又一个企业级大模型网关要开源,赛道开始卷起来了

Linux.do 上有开发者预告将开源一套企业级大模型网关,架构和需求分析已经完成,功能日渐完善。在 One-API、New-API、MixAPI、瑛菲网关之后,这条赛道的玩家又多了一个。
又一个轮子,但这次的赛道值得卷
6 月 11 日,Linux.do 上一位开发者发了个预告帖:自己在做企业级大模型网关相关的工作,因为架构设计和需求分析都跑通了,索性把整套系统实现了出来,现在功能日渐完善,准备开源。帖子很短,没截图、没仓库地址、没 Roadmap,但底下还是聚了一波讨论。
这事儿单看不大,但放到 2026 年这个时间点上,信号挺明确——大模型网关这条赛道,到了正式分化的节点。
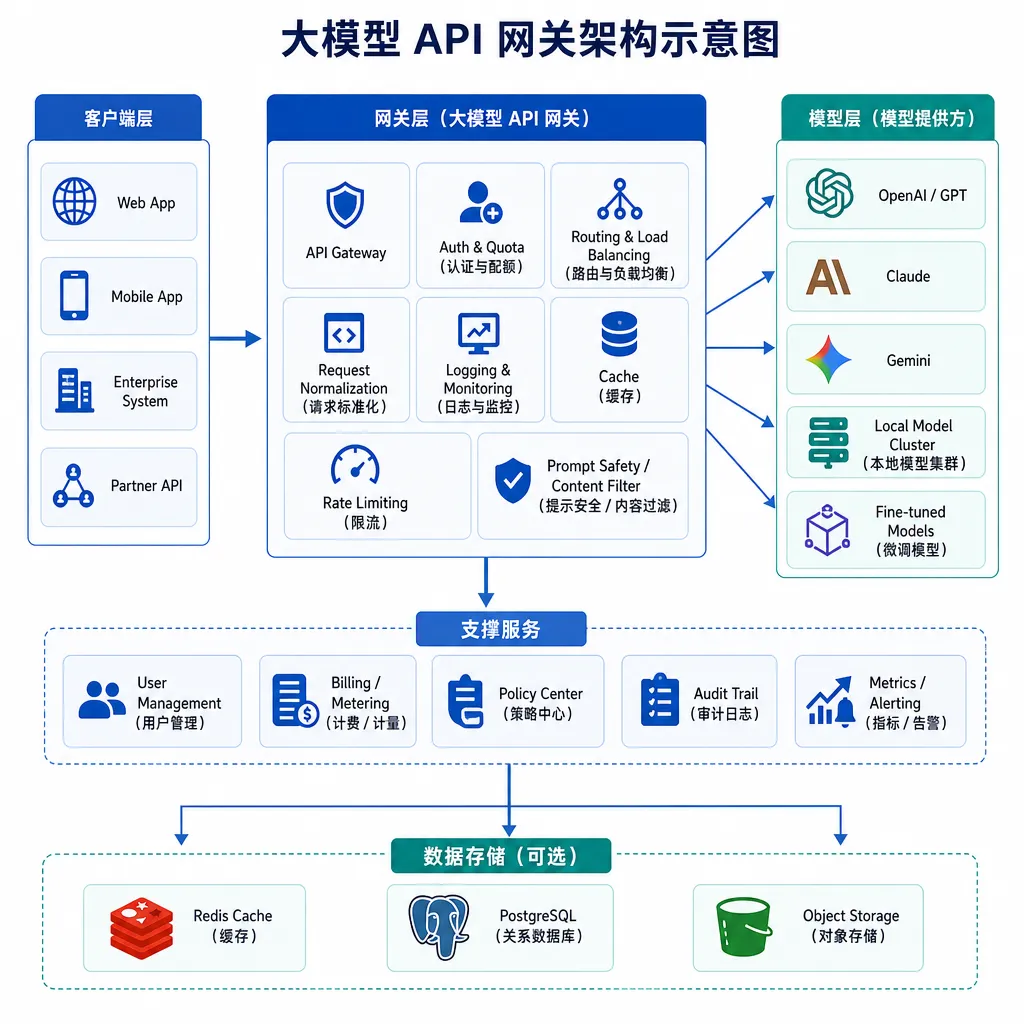
从 One-API 到现在,网关赛道发生了什么
回头看一下时间线。最早把这件事做成现象级开源项目的是 One-API,纯粹解决一个朴素问题:OpenAI、Claude、文心、通义各家 API 格式不一样,开发者懒得每家都对接一遍,于是搞一个中间层,全部转成 OpenAI 兼容格式。这个项目在 GitHub 上拿了 24K+ star,基本定义了第一代大模型网关的形态。
紧接着 New-API 在 One-API 基础上扩展,加了更精细的渠道管理、计费、二次分发;再往后 MixAPI 把企业内部管理场景独立出来,砍掉计费充值模块,专注做公司内网的 Key 管理与渠道分发;去年下半年瑛菲网络也把自家服务金融客户多年的流量治理能力剥离出来开源,主打"企业级 AI 网关标准"。
这条线索其实很清晰:网关的能力栈正在从"协议转换"往"流量治理"迁移。早期开发者要的是"一个 Key 调所有模型",现在企业要的是"SLA、限流、审计、灰度、故障切换"这套传统 API 网关的成熟治理范式,只不过对象从 RESTful 接口换成了 LLM 推理。
企业级网关,到底比"个人版"难在哪
说"我也要做企业级"很简单,但真正把它做出来要解决的问题不止一个量级。我自己接触过几家在生产环境跑大模型网关的公司,他们最头疼的从来不是协议适配,而是下面这几件事。
一、长连接和流式响应的稳定性
LLM 的 SSE 流式响应跟普通 HTTP 请求是两套世界。一次对话可能持续 30 秒到几分钟,期间网关要维持长连接、做心跳、处理上游断流、处理客户端断开、还要保证 token 计费准确。Nginx 那套传统反向代理直接拿来用是不够的,超时配置、buffer 策略、内存占用都得重写。
二、故障切换的延迟和会话状态
参考资料里提到某些平台号称"切换延迟 < 100ms,会话状态保持"。这句话听着像营销话术,但背后真不简单。当上游 Claude API 抽风,网关要在不打断 SSE 流的前提下把请求切到备用通道(比如另一个区域、另一家厂商的同档模型),同时保持上下文一致。这涉及到请求重放、token 计数对齐、多家 API 输出格式归一——做不好用户就直接看到一段乱码或者重复内容。
三、计费与配额的精度
大模型按 token 计费,但不同厂商的 tokenizer 不一样,prompt cache 折扣规则不一样,工具调用的计费规则也不一样。网关如果想做企业内部的二次分发,必须做到 token 级的准确计量,否则要么自己亏钱要么用户亏钱。这一块在 New-API 体系里其实做得已经不错,但要再往上做审计追溯、按部门分摊、配额预警,就要重新设计数据模型。
四、子账号、权限、审计这一整套企业治理
企业用大模型,最后一定会问:谁在调?调了多少?哪些 prompt 出过事?能不能按部门拉一份月报?能不能给某个团队限定只能用 GPT-4o-mini 不能用 Opus?这些需求 One-API 早期版本基本没覆盖,是后面被市场倒逼出来的。
这次开源的预告,能填哪块空白
回到 Linux.do 这个预告本身。作者目前没放出具体的能力清单,但从他自述"目前从事这方面工作,因为架构设计需求分析都差不多了"可以推测,这是一个先有企业实际场景、再做开源的路径,而不是先做开源项目再往企业方向适配。
这两种路径出来的东西差别很大。前者通常治理能力扎实但 UI、文档、社区生态薄弱;后者往往功能花哨但生产可用性存疑。最近一两年开源的几个新网关项目,瑛菲走的是前一条路(金融客户经验落地),MixAPI 走的是后一条路(先做 SaaS 再开放企业版)。
这位开发者如果能把架构图、压测数据、和现有 One-API/New-API 体系的差异点讲清楚,是有机会切到一块新地盘的。我个人比较期待看到的几个点:
- 是否原生支持 Anthropic 和 Gemini 协议(不是转换,是原生),这一点决定了 Claude Code、Gemini CLI 这类只认原生协议的客户端能不能直接走网关
- 故障切换的具体实现,是简单重试还是带会话状态的热切换
- 可观测性,Prometheus 指标、OpenTelemetry trace 这套是否完整
- 插件机制,能不能让企业自己加 prompt 注入、内容审核、PII 脱敏
这些都是现有开源方案做得不够细的地方。
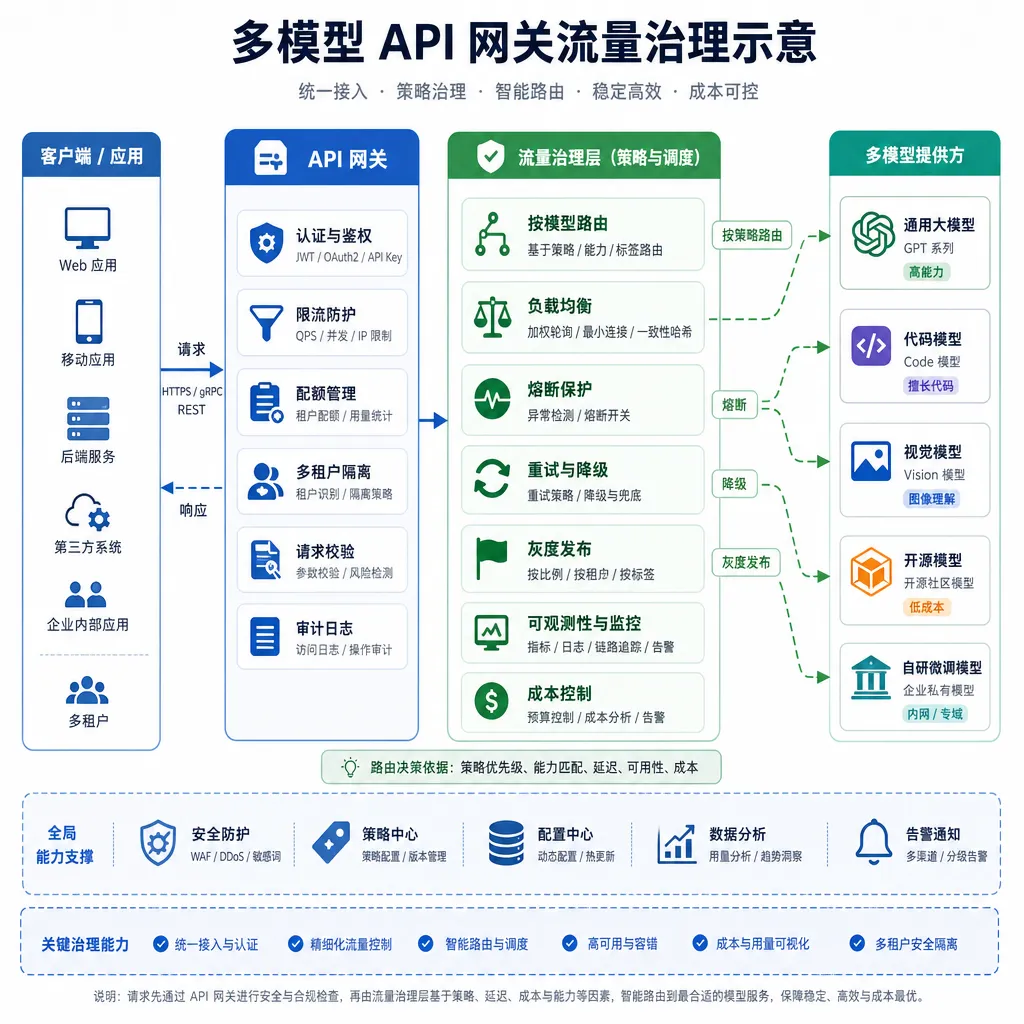
为什么 2026 年还有人愿意做这个
有人可能会问:One-API 都 24K star 了,赛道是不是已经定型了?
我的判断恰恰相反。大模型网关现在的状态,类似 2015 年前后的 API 网关市场——Kong、Tyk、APISIX 这些项目正是在那个时间点陆续起来,最后形成了多家共存的格局。原因是企业的需求颗粒度差异太大:有的要极致性能、有的要极致灵活、有的只要够稳,根本不存在"一个网关吃所有场景"。
大模型网关现在面临的分化更剧烈:
- 个人开发者要的是"一个 Key 调所有模型",OpenAI Hub 这种聚合平台就够了,国内直连、兼容 OpenAI 格式、不用自己折腾部署
- 中小团队要的是"自部署的 New-API",把成本控制和渠道管理掌握在自己手里
- 大型企业要的是"完整的治理栈",子账号、审计、SLA、灾备、和现有 IAM/SSO 系统打通
- 金融、政务等合规敏感行业要的是"私有化 + 内容审核 + 全链路审计",这是瑛菲这类项目瞄准的位置
这四档需求基本不会被一个项目同时满足,所以新玩家进场仍然有空间,关键看你能不能在某一档里做到比现有方案好用一截。
给开发者的几个判断
如果你现在正在选型大模型网关,我的几点建议:
- 先想清楚你是哪一档。不要拿企业级方案部署个人项目,运维成本远超你的预期;也不要拿个人项目方案上生产,等到流量真上来再迁移很痛苦
- 协议原生支持很重要。Anthropic 的 prompt cache、tool use beta、computer use 这些特性在 OpenAI 兼容层下经常缺失,如果你的应用重度依赖 Claude,原生协议支持是硬指标
- 观察社区活跃度。预告型项目我建议先收藏 watch,等第一个 release 出来、issue 有人回应、文档基本完整再考虑接入。开源项目最大的风险不是功能不够,是作者跑路
- 考虑混合方案。生产环境用自部署网关解决治理问题,开发测试和小流量场景直接用 OpenAI Hub 这类聚合服务(一个 Key 调 GPT、Claude、Gemini、DeepSeek,省去多家注册的麻烦),两者并不冲突
回到这次的开源预告。作者还没放仓库,我们也无从评价代码质量,但市场需要更多人进来卷这件事——网关这一层做得越好,上层应用的工程师就越能把精力放在业务而不是基础设施上。
等正式发布之后,我们再回来看具体的差异化能力。
参考来源
- 计划开源企业级大模型网关【预告】 - Linux.do:原始预告帖,作者自述项目背景和开源计划
- 瑛菲AI网关正式开源 - 知乎:瑛菲网络基于金融客户经验开源企业级 AI 网关的相关介绍
- MixAPI-PRO - GitHub:基于 One-API/New-API 扩展的企业级大模型网关项目,可作为对比参考


