场景,挑重点说。
第一类是复杂信息图。 这是开源模型一直做不好的活——文字排版、图标布局、配色一致性,原生扩散模型基本会糊掉一半文字。SenseNova U1 在这块的表现确实超出预期,生成一张 16:9 的科技风信息图(标题、副标题、三栏布局、图标 + 文字混排),文字基本不糊、版式比例合理,达到了商业级模板的水准。不算完美,长 prompt 写到 1000 字以上偶尔会丢细节,但跟同等开源模型比已经拉开差距。
第二类是图文交错创作。 这是 NEO-unify 架构最能体现优势的场景。比如让它讲"五分熟牛排的做法",它会思考 + 规划 + 分步输出,每一步配一张对应的图。关键是这些图之间的风格一致性——锅具、灯光、摆盘的视觉特征能在多步之间稳定保持。换做传统的"LLM 调用文生图 API"方案,每次调用都是独立采样,风格漂移得厉害;U1 在统一表征里完成上下文持续,图与图之间的连贯性是天然的。
商汤自己强调"业内首个实现连续性的图文创作输出,单次单模型调用"——这句话不是夸张。过去要做这种效果,得 LLM 生成脚本 + 文生图 + 风格 LoRA + ControlNet 一顿组合拳,工程链路一长就脆。U1 一个模型走完,链路上的失败概率显著降低。
第三类是图像编辑。 给一张猫的图片,prompt 写"把毛色改深一点",它能精准地只改毛色、保留构图和细节,没有那种"重画一遍但有点像"的尴尬。这其实又是统一表征的优势——理解"哪里是毛色"和生成"修改后的图"用的是同一套表征,对齐度天然更高。
怎么本地跑起来
仓库给的依赖管理是 uv,体验比 pip 顺一些:
git clone https://github.com/OpenSenseNova/SenseNova-U1.git
cd SenseNova-U1
uv sync
source .venv/bin/activate
# 下载权重(魔搭或 HF 都行)
modelscope download --model SenseNova/SenseNova-U1-8B-MoT \
--local_dir ./SenseNova/SenseNova-U1-8B-MoT
文生图调用:
python examples/t2i/inference.py \
--model_path SenseNova/SenseNova-U1-8B-MoT \
--prompt \"一张极简科技风信息图,标题 SenseNova-U1...\" \
--width 2720 --height 1536 \
--cfg_scale 4.0 --timestep_shift 3.0 --num_steps 50 \
--output output.png
图像编辑:
python examples/editing/inference.py \
--model_path SenseNova/SenseNova-U1-8B-MoT \
--prompt \"Change the animal's fur color to a darker shade.\" \
--image input.jpg \
--cfg_scale 4.0 --img_cfg_scale 1.0 --num_steps 50 \
--output output_edited.png --compare
8 步 LoRA 加速:
modelscope download --model SenseNova/SenseNova-U1-8B-MoT-LoRAs \
\"SenseNova-U1-8B-MoT-LoRA-8step-V1.0.safetensors\" \
--local-dir ./SenseNova/SenseNova-U1-8B-MoT-LoRAs/
python examples/t2i/inference.py \
--model_path SenseNova/SenseNova-U1-8B-MoT \
--lora_path ./SenseNova/SenseNova-U1-8B-MoT-LoRAs/SenseNova-U1-8B-MoT-LoRA-8step-V1.0.safetensors \
--num_steps 8 --cfg_scale 1.0 \
--jsonl examples/t2i/data/samples.jsonl \
--output_dir outputs/
显存方面,8B-MoT 跑 FP16 推理大概 20GB 起步,单卡 4090 能跑;A3B-MoT 由于 MoE 的关系,权重总量大但激活小,推理显存压力比 8B 还小一点,适合做服务端部署。
跟谁比,差距在哪
这次开源比较微妙的一点是:商汤选的对标不是其他开源统一模型,而是直接把 8B-MoT 拎出来跟闭源商用模型比。Qwen-Image 2.0 Pro、Seedream 4.5 这两个是国内文生图第一梯队,参数体量都是几十 B 级别。商汤给的官方对比图里,U1 Lite 在生成质量上"比肩",推理速度"显著优势"。
实测下来我个人的判断:
- 写实人像 / 自然场景:U1 Lite 略弱于 Seedream 4.5,肤质和光影细节上闭源大模型还是有积累优势
- 信息图 / 排版 / 文字渲染:U1 Lite 反超,开源模型里目前没有对手
- 图像编辑:U1 Lite 跟 Qwen-Image-Edit 互有胜负,但 U1 的语义理解明显更精准
- 图文交错连续创作:U1 Lite 是目前能落地的唯一选择
所以这个开源不只是"又一个文生图模型",而是把图文交错和信息图生成这两个商业刚需场景的开源天花板拉高了一大截。
这事意味着什么
往大了说,原生统一多模态是过去两年学术界一直在推但工业界落地很慢的方向——主要原因是训练成本高、数据需求大、稳定性差。Chameleon 出来时大家觉得是方向,但实际效果跟拼接派比并没有压倒性优势;Emu3 路线相似但工程门槛劝退了不少团队。
商汤这次能把 NEO-unify 跑到 SOTA,且大方开源,等于给社区一个"原生统一路线可行"的工程参考。后续无论是社区做继续训练、做行业微调,还是其他厂商做架构借鉴,都有了实物可对照。
往小了说,对开发者最直接的价值有三:
- 图文交错能力可以塞进 Agent 了——之前做带图输出的 Agent 链路又长又脆,现在一次调用搞定
- 信息图、教程图、长图文创作这类内容生产任务有了开源方案
- 空间智能和物理推理方向有了底座——商汤明确提到未来会推机器人具身大脑,U1 是地基
OpenAI Hub 也已经在跟进对接,预计后续会提供托管版本的 U1 API,开发者通过同一个 Key 就能在 GPT、Claude、Gemini、DeepSeek 之外,再加一个原生统一多模态的选项。对于做多模态应用的人来说,少切一次平台、少写一套 SDK,价值还是挺实在的。
商汤说未来会继续 Scale,推更大参数的 U1。如果 NEO-unify 在更大规模上还能保持效率优势,那原生统一这条路线大概率会变成下一代多模态的主流形态——拼接派的舒适期,可能也就剩这一两年了。
参考来源
- SenseNova-U1 开源仓库(GitHub) — 代码、模型权重下载和推理示例
- SenseNova-U1 HuggingFace Collection — 模型卡片、LoRA 加速权重
- linux.do 上的图文交错内测案例分享 — 社区用户实测图文交错功能的效果与体验
- 知乎:商汤多模态"效率怪兽"开源即 SOTA — 技术细节与基准测试解读


