1500美元训出1B模型,HRM-Text凭什么让Bengio团队下注?

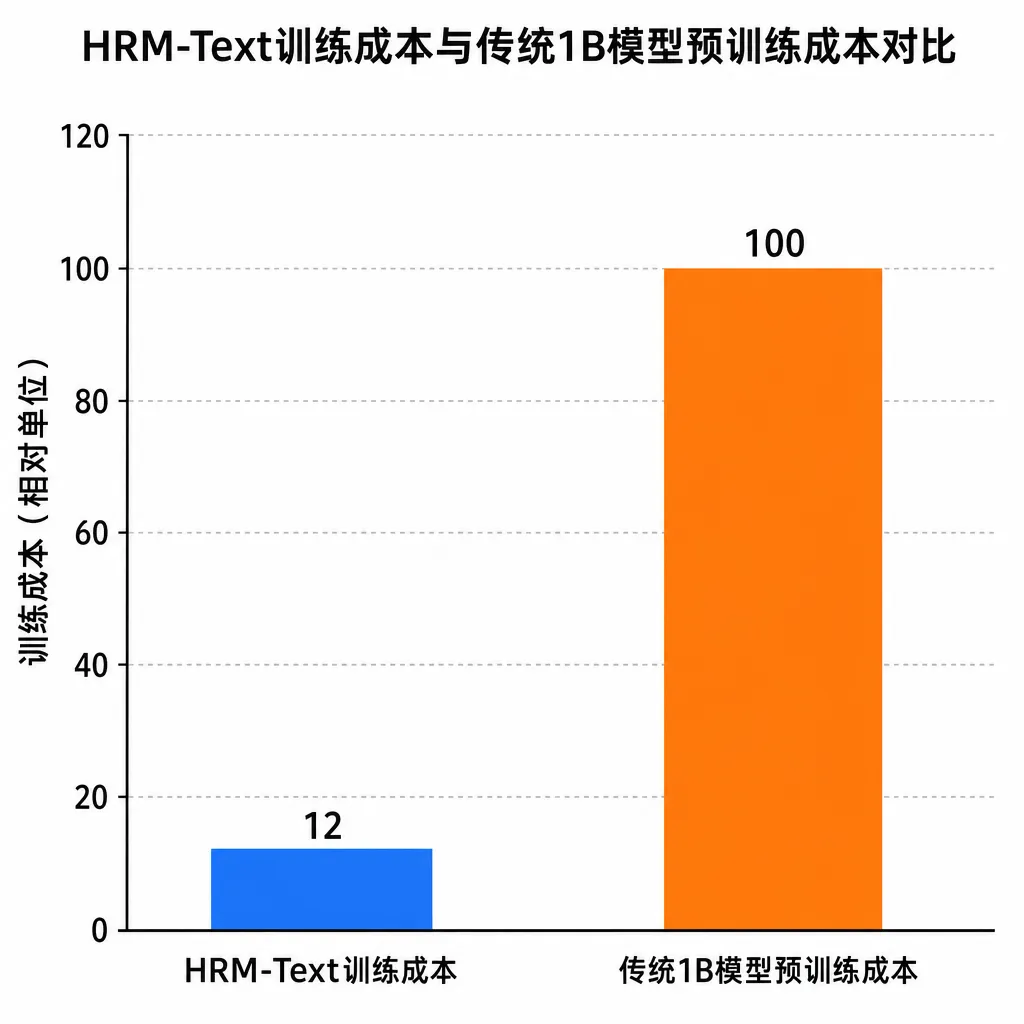
一个10亿参数的基础模型,16块GPU跑1.9天,总成本约1500美元——HRM-Text这套训练方案戳中了行业最敏感的神经:预训练真的非得烧那么多钱吗?HuggingFace CEO亲自转推,Bengio团队跟进研究。
周末AI圈被一份训练账单刷屏:一个10亿参数的基础语言模型,从零预训练,16块GPU跑了1.9天,总计算成本估算约1500美元。模型名字叫 HRM-Text,HuggingFace CEO Clément Delangue 直接在 X 上转推力荐,Yoshua Bengio 团队也表态在跟进相关方向的研究。
1500美元是什么概念?同等规模的传统预训练,按主流云GPU报价拉满,怎么也得五位数起步;对标 Meta 当年 LLaMA-7B 的训练成本,更是几个数量级的差距。所以问题不是"HRM-Text强不强",而是"它凭什么能这么便宜",以及——这条路能不能走通。
先把事情说清楚:HRM 到底是什么
HRM 全称 Hierarchical Reasoning Model,分层推理模型。这个架构本身不是今天才出现的,早先用于推理类小模型的实验里就有原型。HRM-Text 是把这套分层思路搬到了"基础语言模型预训练"这个最烧钱的环节,并且证明了它能跑通。
核心思路一句话概括:别再让模型把所有token都摊平了一视同仁地学,让它在不同时间尺度上做不同粒度的处理。
具体来说,HRM 把网络分成高低两层循环:
- 低层(fast module):高频更新,处理局部、细粒度的语言模式,类似传统Transformer做的事;
- 高层(slow module):低频更新,每隔若干步才前进一格,负责整合长距离上下文、抽象语义和"全局规划"。
两层之间通过门控机制做信息交换。结果是——同样的算力预算下,模型把更多有效计算花在了"该花的地方",而不是每个token都拉满。这跟人脑的双系统(系统1/系统2)有点像,但更接近经典认知科学里的"层次时间尺度"假设。
训练数据上,HRM-Text 团队没用全网爬下来的几T token,而是做了相当激进的数据筛选和课程学习(curriculum learning):先喂结构清晰、信息密度高的文本(教材、维基、代码、合成推理链),再逐步引入噪声更大的网页数据。这套"少而精"的策略,配合架构本身的高效,是把成本压到1500美元的关键。
为什么这件事能火
说实话,过去两年"低成本训出强模型"的故事不算稀奇。最有名的是去年李飞飞团队的 s1,50美元复刻 o1 级别的推理能力——但那是蒸馏+微调,本质上是站在 Qwen 已经训好的肩膀上。S1 的50美元买不到一个从头开始的基础模型。
HRM-Text 不一样,它是from scratch 的预训练。这是两个性质完全不同的事:
- 微调/蒸馏:依赖一个强大的教师模型,本质是知识的转移和压缩;
- 预训练:模型从随机初始化开始,要自己从数据里建立世界模型。
后者的成本曲线一直被认为很难压下来,因为"涌现能力"似乎跟训练算力呈幂律关系——这是 Kaplan 和 Chinchilla 两条scaling law反复印证的事。HRM-Text 的意义在于,它在小规模上给出了一个反例:架构改进可以撕开 scaling law 的口子。
这才是 Bengio 团队感兴趣的点。Bengio 这两年一直在公开质疑"无脑堆算力"的路线,主张回到"更结构化、更符合认知规律"的架构。HRM-Text 正好是这个方向上一个可验证的小样本。
性能到底什么水平:别被1500美元晃了眼
泼点冷水。1B 参数的 HRM-Text 在通用 benchmark 上跟同尺寸的 Pythia-1B、TinyLlama 比,结果是"互有胜负"——这意味着它没有打破上限,只是用更少的钱达到了同档位的水平。
具体数据:
- HellaSwag:略高于 TinyLlama,低于 Pythia-1.4B;
- ARC-Challenge:和同尺寸模型基本持平;
- GSM8K:明显占优,这跟它的分层架构擅长多步推理有关;
- 长文本困惑度:在2k以上窗口表现优于同尺寸 baseline。
所以你要问"这个1B模型能不能上生产",答案大概率是不能直接替代你正在用的 Qwen-1.5B 或 Phi-3-mini。但你要问"这套方法论是不是值得跟进"——非常值得。
更关键的是 scaling 问题。HRM 这套分层机制能不能放大到 7B、70B 还保持效率优势?目前没有公开实验数据,团队论文里也只是"展望未来工作"。这是悬在头上的最大问号。历史上很多在小规模上闪闪发光的架构(比如各种Linear Attention变体),一放大就被Transformer标准实现按在地上摩擦。
1500美元这个数字背后的算账逻辑
看看团队是怎么把成本压下来的:
- GPU选型:用的不是H100,是相对便宜的 A100 甚至更早一代。16卡集群按云上spot价大约每小时几美元;
- 训练时长:1.9天,约45小时;
- 数据量:远小于Chinchilla最优配比,团队用架构效率换数据量;
- 没算研发人力:这1500美元只是"按下回车键之后的电费",前面的架构调试、数据清洗、超参搜索没算进去。
第4点很重要。每次有"几十美元/几千美元训出强模型"的新闻出来,评论区都会有人精确开炮:你这是把研究员的工资、失败实验的算力、数据预处理的成本全摘出去了。这种批评是对的——1500美元是"复现成本",不是"发明成本"。
但反过来说,复现成本压低本身就是巨大价值。它意味着:
- 学术界小实验室可以跑得起对照实验;
- 创业公司可以低成本做领域预训练(医疗、法律、代码);
- 教育场景可以让学生真的训一个模型而不是只看论文。
开源社区已经有人在 fork 这套代码尝试做 1.5B、3B 的复现。预计两周内会有第一波非官方benchmark出来。
行业影响:scaling law 又被挑战了一次
这两年挑战 scaling law 的工作不少:
- 数据侧:Phi 系列证明"教科书质量"数据可以小博大;
- 架构侧:Mamba、RetNet 等线性架构试图打破注意力的二次复杂度;
- 训练侧:MoE 用稀疏激活摊薄推理成本;
- 后训练侧:DPO、RLHF 的各种变体把对齐成本压到了万元级;
- 蒸馏侧:DeepSeek 把强模型能力往小模型里塞的效率不断刷新。
HRM-Text 属于"架构+数据"组合拳,且打的是预训练这个最硬的骨头。它的存在不会推翻 scaling law,但会让所有人重新审视一个问题:我们现在烧的算力,有多少是真正用在了"模型学到新东西"上,有多少是被无效计算消耗掉的?
如果有一半是后者,那行业过去三年的算力军备竞赛就有相当一部分是浪费。考虑到 OpenAI、Anthropic、xAI 这些头部玩家年算力支出已经在百亿美金量级,这个问题的答案值很多钱。
开发者怎么用上
HRM-Text 已经在 HuggingFace 开源,weights 和训练代码都放出来了。一些上手建议:
- 想跑 inference:直接
transformers加载,但要装一个自定义的 modeling 文件,因为分层结构不在标准实现里; - 想做领域微调:作者推荐用 LoRA,因为分层结构对全参数微调比较敏感,容易破坏高低层的协同;
- 想复现训练:训练代码用的是 nanoGPT 的fork,可读性不错,但16卡A100的硬件门槛仍然在;
- 想做架构创新:高低层的更新频率比、门控机制、课程数据顺序,都还是开放的超参空间。
OpenAI Hub 这边也已经把 HRM-Text 接入了开源模型路由,可以用统一的 OpenAI 兼容接口直接调用,省了自己部署的麻烦。
几个还没回答的问题
最后留几个值得继续追的点:
- 可扩展性:HRM 放大到 7B 以上还能保持效率优势吗?
- 多模态:分层时间尺度的思路在视觉、音频上似乎更自然,会不会有 HRM-Vision、HRM-Audio?
- 推理效率:训练便宜了,推理呢?分层结构对 KV cache 的影响目前还没充分评估;
- 对齐:基础模型出来了,instruct 版本和 RLHF 版本什么时候有?
- 跟 SSM 系(Mamba)的关系:两者都在试图打破 Transformer 的统一架构,最终会融合还是相互替代?
这些问题大概率在接下来的两三个月里会陆续有答案——这就是开源社区的速度。
一点判断
HRM-Text 单独看,是一个聪明的小工作。但放在更大的图景里,它是"后 scaling law 时代"的又一个信号:当头部玩家继续烧钱推 GPT-5、Claude 4 这种 frontier model 时,另一条路径正在成熟——用架构效率换算力成本,让基础模型训练从大厂特权变成中小团队也能下场的事。
这条路不会很快取代主流路线,但它会持续侵蚀"必须有几万张卡才能玩 AI"的叙事。对开发者来说,这是好消息:未来三年,能用得起、改得动、调得明白的开源基础模型只会越来越多。
至于 HRM-Text 本身会不会真的成为下一代主流架构?说实话,过去两年类似的"挑战者"出现过太多,活下来的不多。但每一个挑战者都在往同一个方向推:让 AI 更便宜、更可解释、更不依赖蛮力。这个方向本身,是对的。
参考来源
- HuggingFace - HRM-Text 模型主页 — HRM-Text 的权重、配置和示例代码托管位置,可直接加载使用
- Reddit r/MachineLearning - HRM-Text 讨论帖 — 社区对训练成本、架构设计的技术讨论,包含作者答疑
- Zhihu - 关于 HRM 分层架构的解读 — 中文社区对分层推理模型架构原理的深入分析


