Kimi K2.7 Code 开源:少想 30%,跑得更准

月之暗面今天开源 Kimi K2.7 Code,主攻长上下文编程的指令遵循和长程任务,思考 token 减少 30%,6 月 15 日还要上线 6 倍速版本。
Kimi K2.7 Code 开源:思考少了 30%,长程编程稳了
6 月 12 日,月之暗面把 Kimi K2.7 Code 甩了出来,模型权重直接挂上 Hugging Face,API 也在同一天开放。距离上一代 K2.6 在 4 月发布、把 SWE-Bench Pro 拉到对标 GPT-5.4 的位置,不过两个月。这次官方对版本的命名相当克制——不是 K3,只是 K2.7,而且明确标注「Code」后缀。意思也很明显:这一版不是全能选手的迭代,而是针对编程场景的专项进化。
如果你是用 Kimi Code Plan 写代码的开发者,今天起默认模型已经换成 K2.7 Code,不需要做任何操作。但如果你跑的是科研问答、长文写作这类非编程任务,官方反过来建议你切回 K2.6——这种「该用哪个就用哪个」的表态,比起厂商一贯的「新模型全面更强」要诚实得多。
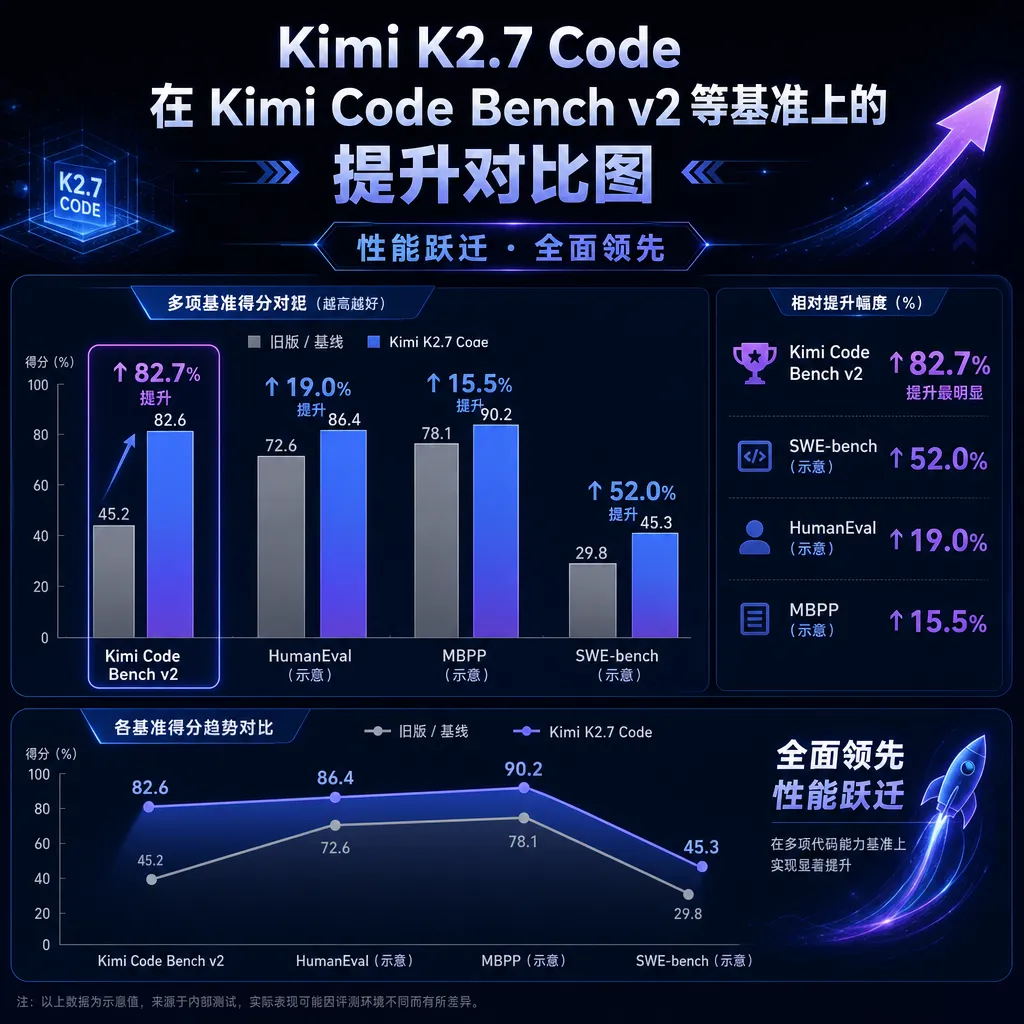
这次改了什么:少想 30%,多做对
先看官方放出的数字,这是和 K2.6 同基线的对比:
- Kimi Code Bench v2:+21.8%
- Program-Bench:+11%
- MLS Bench Lite:+31.5%
- Kimi Claw 24/7 Bench / MCP Atlas / MCP Mark Verified:Agent 自主化执行能力约 +10%
- 平均思考 token 消耗:-30%
最值得拎出来说的不是那个 31.5%,而是 token 消耗减少 30%。
做过 agentic coding 的人都知道,「过度思考」是带思考模式的模型在长程任务里最容易踩的坑。一个改 bug 的请求,模型会先用两千个 token 把代码库的可能结构猜一遍,再把每个文件名假设一遍,最后才动手——而真正的问题可能就在第一个文件的第十行。在按 token 计费的 API 场景下,这种「想得太多」直接换算成成本。在 Kimi Code 这种订阅制场景下,则换算成等待时间和上下文窗口的浪费。
K2.7 Code 把这个倾向砍掉了 30%。配合 21.8% 的 Kimi Code Bench v2 提升,这意味着模型不仅更准,而且更直接。对长程编程任务来说,这种「少废话」的进化比单纯刷分要值钱。
为什么是「Code」专项,而不是 K3
月之暗面这次的版本策略值得琢磨。K2.6 已经是面向全场景的旗舰,K2.7 没有直接覆盖前者,而是用 Code 后缀做了分叉。这背后是一个很现实的工程权衡:通用能力和编程专项能力之间的训练目标,越往后越难兼顾。
编程任务有几个特别的属性:
- 奖励信号清晰:能跑通就是对的,跑不通就是错的,RL 训练能拿到非常干净的反馈;
- 长程依赖强:一个真实的软件工程任务可能涉及几十个文件、上万行上下文,传统的「单轮问答」训练数据根本覆盖不到;
- 工具调用密集:读文件、跑测试、调 LSP,每一步都可能影响下一步的决策。
这三个属性决定了,做一个「编程更强」的模型,往往要在通用对话、知识问答这些场景上做出让步。月之暗面的选择是把分叉做出来——K2.6 保留全能基线,K2.7 Code 走专项极致。这种分叉策略在海外厂商身上其实早就出现过,但放在国内开源模型里还挺新鲜。
顺带说一句,K2.7 Code 是基于 K2.6 训练而来——这点 Hugging Face 上的模型卡写得很明确,「a coding-specialized agentic model built on top of Kimi K2.6」。所以它不是从头训练的新基座,而是在 K2.6 上做了大规模的长程任务后训练。这也解释了为什么提升集中在编程和 Agent 能力上,而其他通用能力官方没敢吹。
必须开思考模式,关了就报错
这是个挺硬核的设定:K2.7 Code 必须打开 Thinking 模式才能发挥最佳性能。
- 走 API 时,如果手动把思考关掉,会直接返回错误;
- 走 Kimi Code 时,关闭思考会自动回退到 K2.6。
这种「不允许你关思考」的产品设计,在国内大模型里不算常见。它的潜台词是:这个模型的训练目标和推理时的思考过程是深度耦合的,关掉思考拿到的不是「快一点的 K2.7」,而是一个能力不完整、行为不可预测的版本。月之暗面干脆从产品层面禁了这个选项。
对开发者来说,这意味着接入时要做一个判断:如果你的场景对延迟极度敏感、不能接受思考开销,那 K2.7 Code 可能不适合你——这种场景下要么用 K2.6,要么等下周一的高速版。
价格:标准版没涨,缓存命中悄悄涨了
看看价目表:
| 项目 | K2.6 | K2.7 Code | 变化 | |---|---|---|---| | 输入(1M token) | 6.5 元 | 6.5 元 | 持平 | | 输出(1M token) | 27 元 | 27 元 | 持平 | | 缓存命中输入 | 之前更低 | 1.3 元 | 略涨 |
论坛里有人吐槽这是「略微涨价」,主要就是命中缓存的输入价格调到了 1.3 元/M。对于做 agentic coding 工作流的人来说,缓存命中是大头——一次完整的编辑会话里,系统提示词、代码库索引、对话历史都会反复送进上下文,缓存命中率往往能到 70% 以上。这部分单价上调,长期跑下来的账单会比 K2.6 时代略高一点。
但考虑到 token 消耗减少 30%,实际的端到端成本不一定真的涨了。月之暗面这次有点在用「思考效率」对冲「缓存涨价」的意思。
周一见:6 倍速的高速版
这部分是 6 月 15 日才上线的,但官方今天就预告了:
- 速度:常规编程场景(输入长度取中位数)输出 ~180 Token/s,短上下文场景可达 260 Token/s
- 对比:约为普通版的 5-6 倍
- 价格:6 倍速度,2 倍价格
「6x 速度仅需 2x 价格」这个口径是月之暗面的一贯打法——之前 K2 系列就有 turbo 版本,路径基本一样。但 180-260 Token/s 这个区间,已经能追上海外一线推理优化平台的水平了。要知道,对于带思考模式的模型,输出速度是 agentic 编程体验的核心——你看着光标一行行往下吐代码,和「停顿三秒,然后唰一下蹦出五十行」是完全两种感受。
官方说 6 月底之前会逐步增加高速版的推理资源,言下之意——首批容量有限,要用的开发者早接早爽。
横向看:开源编程模型这条赛道
把镜头拉远一点。2026 年的开源编程模型矩阵已经相当拥挤:DeepSeek V4 Flash 用 1M 上下文和接近白菜价的输入打成本战,Qwen3.6-plus 走「输出更长更详尽」的路线,GLM-5 在中端段位卡位,MiniMax M2.5 主打综合性价比。Kimi K2 系列的位置一直比较微妙——262K 上下文,输入 1.09 美元/M(K2.5 数据),算是中高端区间。
K2.7 Code 这次的打法很清楚:不去和 DeepSeek 卷输入单价,也不去和 GLM 卷综合性能,就在长程 agentic coding 这个细分场景上压差异化。从基准提升的分布也能看出来——MLS Bench Lite +31.5% 是最大涨幅,这个基准本来就是评估真实软件工程任务的,对长程依赖和工具调用要求高。Agent 类基准 +10% 左右,也在情理之中。
说白了,Kimi 在赌一件事:开发者真正愿意为之付费的编程模型,不是单测能不能过的考试型选手,而是能在长上下文、多工具调用、多步规划里稳定交付的「软件工程师型」模型。这个判断对不对,要看接下来几个月 Kimi Code 的留存数据。
怎么用上 K2.7 Code
几条路:
- 直接调 API:在 Kimi API 开放平台(platform.kimi.com)指定
kimi-k2.7-code,注意要开 Thinking; - Kimi Code Plan:kimi.com/code,默认模型已经升级,不用改配置;
- 会员计划:Kimi 会员和企业版会员(含 Kimi Code Plan 权益)都能用;
- 本地部署:huggingface.co/moonshotai/Kimi-K2.7-Code 拉权重,自己跑。
对于希望一个 Key 调多模型(Kimi、GPT、Claude、Gemini、DeepSeek 同框对比)的开发者,OpenAI Hub 也在同步接入主流模型,做 agentic coding 评测时切换会方便些。
一点判断
K2.7 Code 不是那种「能上头条三天」的发布——没有炫酷的演示视频,没有跨模态突破,连命名都很保守。但放在 agentic coding 这条赛道的实战维度看,它做对了几件事:把思考 token 消耗砍下来、强制开启思考模式、长程任务专项打磨、价格基本稳住。这些是已经在用编程模型做生产力工作的开发者真正关心的指标。
剩下的悬念在周一。如果 6 倍速的高速版能稳定在 180-260 Token/s,并且推理资源跟得上,那么 K2.7 Code 在国内开源编程模型里会是一个相当有竞争力的选项。如果资源池供不上需求,那就还是和之前 K2 turbo 一样——开发者得抢着用。
两个月一次小版本迭代,月之暗面这次的节奏感和方向感都对了。
参考来源
- 月之暗面开源 Kimi K2.7 Code 编程模型,预告 6 倍速高速版周一见 - IT之家:发布会主要细节与基准数据汇总
- moonshotai/Kimi-K2.7-Code - Hugging Face:模型权重与官方模型卡,含训练背景说明
- Kimi K2.7 Code 编程模型已上线 Kimi Code、API 开放平台 - linux.do:官方上线公告与价格细节讨论
- Kimi K2.7 Code 正式发布,略微涨价 - linux.do:开发者社区对缓存价格变化的观察
- Moonshotai 开源 Kimi K2.7 Code - linux.do:开源消息及社区初步反馈


