AI2 把内部评测台搬上 Hugging Face:olmo-eval 想接管模型开发闭环

AI2 联合 Hugging Face 发布 olmo-eval,把原本服务于 OLMo 训练的内部评测流水线开放出来,主打"开发循环里的评测工作台",对标 lm-eval-harness 但更强调可复现与全流程追溯。
Hugging Face 博客今天挂出 AI2 团队的新作 olmo-eval,定位是"模型开发闭环里的评测工作台"。这东西不是又一个跑分榜,也不是 leaderboard 提交工具,而是 AI2 自己训练 OLMo 系列时用的那套内部评测流水线——这次他们把它收拾干净,连同配置、数据、指标计算一整套搬上 Hugging Face,开源给所有人用。
对做基础模型训练的团队来说,这是个值得认真看一眼的工具。原因后面再说,先讲清楚它是什么。
一句话定位:评测不是终点,是训练的反馈环
过去两年开源圈最常用的评测框架是 EleutherAI 的 lm-evaluation-harness,几乎成了事实标准。但凡是真正训过几次模型的人都知道,harness 解决的是"我有一个 checkpoint,跑个分给我看"的问题。它干净、通用、社区维护得不错,但它不关心你这个 checkpoint 从哪儿来、跟上一个 checkpoint 差在哪儿、明天再训一版要怎么追溯。
olmo-eval 想解决的恰恰是后面这些。AI2 把它叫做 evaluation workbench for the model development loop——开发循环里的评测工作台。关键词是"循环"。
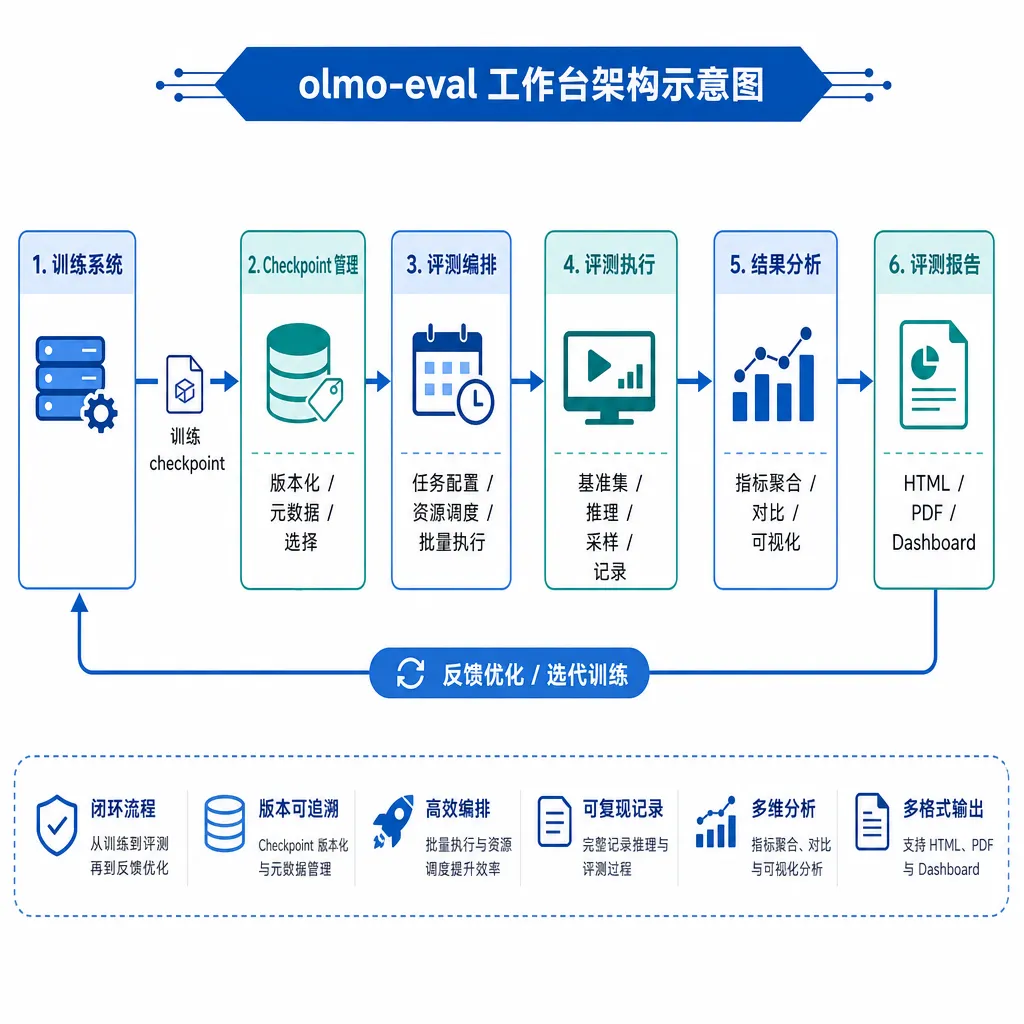
这个定位听起来抽象,但落到工程层面就很具体:
- 同一份配置,可以在训练过程中对一系列 checkpoint 滚动评测,自动跳过已经算过的部分
- 一个模型在多个任务集上的结果可以聚合成表,方便横向对比训练策略的差异
- 评测的中间产物(模型输出、prompt 模板、tokenization 细节)全部留痕,不是只给你一个最终分数
- 配置用 jsonnet 写,模型集合 × 任务集合 × 指标集合三个维度可以自由组合
说白了,AI2 是把自己训 OLMo 2、OLMo 3 时实际在用的内部工具链清理成了开源版本。这一点很重要——前段时间 AI2 发的 OLMo 3 把整个训练流程开放到了"完全开放"级别,包括每个阶段的 checkpoint、数据、依赖项。要把这种程度的开放落地,必须有一套配套的评测工具能把所有 checkpoint 的所有指标都追溯清楚。olmo-eval 就是那套工具。
跟 lm-eval-harness 比,差在哪?
这是开发者最关心的问题。讲点实在的。
任务覆盖:harness 胜在生态,社区贡献了几百个任务,你想跑什么基本都能找到。olmo-eval 在任务广度上还比不上,但它在"训练过程中的核心评测集"上做得更精——AI2 长期在 PALOMA(perplexity 评测套件)、MMLU 变体、数学推理等场景里调过姿势。
复现性:这是 olmo-eval 主打的差异化。它用 tango 做工作流引擎,每个步骤的输入输出都缓存。换句话说,你今天跑过的评测,明天换一个新模型加进来,旧模型不会重跑,只算增量。这个特性对长期训练项目几乎是刚需。harness 不是不能做,但需要自己搭一层缓存。
配置语言:jsonnet。这点见仁见智。喜欢的人觉得它比 YAML 表达力强、比 Python 配置干净,模型矩阵和任务矩阵叉乘特别顺手;不喜欢的人会觉得多学一门 DSL 是负担。
与训练框架的耦合:olmo-eval 跟 OLMo 训练代码原生兼容,可以直接读训练中间产物。如果你的训练栈和 AI2 那套差异很大,集成成本会比 harness 高一些。
我的判断:短期内 olmo-eval 不会替代 harness 成为通用基线工具,但它会成为"想认真做基础模型训练"的团队的标配补充。两个工具解决的是不同层级的问题——harness 是"评测 SDK",olmo-eval 是"评测平台"。
一个典型用法长什么样
仓库给的入门命令很简单:
tango --settings tango.yml run configs/example_config.jsonnet \
--workspace my-eval-workspace
这条命令做的事情是:读配置 → 拉模型 → 跑指定任务 → 算指标 → 把所有中间结果写进 my-eval-workspace 这个 tango 工作区。下次再跑:
tango --settings tango.yml run configs/eval_table.jsonnet \
--workspace my-eval-workspace
如果配置里加了新的模型或新的任务集,只算新增部分;旧的直接复用缓存。一个跑过 OLMo 全周期评测的人会立刻明白这有多省事——单次完整评测动辄几十个 checkpoint × 十几个任务集,重算一次的成本极高。
配置层面,jsonnet 的写法允许你这样组织:
{
models: ['olmo-2-7b-step10000', 'olmo-2-7b-step20000', 'qwen3-7b'],
task_sets: ['mmlu_core', 'gsm8k', 'paloma_subset'],
metrics: ['acc', 'perplexity', 'bits_per_byte'],
}
这种 m × t × k 的笛卡尔积形式,正是训练过程评测最自然的表达方式。如果你之前自己写过类似的 sweep 脚本,应该会有亲切感。
为什么这个时间点放出来
时机有点意思。AI2 去年 11 月发了 OLMo 3,主打"完全开放"——不光放权重,把预训练、中期训练、长上下文扩展的每个阶段的数据、代码、checkpoint 全部公开。OLMo 3.1 Think 32B 在数学、推理、编码上达到了最强完全开放思维模型的水平,训练 token 只用了同类六分之一。
这种程度的开放,要求评测端也得彻底开放。如果你只放模型、不放评测工具,研究社区就没法复现你"每个 checkpoint 的真实能力曲线"。olmo-eval 这次在 Hugging Face 博客上正式介绍,等于把这条"完全开放"的最后一环补上——从训练数据到模型权重到评测流水线,全部可追溯、可复现。
顺便提一句,AI2 把老的 OLMo-Eval 仓库(现在叫 OLMo-Eval-Legacy)在今年 1 月归档了。也就是说,olmo-eval 是经过一轮重构的新一代,不是简单的换皮。从配置组织、工作流引擎、与 Hugging Face Hub 的集成程度看,工程化水平比 legacy 版本明显上了一个台阶。
谁应该用,谁不必碰
直接说结论:
适合用的人:
- 在训练或微调自己的基础模型,需要对一系列 checkpoint 做系统评测
- 在做数据消融实验,需要把"换数据 → 训模型 → 评测"做成一个可重复的 pipeline
- 在写论文,需要评测结果可以被审稿人和读者一键复现
- 团队里有 MLOps 角色,愿意花一点学习成本换长期效率
没必要碰的人:
- 只是想跑个 MMLU 看看自己微调的模型水平如何——直接用 harness
- 在做 prompt engineering 或者下游应用评估——这个工具的关注点不在这里
- 临时性、一次性的评测需求——杀鸡用牛刀
一点延伸:评测工具链正在分层
过去大家把"评测"当成一件事。现在越来越明显,评测在分层:
- 底层执行器:lm-eval-harness、lighteval 这类,关注的是"在某个模型上正确跑出某个任务的指标"
- 训练循环评测:olmo-eval 这类,关注"在训练过程中持续、增量、可追溯地产出评测结果"
- 榜单与对比:Open LLM Leaderboard、各种私有评测赛道(澳鹏最近也跟 Hugging Face 合作搞了语音识别私有赛道),关注的是"在统一条件下横向比较模型"
- 下游任务评估:偏应用层的 eval,关注真实业务表现
四层各有侧重,工具也会越来越专门化。olmo-eval 占据的是第二层,这一层之前最缺成熟的开源方案,AI2 这次算是把自家的内部工具贡献出来了。
对国内开发者来说,如果你在做模型训练,建议至少花一个下午跑通 olmo-eval 的 example——不是说一定要用它替代现有工具,而是借鉴一下"评测如何工程化"的思路。AI2 这套东西的价值,一半在代码本身,一半在它体现的方法论。
至于跑评测过程中如果需要拉一些闭源模型做对照(比如想用 GPT-4o、Claude Sonnet 4.5 或 Gemini 当 judge model),可以走 OpenAI Hub 这种聚合 API,一个 Key 调通所有主流模型,省去配置一堆 SDK 的麻烦,国内直连也不用折腾网络。
参考来源
- olmo-eval: An evaluation workbench for the model development loop (Hugging Face Blog) — AI2 官方介绍 olmo-eval 的博客文章
- allenai/OLMo-Eval-Legacy (GitHub) — 已归档的上一代评测仓库,可以看到 tango 工作流的基本用法
- allenai/OLMo-2-1124-7B (Hugging Face) — OLMo 2 7B 模型卡,了解 AI2 模型家族的训练阶段划分
- allenai/OLMo-7B (Hugging Face) — 初代 OLMo 7B 模型,olmo-eval 最早就是为评测它而生
- 本周最值得关注的论文 TOP10 (Hugging Face Blog) — 包含 OLMo 3 的完整开放细节,理解 olmo-eval 推出背景的重要参考


