华为开源盘古 2.0:505B 参数押注昇腾,余承东要"从中国第一走向世界第一"

华为在 HDC 2026 发布开源盘古 openPangu 2.0,Pro 版总参 505B、激活 18B,专门为昇腾算力和鸿蒙生态做了深度优化。余承东承认"留的算力很有限",但喊话要拿世界第一。
今天下午的华为开发者大会 HDC 2026 上,余承东把开源盘古的牌彻底翻开了:openPangu 2.0 正式发布,最大规格 505B 参数(激活 18B),上下文 512K,6 月 30 日起分批开源 7 大组件,连预训练代码、后训练代码和训练算子都一起放出来。
这事的看点不全在参数表。台上余承东那句"我余生的字典里,没有第二,只有第一,我们会从中国第一走向世界第一",配合他坦言"留给盘古的算力非常有限,因为大部分昇腾算力都给了国内其他企业"——这两句话一前一后,基本把华为现在做大模型的处境和姿态都摆清楚了:算力不富裕、但必须做、而且要做到第一。

一、参数表:Pro 与 Flash 双版本,激活量克制得有点反常
先把硬指标摆出来:
- openPangu 2.0 Pro:总参数 505B,激活参数 18B,MoE 架构
- openPangu 2.0 Flash:总参数 92B,激活参数 6B
- 上下文长度:512K(两版统一)
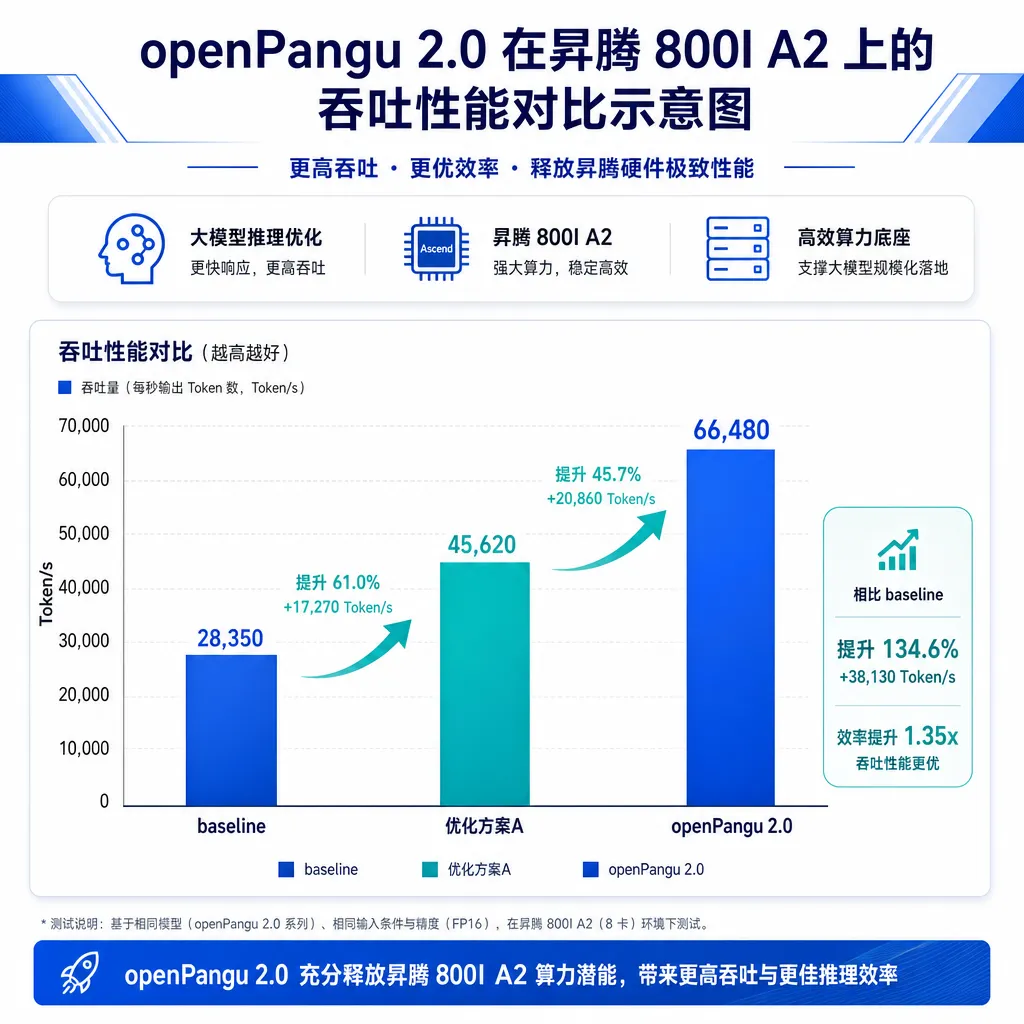
- 单卡吞吐:昇腾平台上达到业内主流开源模型的 2 倍
- 开源时间表:2026 年 6 月 30 日起陆续开放 7 大组件
光看数字,505B 这个总参数量在 2026 年的当下并不算特别炸裂——DeepSeek、Qwen、Kimi 这一年都已经把 MoE 规模卷到了万亿级别。但仔细看激活量:505B 总参只激活 18B,稀疏度大约 3.6%。这是个相当激进的稀疏比,比去年 DeepSeek-V3 的 671B/37B 稀疏比(5.5%)还要稀。
这种设计取向跟华为自家算力供给紧张是直接相关的。激活量越小,单 token 的计算开销越低,单卡吞吐就越高。余承东在台上说华为"更聚焦时延和吞吐率的提升",翻译过来就是:我没那么多卡跑稠密计算,所以我必须把每张卡的利用率榨到最后一滴。
Flash 版本的 92B/6B 配比同样体现这个逻辑。6B 激活量基本可以在单张昇腾 800I A2 上跑得很轻松,主打的是端侧到边缘的部署场景,配合鸿蒙的 Agent 链路。
二、昇腾深度绑定:单卡 2 倍吞吐怎么来的
华为这次反复强调"单卡吞吐率达到业界主流开源模型的 2 倍",这个 2 倍不是凭空来的。回看去年 7 月华为首次开源盘古 Pro MoE(72B/16B)时披露的细节,就能拼出这条技术路线:
1. MoGE 分组路由架构
传统 MoE 的 Top-K 路由有个老毛病——专家激活分布不均,某些设备成为瓶颈,其他设备闲着。华为的解法是 Mixture of Grouped Experts(MoGE):把 N 个专家硬性切成 M 组,每组绑定一个设备,路由时强制从每组激活 K/M 个。
这相当于用结构化约束换均衡性,牺牲了一点路由的灵活度,但换来的是设备间负载严格均衡。在昇腾这种以集群协同为核心的硬件上,这种取舍是非常划算的——大模型推理的总时延永远被最慢的那张卡卡脖子。
2. 张量按 256 对齐适配 DaVinci 架构
昇腾 NPU 的 DaVinci 架构是 16×16 的矩阵计算单元,所有张量按 256 对齐才能把计算单元喂满。这是个细节优化,但对于 MFU(算力利用率)的影响是数个百分点起跳的。
3. 自适应流水掩盖和分层混合并行
华为内部把这套优化打包叫 Adaptive Pipe Overlap Mechanism。配合 16 路 PP + 8 路 TP + 4 路 EP + 2 路 VPP + 48 路 DP 的并行策略,在 6000+ 张昇腾 NPU 的集群上把 MFU 拉到了 30%——这个数字相比优化前提升了 58.7%。
4. KVTuner 和 MulAttention 融合算子
KV cache 压缩 + 针对昇腾的融合 attention 算子,端到端 attention 加速 4.5 倍。这些都是从 Pangu Ultra MoE 那一代延续下来的工程积累。
说白了,2 倍吞吐这个数字背后是整套软硬一体的协同优化。这也是为什么余承东说"openPangu 2.0 更亲和昇腾算力"——离开昇腾,这套优化里相当一部分是兑现不了的。
三、鸿蒙适配:Agent 任务是真正的目标场景
参数和吞吐之外,发布会上另一个反复出现的关键词是 Agent。"更适配鸿蒙,Agent 任务更快更准更省"——这句话不是随便说的。
华为现在的产品矩阵是手机、平板、车机、IoT 全家桶,鸿蒙是底层 OS。这个生态下,端侧 Agent 是个很自然的落点:用户说一句话,系统得在设备间调度、调用 API、读取本地数据、执行操作。这种场景下,模型不是越大越好,而是要:
- 延迟低——用户对端侧响应的耐心阈值是几百毫秒
- 多工具调用准确——function calling 的准确率直接决定 Agent 能不能完成任务
- 资源占用可控——手机和车机不可能给你预留 80GB 显存
这就是为什么 Flash 版本只激活 6B 参数——它的目标场景就是端侧或近端推理。512K 的上下文也是为长链路 Agent 任务准备的:一次完整的多步操作可能要把整个会话历史、工具调用记录、文档片段全部塞进去。
这个产品定位跟 Qwen3、DeepSeek-V3 这类纯云端通用模型的思路是不一样的。华为的盘古从一开始就不是为了打榜而生,而是为了喂自家生态。
四、开源策略:放出预训练代码是个信号
这次 6 月 30 日起陆续开源的 7 大组件里,最值得关注的不是模型权重,而是:
- 预训练代码
- 后训练代码
- 训练算子
这三样东西放出来的意义远超模型本身。预训练代码意味着外部团队可以基于盘古架构在自己的数据上重新训一遍;后训练代码意味着 RLHF、DPO 这些对齐流程的工程实现是公开的;训练算子意味着昇腾平台上跑大模型训练的底层 kernel 不再是黑盒。
对比一下:DeepSeek 开源得很彻底,但训练代码从来不放完整版;Qwen 系列开源权重,但训练框架是阿里内部的 Megatron 魔改。华为这次把训练侧的东西也亮出来,更像是在拉拢昇腾生态的开发者——你想用昇腾做训练吗?给你完整的参考实现。
这背后的算盘很明显:昇腾要替代 CUDA,光有硬件不行,得有软件栈和模型基础设施。盘古开源出来,就是给昇腾生态加上一个标杆案例。
五、几个想吐的槽
讲完华为的好处,也得说几句不那么客气的。
第一,505B 这个规模在 2026 年中段已经不够看了。 国产开源阵营这一年迭代速度极快,万亿参数的模型早已不是稀罕物。盘古这次拿 505B 出来,从纸面规格上很难说能跟头部开源模型拉开差距。余承东自己也承认"算力非常有限",这个解释合情合理,但也说明华为在自家算力分配上确实给商用客户让了路。
第二,"亲和昇腾"是双刃剑。 单卡 2 倍吞吐听起来很美,但前提是你得跑在昇腾上。对于绝大多数中小开发者来说,他们手里的卡还是英伟达,盘古的这套优化迁移到 CUDA 平台上多大程度上还能保留?目前没有公开数据。
第三,benchmark 还没看到。 发布会上没有详细公布 MMLU、HumanEval、AIME 这些核心 benchmark 的得分。考虑到 openPangu 2.0 是 6 月 30 日才陆续开源,业界独立评测要到 7 月才能跟上。在那之前,"2 倍吞吐"这个数字之外,模型本身的智能水平怎么样还是个问号。
第四,余承东的喊话风格。 "在我余生的字典里,没有第二,只有第一"——这种表态在华为内部传统里不算稀奇,但放到大模型这种由数据、算力、算法、人才四要素共同决定的赛道上,光靠喊是喊不出来的。盘古要追上 GPT-5、Claude 4 这一档,路还非常长。
六、对开发者意味着什么
如果你是一个昇腾平台上的开发者,openPangu 2.0 几乎是必看的:完整的训练代码 + 优化好的算子 + 国内最大规模的开源 MoE 之一,这套组合在昇腾生态里没有对手。
如果你是一个普通的应用层开发者,盘古 2.0 的意义在于多了一个候选:512K 上下文 + 端侧友好的 Flash 版本,对做 Agent、做长文档处理的场景是有用的。需要注意的是,目前国内主流的 API 聚合平台对盘古的接入还在跟进,开源后第一时间应该会有平台上线。OpenAI Hub 这边按惯例会在模型权重公开后尽快上架兼容接口,届时和 GPT、Claude、Gemini、DeepSeek 一样可以用同一个 Key 调。
如果你是一个模型研究者,最值得读的是即将发布的技术报告——上一代 Pangu Ultra MoE 的报告里塞了大量 MoE 训练的工程细节,MoGE 路由、自适应流水掩盖、分组 AllToAll,这些东西对训练自己的 MoE 模型有直接参考价值。
七、最后
华为做大模型这件事,从 2021 年的盘古 1.0 算起,已经走了五年。中间起起伏伏,但 2025 年余承东接手之后,节奏明显变快了——开源、开放、追求工程效率,路线和之前那种偏研究、偏行业落地的姿态完全不同。
openPangu 2.0 不是一个会让人惊呼"颠覆"的发布。它的存在感更接近于一个信号:华为决定把盘古作为昇腾生态的旗舰开源项目认真做下去,并且愿意把训练栈完整开放出来。这件事对国产 AI 基础设施的长期影响,可能比 505B 这个数字本身要大得多。
至于"从中国第一走向世界第一"——这事得用版本号说话。等 openPangu 3.0、4.0 出来,再回头看 2026 年的这次发布是不是个真正的拐点。
参考来源
- 华为发布开源盘古 2.0 模型:最高 505B 参数,余承东坦言自己留的算力很有限 - IT之家 — HDC 2026 现场报道,包含 openPangu 2.0 完整参数和开源计划
- 发力大模型!华为余承东喊话自己的字典没有第二,只有第一 - IT之家 — 余承东主题演讲完整观点
- 华为开源 7180 亿参数大模型 - 知乎 — 盘古此前开源策略的背景资料


