MiniMax M3 开源当天,摩尔线程 S5000 完成 Day-0 适配

6月12日 MiniMax M3 开源,摩尔线程旗舰智算卡 MTT S5000 同日完成 Day-0 适配,覆盖 vLLM 与 SGLang 双框架,国产 GPU 跟卡前沿模型的节奏越来越紧。
国产 GPU 这次没掉队
6月12日,MiniMax 把新一代原生多模态旗舰模型 M3 扔到了开源社区。就在同一天,摩尔线程宣布旗舰级 AI 训推一体智算卡 MTT S5000 完成 Day-0 适配——开发者拉下 M3 权重,可以直接跑在国产卡上。
这不是摩尔线程第一次玩 Day-0。今年早些时候,从 DeepSeek-V4、MiniMax M2.5/M2.7,到 GLM-5.1,几乎每一款国产头部开源模型上线,摩尔线程都能在当天或次日完成适配并放出技术 Blog。一年前国产 GPU 还在追着模型跑、出问题先甩锅给硬件兼容性,现在已经能做到模型 release 当天可推理、几周内出性能优化版本。这种节奏的变化,比单纯的 TFLOPS 数字更说明问题。

先说 MiniMax M3 自己
要理解为什么 M3 的适配难度比上一代高,得先看它的几个关键变化。
M3 是 MiniMax 第一款 从 Step 0 就进行多模态混合训练 的旗舰模型——不是先训文本再贴个视觉编码器的那种缝合方案,而是从预训练第一步起,图像、视频、文本就在一个 token 流里一起喂。这意味着推理时算子的工作负载分布跟纯文本模型完全不一样:视觉 token 占比高、序列长度更长、KV Cache 的访问模式也更碎。
架构上 M3 继续用了 MiniMax 自家的 MSA(Mixed Sparse Attention,混合稀疏注意力)路线,把全局注意力和局部稀疏窗口混编,目的是把上下文窗口拉到百万 token 量级而不让显存爆炸。但 MSA 的代价是:算子结构跟标准 Transformer 不一样,主流推理框架里没有现成的 fused kernel,谁都得重新写一遍。
这也是为什么「Day-0 适配」在今天还有含金量。模型架构越往非标准走,谁能在第一时间把算子搞定,谁就能截住第一波 try-out 流量。
MTT S5000 这边做了什么
摩尔线程这次给出的硬件参数和优化路径,是按 M3 的痛点逐个对的:
- 算力侧:MTT S5000 单卡稠密 FP8 算力 1000 TFLOPS,硬件级原生 FP8 加速。M3 在推理时大量用 FP8,这点直接对上。
- 显存与带宽:80GB HBM、1.6TB/s 带宽。百万 token 上下文场景下,KV Cache 动辄几十 GB,带宽吃满是常态——这套配置基本是冲着「单卡跑长上下文」去的。
- 算子迁移:MUSA C++ 与 Triton-MUSA 抽象层。Triton-MUSA 这条路是关键,意味着开发者写一遍 Triton kernel,能在 MUSA 平台上直接跑,不用为每张卡重写 CUDA。M3 的 MSA 新算子之所以能在 Day-0 跑起来,靠的就是这层抽象。
再往上是框架层。这次摩尔线程同步拉起了 vLLM 和 SGLang 两套主流推理框架——选择是有讲究的。vLLM 在 batch serving、PagedAttention 上是工业部署的事实标准;SGLang 则在结构化输出、Agentic workflow、RadixAttention 缓存复用上更激进。M3 本身是奔着编程和智能体场景去的,SGLang 的支持几乎是必选项。
Coding 和 Agent,是 M3 也是 S5000 的主战场
MiniMax 这一代 M3 重点强化了两块:代码生成和智能体调用。这两个场景对推理基础设施的要求是反直觉的——
它们看上去 token 输出量不大,但 prefill 阶段的上下文极长(整个仓库、整个工具链文档塞进去),而且 多轮交互导致 KV Cache 复用率极高。一个 Agent 任务里,前几轮的 context 几乎不变,每次都重新算 prefill 是巨大浪费。
摩尔线程在适配 Blog 里提到,他们针对 M3 做了「原生算子定制」,在精度无损前提下提升吞吐、降低延迟。结合此前对 DeepSeek-V4 和 GLM-5.1 的适配经验,已经形成一套针对「长 prefill + 短 decode + 高缓存复用」场景的优化方法论。这个方向是对的——光堆算力打 MMLU 没用,真实的 Agent workload 是另一回事。
全精度覆盖:从研发到落地的一条龙
值得单独拎出来说的是 MTT S5000 的精度矩阵——FP8 到 FP64 全覆盖。
这个事在 AI 推理卡里其实不算常见。多数推理卡为了能效,会把 FP32/FP64 算力砍得很狠,专心做 FP16/INT8。但 MTT S5000 把 FP64 也留着,对应的是科学计算和 HPC 场景;FP32 留给训练 fine-tune;FP16/BF16 给标准推理;FP8 给最新的旗舰推理负载。
这背后是国产卡的现实选择:用户买一张卡,希望能从模型研发一直用到商业化落地,不愿意为不同精度买不同硬件。S5000 这套配置是「训推一体」的真实定义,不是 PPT 上的概念。
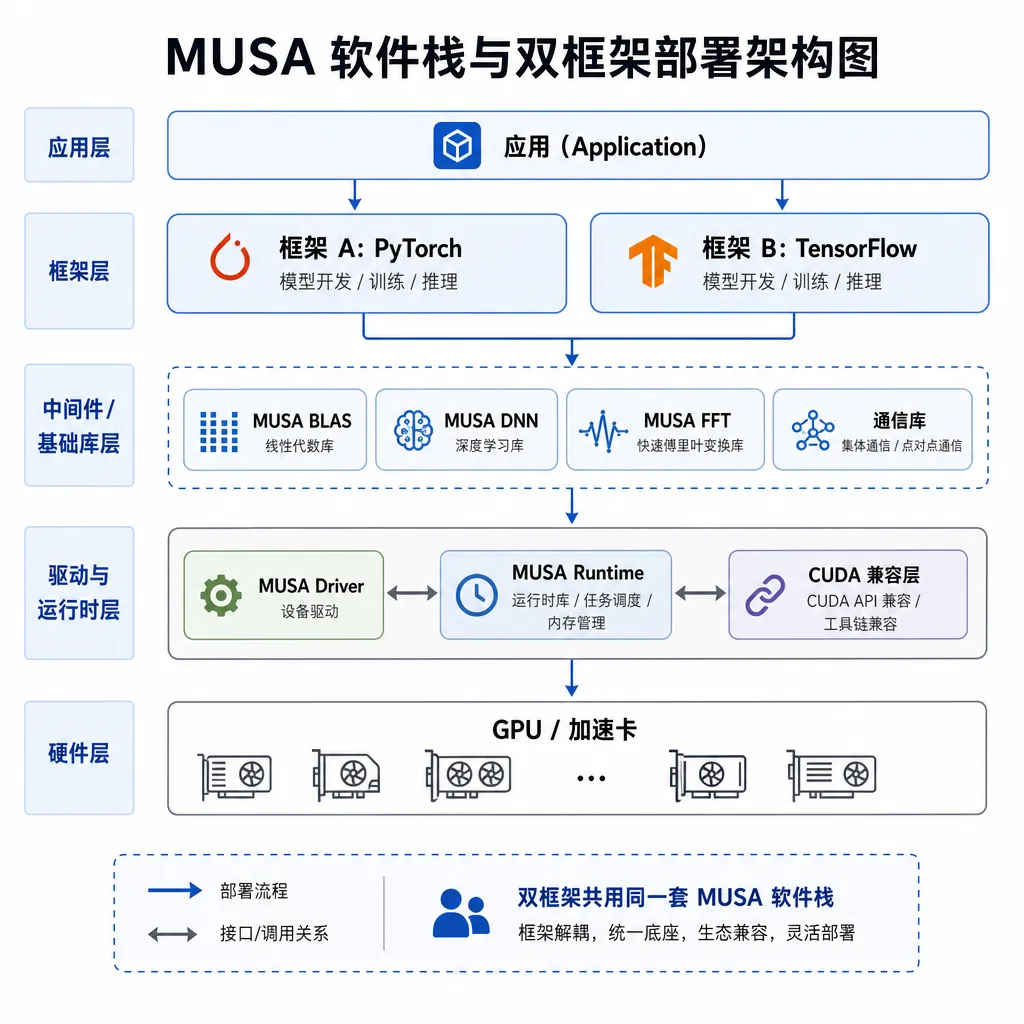
部署体验:MUSA + vLLM/SGLang
对开发者来说,最关心的是「我现在能不能直接用」。答案是:能。
基于 MUSA 软件栈,搭配 vLLM 或 SGLang,部署路径已经跑通。需要注意的几个点:
- MUSA SDK 版本:建议升级到最新稳定版,M3 的算子优化是跟着 SDK 一起放出来的,老版本跑得起来但性能差距明显。
- 框架选择:纯 chat/completion 场景上 vLLM 更省事;如果做 Agent、function calling、结构化输出,SGLang 的 RadixAttention 能省下大量重复 prefill。
- 长上下文调优:百万 token 场景下,KV Cache 量化、PagedAttention 的 block size、prefix caching 这几个开关要根据实际 workload 调,默认值不是最优。
摩尔线程说后续会持续放出算子级性能优化补丁——这事在国产 GPU 圈很重要,因为 Day-0 跑起来只是起点,后面几周的迭代速度才决定能不能真正进入生产。
一个更大的趋势
回到行业层面看,2026 年这半年发生的事情很值得琢磨:国产开源大模型的发布节奏越来越快,DeepSeek、MiniMax、智谱、阶跃几家几乎每个季度都有大版本;同时国产 GPU 的 Day-0 适配也成了「标配动作」——你发模型当天我就跑通,否则就是失职。
这种闭环的形成,意味着「国产模型只能在 H100 上跑」的时代基本结束了。不是说性能完全追平,但「能用、好用、能进生产」这三个门槛已经过了。对开发者来说,多一个选择就是多一份议价权。
顺带一提,OpenAI Hub 已经支持通过统一 Key 调用 MiniMax M3,兼容 OpenAI 格式,国内直连。如果你只是想先试试 M3 的效果再决定是不是自建推理,可以直接走 API;要做大规模部署,再考虑摩尔线程这套国产化方案。两条路并不冲突。
写在最后
MTT S5000 + M3 这件事,单看是一次普通的适配公告。但放到过去 12 个月的脉络里看,国产 AI 算力栈在模型适配速度、框架生态对接、精度覆盖这几个维度上,确实在快速逼近主流水准。
剩下的问题是性能——同 batch、同上下文长度下,S5000 跑 M3 的吞吐和延迟到底跟 H100/H200 差多少。这个数据摩尔线程暂时没公开,但按惯例后续 Blog 会放。等基准出来,再来看这次 Day-0 的成色到底有多硬。
参考来源
- IT之家:Day-0 支持,摩尔线程完成 MiniMax M3 大模型适配 — 包含 MTT S5000 硬件参数与适配技术细节的完整披露


