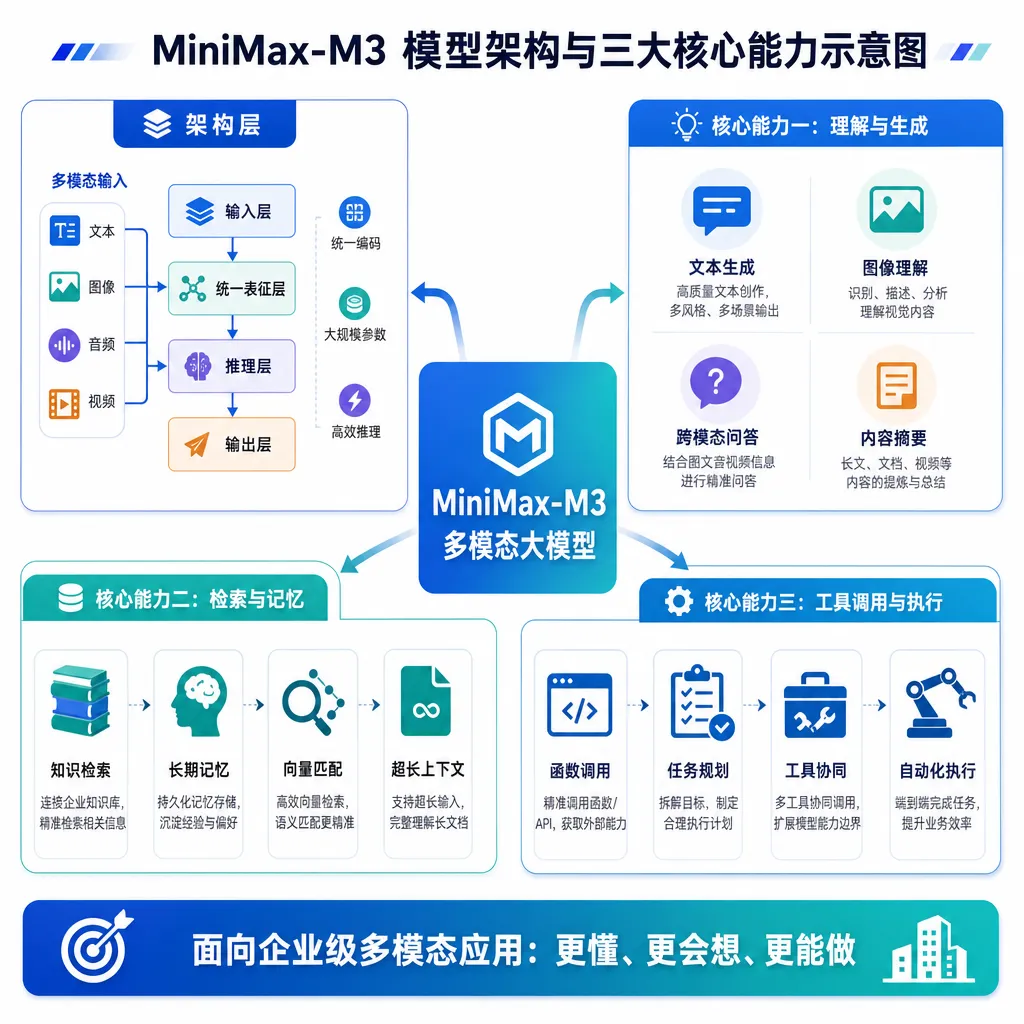
MiniMax-M3 开源:428B 参数撑起百万上下文与原生多模态

MiniMax 6 月 1 日发布并开源 M3 模型,428B 参数、自研稀疏注意力 MSA 架构、1M 上下文、原生多模态,是国内首个同时具备前沿 Coding、超长上下文和原生多模态三件套的开源模型。
MiniMax-M3 开源:428B 撑起百万上下文,国产模型的「三件套」终于齐了
6 月 1 日 MiniMax 把 M3 推上了官网,11 天后模型权重已经在 HuggingFace 和魔搭上挂好——MiniMaxAI/MiniMax-M3,428B 参数,没有藏着掖着的「闭源版」,开放权重就是满血。
这件事的信号比模型本身更值得说几句:到 2026 年中,国产开源阵营里第一次出现了一个同时把「前沿 Coding & Agentic」「1M 上下文」「原生多模态」三项能力打齐的旗舰。Qwen 系列在多模态上一路追,DeepSeek 把推理和成本卷到极致,但「三件套合一」一直没人做出来。这次 MiniMax 抢了这个身位。
428B 的取舍:不堆参数,堆架构
先把账算清楚。428B 这个数字放在 2026 年的语境下挺微妙——比上不足比下有余。比上,GPT-5.5、Gemini 3.1 Pro、Claude Opus 4.7 这些闭源 SOTA 早就传闻是 T 级 MoE,参数对比没意义;比下,Qwen3-Max、DeepSeek-V4 这些开源旗舰也是 500B~600B 这个段位,M3 反而是这一档里偏小的。
MiniMax 没在参数上硬刚,而是把筹码押在了自研的 MSA(MiniMax Sparse Attention) 架构上。这是 M3 的技术底座,也是它敢把上下文窗口直接拉到 1M 的原因。官方披露的数据是:在 100 万上下文规模下,M3 的单 token 计算量只有上一代(M2.7)的约 1/20。
这意味着什么?意味着 1M 上下文不是「能跑」而是「能用」。过去很多模型的长上下文都是营销数字——窗口标到 1M、2M,真喂进去 50 万 token 之后要么延迟爆炸、要么注意力涣散、要么算力账单让人破产。MSA 的稀疏化是从架构层把长上下文的边际成本压下来,这跟 DeepSeek 的 NSA、Kimi 的 MoBA 是同一个思路,只是各家路径不同。
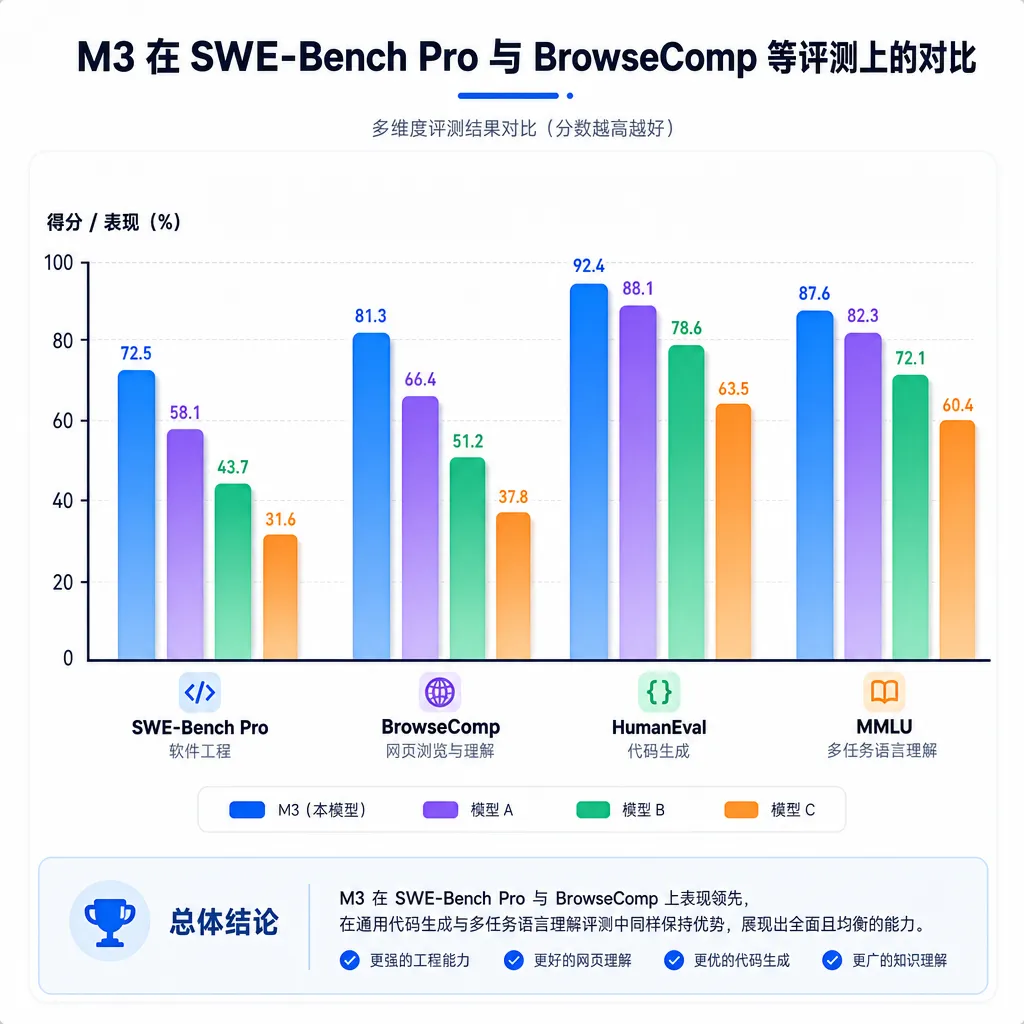
跑分:Coding 和 Agent 是真打过去了
来看几个关键的成绩单:
- SWE-Bench Pro:M3 超过 GPT-5.5、Gemini 3.1 Pro,接近 Opus 4.7
- SVG-Bench:M3 超过 Opus 4.7
- BrowseComp:M3 拿到 83.5 分,Opus 4.7 是 79.3
- OmniDocBench(多模态文档理解):M3 超过 Gemini 3.1 Pro
- Claw-Eval(端到端自主 Agent):M3 最高分
- PostTrainBench:M3 拿 37.1,排名第三,落后于 Opus 4.7(42.4)和 GPT-5.5(39.3)
这套数字里最有含金量的是 SWE-Bench Pro 和 BrowseComp。前者是真实软件工程任务,能在这上面把 GPT-5.5 和 Gemini 3.1 Pro 压住,已经是开源模型这两年没怎么见过的成绩;后者考的是 Agent 的自主浏览和信息检索,83.5 这个分数贴着闭源天花板。
PostTrainBench 那个 37.1 反而更有说服力——这个 benchmark 的玩法是:给 M3 四个只完成预训练的 Base 模型,要求它在 12 小时内自主完成数据合成、训练、评测、迭代全流程。全程无人干预,M3 自己当「炼丹师」。能排到第三,说明它的长程任务规划、工具调用、错误恢复这套东西是成系统的,不是榜单刷出来的。
那个 12 小时复现 ICLR 论文的 demo,值得说道说道
MiniMax 官方放出的最具象的 case 是这个:丢给 M3 一篇 ICLR 2025 杰出论文《Learning Dynamics of LLM Finetuning》,让它独立复现。
M3 连续跑了将近 12 小时,自主产出 18 次 commit、23 张实验图表,跑通了核心实验。
拆解这个任务它需要什么:
- 多模态:论文里的公式、流程图、实验图表得能看懂,这是原生多模态在出力
- 长上下文:论文 + 代码仓库 + 实验日志要一次性装进窗口,1M 上下文是基础设施
- Coding + Agent:12 小时的长线程执行,期间要不断写代码、跑实验、读错误、调参数、提交 commit
这三件事必须同时具备才能完成任务,缺任何一项都会断链。这也是 MiniMax 反复强调「三件套合一」的意义——单项能力堆得再高,缺一环 Agent 就跑不下去。
多模态:从第 0 步就开始混合训练
技术报告里有一个细节值得关注:M3 是从 Step 0 开始多模态混合训练的,不是先训一个语言模型再贴视觉模块。
这跟 GPT-4o、Gemini 那套原生多模态思路一致,但开源阵营里走这条路的不多——大部分开源多模态模型还是「LLM + Vision Encoder」缝合方案。原生路线的好处是文本和视觉的语义空间高度对齐,做 Computer Use、视频理解这种任务时不会出现「看图说话能力强,但理解图和文本的关系就拉胯」的割裂感。
代价是数据管线得重写。MiniMax 在报告里专门提了 Interleaved data(交错数据)——文本和图像在序列里自然交替排列的数据,对模型性能的提升比一般认为的更关键。为了能消化这种数据,他们把训练数据 token 规模拉到了 100 万亿(100T) 这个量级。
100T 是什么概念?参考 Llama 3 训练用了约 15T token,Llama 4 据传到了 30T 量级。100T 已经是把互联网上能爬的、能合成的、能授权的多模态数据基本都吃进去了。
一些实在话:它适合谁,不适合谁
社区里有个评价我觉得很到位:「跟主流 T 级的模型没法比,但 428B 能看到这个效果已经非常可观。拿小模型去和巨量参数模型比是不理智的,面向场景不一样。」
我的判断也类似:
M3 适合的场景
- 长文档 / 长代码仓库分析:1M 上下文 + 低计算成本,处理整个仓库或者几百页 PDF 不用做花式 RAG
- 自动化 Agent / Computer Use:BrowseComp 和 Claw-Eval 的分数说明它在真实环境里稳得住
- 企业私有化部署:开源 + 可微调 + 支持私有集群,金融、法务、政企这些对数据合规敏感的场景,是它的主战场
- 多模态文档处理:OmniDocBench 超过 Gemini 3.1 Pro,处理票据、报表、研报这类带图表的复杂文档是强项
M3 不一定打得过的地方
- 纯对话 / 创意写作:这块闭源旗舰的优势还在
- 极端复杂的推理 / 数学竞赛:PostTrainBench 落后 Opus 4.7 和 GPT-5.5 五六分,差距客观存在
- 追求极致响应速度的高并发场景:428B 的部署成本不算友好,比起 30B、70B 这种轻量级模型有数量级差异
部署门槛和生态支持
428B 的权重直接放出来,部署门槛是真实存在的。粗略估算,FP8 推理大概需要 8 张 H100/H200,BF16 则要翻倍。社区肯定会很快出 GGUF、AWQ、MLX 之类的量化版本,但在那之前,能完整跑起来的还是企业和研究机构。
MiniMax 自己也提供了 M3 和 M3-highspeed 两个版本的 API,结果完全一致,后者速度更快,全面支持自动 Cache。对开发者来说,如果不想自己折腾部署,直接调 API 或者通过 OpenAI Hub 这类聚合平台(一个 Key 调 GPT/Claude/Gemini/DeepSeek/MiniMax 一票模型,兼容 OpenAI 格式)拿到 M3 的访问能力会方便很多——尤其是想做横向对比评测的场景。
配套的 MiniMax Code 也同步更新了,这是专门为 M3 设计、跟 M3 一起训练的 Agent 产品,可以把大型任务拆解成多阶段、可并发、可动态调整的 Workflow,由 Agent 集群协作推进。这个思路跟 Claude Code、Cursor Agent 那套是对标的,但更强调「集群协作」。
对开源生态意味着什么
2026 年的开源大模型格局,跟 2024 年比已经完全是另一个画风了。两年前大家还在比谁的对话更顺、谁的中文更好;现在比的是 Coding、Agent、长上下文、多模态——也就是「能不能真的干活」。
这次 M3 开源,让国产开源阵营在「Coding + Agent + 长上下文 + 多模态」这个交集上第一次有了能打的代表。它不会取代 Qwen 或 DeepSeek 在各自擅长领域的地位,但它把开源旗舰的能力上限又往前推了一格。
更值得关注的是 MiniMax 这次的姿态:旗舰模型直接开权重,没有保留所谓「Pro 版只走 API」的常规套路。在闭源厂商越来越「API only」的 2026 年,能做到这一点的玩家不多了。
参考来源
- MiniMaxAI/MiniMax-M3 · Hugging Face:M3 模型权重、技术说明与使用文档
- MiniMax-M3 已经开源,参数量不到 500B - linux.do:社区第一时间讨论与上手反馈
- [前沿快讯]MinimaxM3 开源,满血模型只有 428B - linux.do:开发者对 M3 能力与适用场景的讨论
- 国内首个 Frontier 三件套开源大模型:MiniMax M3 完整技术拆解 - 知乎:M3 架构、训练与评测的深度技术解读


