讯飞星火X2-VL发布:把多模态塞进具身智能的"AI大脑"

6月11日,科大讯飞在无锡发布星火多模态大模型X2-VL,基于MoE架构与原生多模态训练,高考模拟卷全学科准确率近95%,并衍生出新一代具身模型GEAR-VLA,瞄准物流拣选等机器人落地场景。
讯飞把多模态塞进了机器人的"脑子"
6月11日,无锡。2026长三角机器人及自动化展览会开幕日,科大讯飞总裁吴晓如在台上甩出新底牌——星火多模态大模型 X2-VL。这不是一次常规的 demo 秀,发布会本身的主题就叫"能力进阶 生态聚变",配套的还有具身智能产业链伙伴大会。换句话说,讯飞这次不是单纯发模型,是要拿模型去敲机器人产业链的门。
讲在前面:X2-VL 是讯飞"1+2+2"模型矩阵里的那个"1",即多模态底座。配套的两个垂类是具身智能大模型、超拟人数字人大模型,再加两个行业版本——物联网多模态和工业多模态。这套组合拳从架构图上看就很无锡——制造业、物联网、机器人,全是这座城市的产业储备。

技术拆解:MoE+原生多模态,把"快慢思考"塞进一个模型
先说架构。X2-VL 走的是 星火 MoE 路线,训练范式是原生多模态——这点要划重点。
所谓"原生多模态",对应的是早期那种"先训语言模型再贴个视觉编码器"的拼接派。原生派的做法是从预训练开始就把图、文、表、场景一起喂进去,模型从底层就习惯把像素和 token 当成同一种东西去消化。Gemini 当初打这张牌,GPT-4o 也是这个路子。讯飞这次明确摆出"原生多模态"四个字,至少在叙事层面是对齐了第一梯队的主流共识。
几个值得关注的工程细节:
- 轻量化视觉编码器:这是为了端侧和机器人侧的部署留路。具身智能场景对延迟极度敏感,视觉塔太重就别想跑在机器人本体上。
- 快慢思考统一模型:把 system 1 的直觉响应和 system 2 的链式推理放在同一套权重里调度。OpenAI 的 o 系列、Claude 3.7 的 extended thinking 都是这个思路,讯飞这次也明确把"快慢统一"作为产品卖点写出来。对开发者意味着不用再维护两套接口去分别处理"问答"和"推理"。
- MoE 稀疏激活:在大参数规模和推理成本之间找平衡。具体专家数、激活参数讯飞没公开,但路线方向是清晰的。
跑分:高考模拟卷近 95%
讯飞最爱秀的还是教育场景。X2-VL 拿 2026 年度全国各地高考模拟卷的多模态试题 做测试集,全学科平均答题准确率接近 95%。
这个数怎么看?多模态学科题的难点不在文字阅读,而在几何图、函数图像、化学结构式、地理示意图这种"图文耦合"题目——题干说的是一回事,图上画的是另一回事,要把两者对齐才能解。能把全学科推到 95% 附近,至少说明视觉推理这一块的工程化是真做扎实了。横向比,去年同期国内几家大厂的多模态模型在类似题目上普遍还在 80% 出头徘徊。
当然,高考模拟卷不是 MMMU 也不是 MathVista,这个分数没法直接拿去和海外模型比榜。但作为面向中国教育场景的指标,它的商业含金量比刷国际榜单更高——因为讯飞接下来要卖的就是 AI 黑板、智能批阅机这些落地产品。
教育和司法:能力先在熟悉的地方变现
讯飞没有藏数据,直接把无锡的落地情况摊开来讲:
教育:
- 近 1200 台 AI 黑板覆盖 75 所中小学
- 日均活跃率 87%
- 星火智能批阅机部署 128 台,覆盖 80 所中小学
司法:
- 手写体识别准确率 97.2%
- 复杂表格识别准确率 95%
- 民商事 60 天内结案率提升 18%
- 刑事办案效率提升 30%
- 智慧法庭已覆盖无锡两级法院,庭审时长缩短 30%~50%,人力效率提升 60%
司法这条线尤其值得注意。电子卷宗的难点从来不是 OCR——是版式。一份卷宗里有打印体、有手写笔录、有印章、有签名、有表格、有照片复印件,传统 OCR 拼接方案很容易在版面解析这一环崩掉。讯飞这次把"复杂版面解析"作为 X2-VL 的核心能力之一推出来,本质上是把多模态模型当作一个端到端的文档智能引擎,绕过了传统 pipeline。
真正的看点:GEAR-VLA 和具身智能
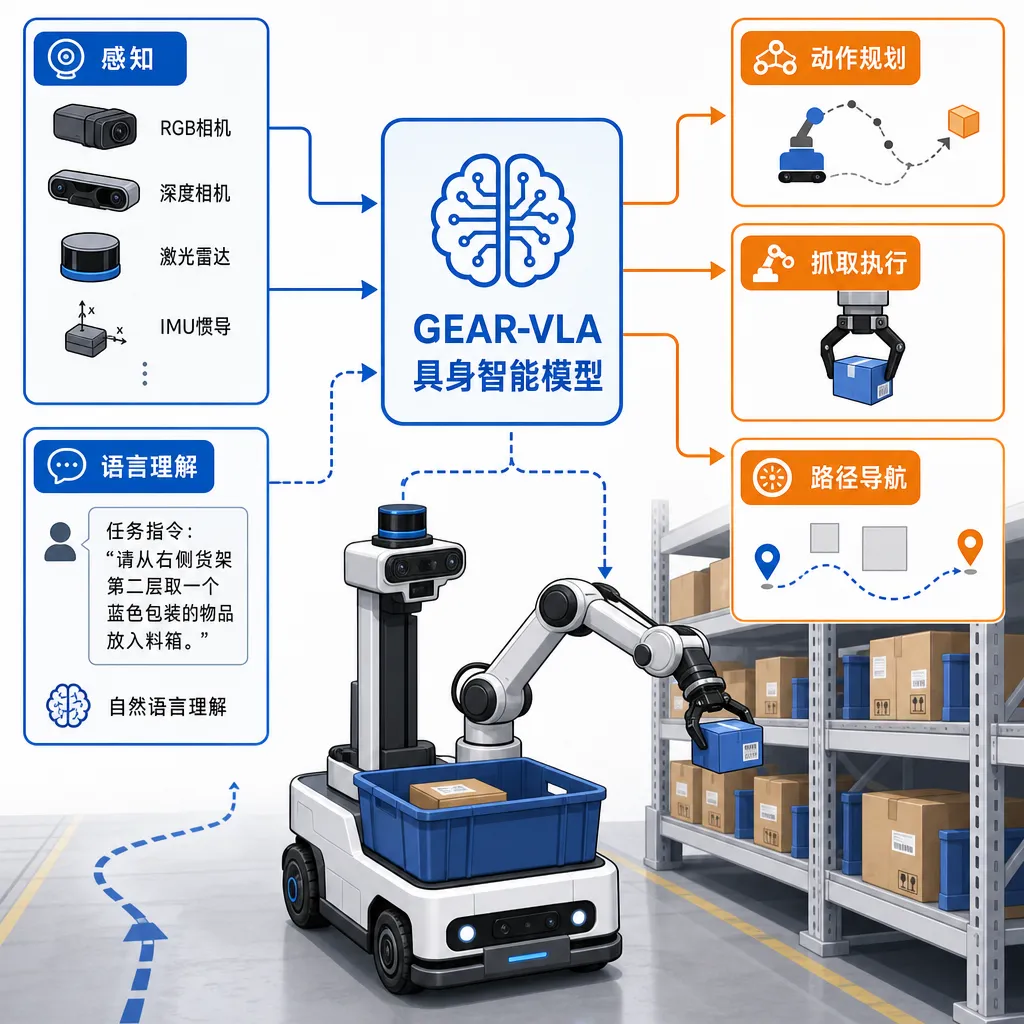
如果说前面都是热身,那 GEAR-VLA 才是这场发布会的真正主角。
VLA(Vision-Language-Action)这个范式 2023 年由 Google DeepMind 的 RT-2 带火,核心是把视觉、语言、动作放在同一个 token 空间里训练,让机器人能直接把"把可乐递给我"这种自然语言指令翻译成关节角度序列。
讯飞这次提出的 GEAR-VLA 是 X2-VL 之上的具身衍生模型,官方说法是"进一步提升空间任务精度与物体特征泛化能力,并在领域公开评测集合中效果领先"。两个关键词:
- 空间任务精度:抓取一个透明杯子、把零件插进有公差的孔位、避开桌面上的障碍——这类亚厘米级精度的任务一直是 VLA 模型的硬骨头。
- 物体特征泛化:训练时见过红色杯子,测试时给个绿色的能不能照样抓?训练时是塑料,测试时是金属呢?泛化崩了,机器人就只能在固定 SKU 下工作,做不成通用拣选。
讯飞的切入场景选得很现实——物流拣选。理由也直白:
- 物流仓库的 SKU 类目多、形态杂、订单 mix 高,传统视觉+规则方案做不完所有 case,正好是 VLA 范式的甜蜜区。
- 仓库是结构化环境,不像家庭服务那么开放,技术风险可控。
- 客户付费意愿强、ROI 算得清楚——一台机器人替几个分拣工,账本一目了然。
这个打法和 Figure、1X、银河通用走家庭/工业的路线不太一样,更像 Covariant、Mech-Mind 在仓储垂直深耕的逻辑。讯飞在公告里也直说要"打造行业级具身机器人,加速形成软硬一体化解决方案和标准产品"。软硬一体这四个字才是关键——纯卖模型挣不到大钱,能把模型、视觉传感器、机械臂打包成一个 SKU 卖给物流总包,才是商业模型。
"全国产算力" 这张牌
吴晓如在演讲里特意强调,讯飞星火是国内首个基于全国产算力平台训练的全栈自主可控大模型,X2-VL 是依托与无锡联合建设的太湖星跃平台训练的。
这句话在 2026 年的语境下分量很重。一方面,国产算力(华为昇腾系)的可用性在过去 18 个月里有了实质性的提升;另一方面,对于教育、司法、政务这些讯飞主战场的 G/B 端客户,"全国产"几乎是一个硬指标。这块标签讯飞已经反复打了三年,X2-VL 是它在多模态时代的延续。
生态侧的数字:开发者一年涨 26.4%
讯飞开放平台同时公布了一组数据:
- 无锡本地开发者团队从 2025 年 6 月的 4.8 万增长到 2026 年 6 月的 6.1 万+,增幅 26.4%
- 平台总开发者团队数 1124.1 万+
- 应用总数 414 万+
- 开放 AI 能力及解决方案 981 项
这套数字的意义在于:讯飞在做 ToB 大模型生意的同时,没有放弃 ToD(to developer)。开放平台一直是它和阿里通义、百度文心拉开身位的差异点之一——后两家更偏一站式云平台,讯飞更像"AI 能力超市",按 API 颗粒度卖。
一点判断
把 X2-VL 放到 2026 年中的国产多模态序列里看,它不是参数最大的,也不是榜单最炸的,但产业落地的路径是其中最清晰的之一:
- 教育、司法这种讯飞的传统强场景,X2-VL 是顺势升级,没有悬念;
- 具身智能这条新战线,靠 GEAR-VLA + 物流拣选切入,赛道选择务实;
- "1+2+2" 模型矩阵和无锡的产业资源绑定,等于讯飞自己给自己造了个客户群。
短期风险也明摆着:
- 多模态底座的国际竞争压力。GPT-5、Gemini 3、Claude 4.5 都在卷长视频理解和实时多模态交互,X2-VL 目前公开的卖点更多在静态图文,长视频和音频的实时融合还没看到太多细节。
- VLA 模型的真实表现。GEAR-VLA "公开评测集合领先"是个比较模糊的说法,具体在哪个 benchmark、对比谁,发布会上没披露。
- 物流拣选的红海。这个赛道里已经站了不少深耕多年的玩家,讯飞作为后来者,硬件供应链和现场交付能力还要打个问号。
但无论怎么挑刺,一个能把"多模态底座→垂类衍生→行业产品→落地场景"这一整条链路打通并跑出现金流的 AI 公司,在 2026 年的国内市场依然是稀有物种。X2-VL 不一定能在跑分上让人眼前一亮,但它大概率是讯飞 2026 下半年财报里的核心叙事。
关于模型可用性:星火 X2-VL 目前主要通过讯飞开放平台对外提供。OpenAI Hub 已在评估接入计划,后续如果上架,开发者可以用同一个 Key 在 GPT、Claude、Gemini、DeepSeek 之外直接调用星火系列,省掉切换 SDK 的麻烦。具体进展我们会在后续快讯里跟进。
参考来源
- 讯飞开放平台 2025 年生态总结 - 知乎专栏:讯飞开放平台在 2025 年面向机器人厂商提供"超脑平台"软硬一体方案的回顾,可作为本次 GEAR-VLA 商业化路径的背景参考。


