SILX AI 发布 Quasar-Preview:18B MoE 架构挑战长上下文极限

SILX AI 推出实验性模型 Quasar-Preview,采用 18B MoE 架构,号称支持 500 万 token 长上下文。这个规格听起来很炸裂,但实际表现如何?我们从技术架构、应用场景和竞品对比三个维度,看看这个模型到底是真突破还是纸面参数。
SILX AI 发布 Quasar-Preview:18B MoE 架构挑战长上下文极限
今天 SILX AI 扔出一颗炸弹——Quasar-Preview 实验模型正式发布。18B 参数的 MoE 架构,号称支持 500 万 token 的长上下文。这个数字什么概念?相当于你能往模型里塞进 3000 多页的技术文档,或者几十小时的会议录音转写文本。
但行业里见过太多"纸面参数猛如虎,实测五分不如狗"的案例。500 万 token 的上下文窗口,真能用得上?还是只是个 marketing gimmick?我们从架构、性能和实际场景三个角度,把这个模型拆开看。
MoE 架构:小模型办大事的正确姿势
先说架构。Quasar-Preview 用的是 Mixture of Experts(MoE)架构,18B 总参数,但每次推理只激活其中一部分专家网络。这个设计思路跟阿里的 Qwen3 系列、Google 的 Gemini 1.5 Flash-8B 如出一辙——用稀疏激活换推理效率。
MoE 的好处很明显:推理成本低、速度快,同时保持模型容量。18B 参数听起来不大,但如果激活率控制在 20-30%,实际计算量相当于 4-6B 的稠密模型,这个效率在生产环境里很实用。
对比一下竞品的做法:
-
Qwen3-30B-A3B:305 亿总参数,33 亿激活参数,原生支持 256K 上下文,可扩展至 1M token。阿里这个模型在指令遵循、多语言支持、工具调用上做了大量优化,定位是通用场景的 workhorse。
-
Gemini 1.5 Flash-8B:80 亿参数,专攻多模态和长文本摘要,上下文窗口 200 万 token。Google 的优势在视觉理解和跨模态推理,但纯文本处理上跟 Qwen 比还有差距。
-
DeepSeek-V3.1:万亿参数规模,MoE 架构,编程和推理能力登顶多个榜单。但这是真·大模型,推理成本和部署门槛不是 18B 模型能比的。
Quasar-Preview 的 18B MoE 定位很清晰:不跟万亿参数模型硬刚智力天花板,而是在长上下文这个细分赛道上做到极致。500 万 token 的窗口,比 Qwen3 的 256K 扩展版(1M)还要大 5 倍,比 Gemini 1.5 Flash 的 200 万 token 大 2.5 倍。这个数字如果能落地,确实是个差异化优势。
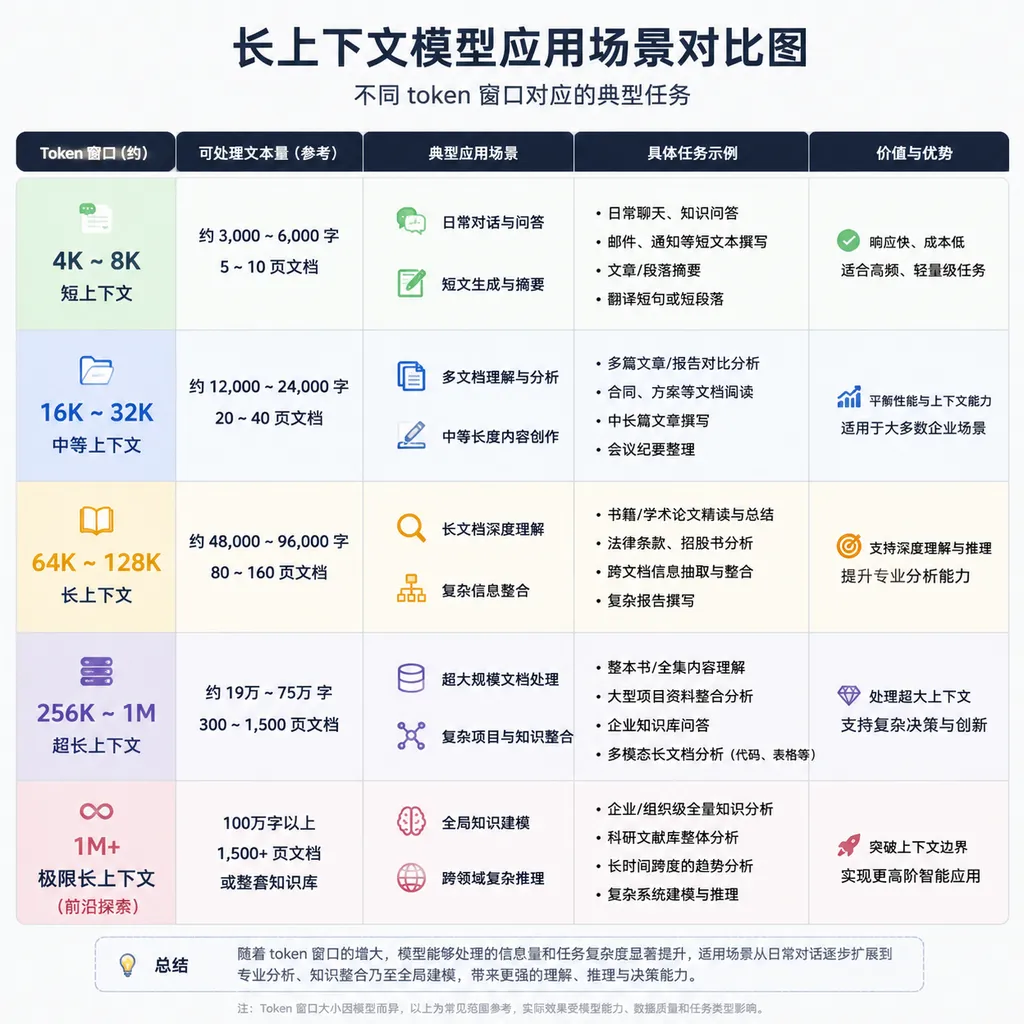
500 万 token:技术突破还是参数灌水?
长上下文不是新鲜事,但 500 万 token 这个规格很罕见。目前开源模型里,Qwen3-VL 和 Qwen3-Omni 都支持 256K 原生上下文,扩展至 100 万;闭源阵营里,Claude 3.5 Sonnet 支持 200K,Gemini 1.5 Pro 支持 200 万。500 万 token 的窗口,SILX AI 怎么做到的?
关键在两个技术点:
1. 位置编码优化
传统的 RoPE(Rotary Position Embedding)在超长序列上会遇到插值失真问题。Qwen3 系列用的是改进版 RoPE,通过 NTK-aware interpolation 和 YaRN 方法,把有效上下文从 32K 扩展到 256K,再通过 sliding window attention 推到 1M。
Quasar-Preview 可能用了类似的技术栈,但 500 万 token 意味着位置编码的插值精度要求更高。如果处理不好,模型在超长序列尾部的注意力会衰减严重,相当于"只记得开头,忘了结尾"。
2. 注意力机制改造
Full attention 在 500 万 token 下计算复杂度是 O(n²),显存和算力都扛不住。业界主流做法是分段注意力(sliding window)+ 稀疏注意力(sparse attention)的混合方案。
比如 Gemini 1.5 Pro 用的是 Ring Attention,把长序列切成多个 chunk,每个 chunk 内部做 full attention,chunk 之间通过环形通信共享 KV cache。这个方案的优势是显存占用线性增长,但需要多卡并行。
如果 Quasar-Preview 要在单卡或小规模集群上跑 500 万 token,注意力机制的优化肯定更激进。可能会牺牲一部分全局依赖建模能力,换取更长的有效窗口。
但这里有个问题:长上下文不等于有效上下文。Claude 3.5 Sonnet 的 200K 窗口,实测在 100K 以上的检索准确率会明显下降;Gemini 1.5 Pro 的 200 万 token,Google 官方推荐的实际使用场景也就几十万 token。500 万 token 的 Quasar-Preview,如果有效窗口只有 100-200 万,那这个参数就有灌水嫌疑。
SILX AI 目前没有公开 benchmark 数据,比如 RULER(长上下文检索能力测试)或 LongBench(长文本理解基准)的得分。在看到实测数据之前,500 万 token 这个数字只能打个问号。
实际场景:谁需要 500 万 token?
退一步说,就算 Quasar-Preview 的 500 万 token 是真实有效的,这个能力对应的应用场景在哪?
场景 1:代码库级别的理解与重构
一个中型项目的代码库,全量代码 + 文档 + 提交历史,很容易超过 100 万 token。如果要做跨文件的依赖分析、架构重构建议、技术债检测,长上下文模型确实有价值。
但这个场景里,Qwen3-Coder-30B-A3B 已经支持 256K 上下文,配合 RAG(检索增强生成)可以覆盖更大规模的代码库。500 万 token 的优势不明显,除非你要一次性处理整个 Linux 内核源码(约 300 万行,折合 1500 万 token)。
场景 2:超长会议或播客的全量分析
Qwen3-Omni 能处理 30 分钟会议录音,Quasar-Preview 理论上能处理几十小时的内容。这个能力对企业会议纪要、法律诉讼记录、学术讲座整理有用。
但问题是,真有人需要一次性处理 10 小时的会议录音吗?大部分场景下,分段处理 + 摘要合并的效果不比全量上下文差,而且成本更低。除非你要做跨时间线的因果推理(比如"第 3 小时的决策是基于第 1 小时的哪个讨论点"),否则 500 万 token 有点浪费。
场景 3:多模态数据的联合推理
如果 Quasar-Preview 支持多模态输入(目前没有官方信息),500 万 token 可以同时处理几百张图片 + 长文本 + 音频。比如医疗影像分析(CT 扫描序列 + 病历 + 检查报告),或者工业质检(生产线视频 + 传感器数据 + 操作日志)。
这个方向有想象空间,但目前多模态长上下文的技术还不成熟。Qwen3-VL 支持 2 小时视频 + 256K 文本,已经是开源模型的天花板。Quasar-Preview 如果没有多模态能力,500 万 token 的应用场景会更窄。
竞品对比:Quasar-Preview 的差异化在哪?
把 Quasar-Preview 放到当前的模型生态里,它的定位是什么?
| 模型 | 参数规模 | 上下文窗口 | 核心优势 | 适用场景 | |------|----------|------------|----------|----------| | Quasar-Preview | 18B MoE | 500 万 token | 超长上下文 | 超大规模文档分析、跨时间线推理 | | Qwen3-30B-A3B | 305B/33B 激活 | 256K(扩展至 1M) | 通用能力均衡、工具调用强 | 企业级应用、Agent 开发 | | Gemini 1.5 Flash-8B | 80 亿 | 200 万 token | 多模态、成本低 | 多模态摘要、长视频理解 | | DeepSeek-V3.1 | 万亿参数 | 256K | 编程、推理能力顶尖 | 复杂推理、代码生成 | | Claude 3.5 Sonnet | 未公开 | 200K | 指令遵循、安全对齐 | 对话、写作、分析 |
从这个对比看,Quasar-Preview 的差异化很明确:用更小的参数规模(18B)+ 更激进的架构优化,去攻超长上下文这个细分赛道。
这个策略有两个好处:
-
部署门槛低:18B MoE 模型可以在单张 A100/H100 上跑起来,不需要多卡并行。对中小团队或边缘部署场景友好。
-
推理成本可控:MoE 架构的稀疏激活意味着推理速度快、能耗低。如果 SILX AI 把推理价格打到 Qwen3-30B 的一半,性价比优势会很明显。
但劣势也很明显:
-
通用能力未知:目前没有公开的 benchmark 数据,不知道 Quasar-Preview 在数学推理、代码生成、多语言理解等通用任务上的表现如何。如果只是长上下文强、其他能力拉胯,应用场景会很局限。
-
生态支持缺失:Qwen3 系列有阿里云百炼平台、魔搭社区、Hugging Face 的完整生态;DeepSeek 有开源社区的广泛支持。Quasar-Preview 作为一个新玩家,需要时间建立开发者生态。
开源还是闭源?定价策略很关键
SILX AI 目前没有公布 Quasar-Preview 的开源计划和定价策略。这是个关键问题。
如果是开源模型,500 万 token 的长上下文能力会吸引一波技术极客和研究者。但开源模型的商业化路径不清晰,除非 SILX AI 有配套的云服务或企业版方案。
如果是闭源 API,定价就得跟 Qwen3、Gemini、Claude 比。以 Qwen3-30B 为例,阿里云百炼的价格是:
- 输入:0.4 元 / 百万 token
- 输出:1.2 元 / 百万 token
假设处理一次 500 万 token 的输入 + 1 万 token 的输出(生成一份详细报告),成本约 2 元。如果 Quasar-Preview 的价格是这个数字的 2-3 倍,吸引力会大打折扣。
更现实的策略是分层定价:提供免费或低价的 256K 上下文版本,吸引开发者试用;500 万 token 的超长上下文作为 premium 功能,按需收费。这样既能快速积累用户,又能通过高端需求变现。
技术路线的选择:长上下文 vs. RAG
最后聊个更本质的问题:长上下文模型真的比 RAG(检索增强生成)方案更优吗?
RAG 的逻辑是:不需要把所有数据塞进上下文,而是通过向量检索找到最相关的片段,再交给模型处理。这个方案的优势是成本低、扩展性好,劣势是检索精度受限、跨片段推理能力弱。
长上下文模型的逻辑是:把所有数据一次性喂给模型,让模型做全局理解和推理。优势是不损失信息、推理能力强,劣势是成本高、对模型能力要求高。
在实际应用中,这两个方案不是非此即彼,而是混合使用:
- 用 RAG 做粗筛,把 TB 级的数据库缩减到几百万 token 的候选集;
- 用长上下文模型做精读,在候选集内做深度推理和生成。
Qwen3 系列就是这个思路。阿里云的百炼平台提供了向量数据库(OSS 向量存储)+ 长上下文模型(Qwen3-30B)的完整方案,开发者可以根据场景灵活组合。
Quasar-Preview 的 500 万 token 窗口,如果能跟 RAG 方案打通,价值会更大。比如:
- 第一步:用 RAG 从 10TB 的企业知识库里检索出 1000 万 token 的候选文档;
- 第二步:用 Quasar-Preview 处理这 1000 万 token,生成结构化的分析报告;
- 第三步:用小模型(如 Qwen3-8B)做最终的格式化输出。
这个流程既保证了信息覆盖度,又控制了成本。如果 SILX AI 能提供配套的工具链(向量数据库、检索优化、模型编排),Quasar-Preview 会更有竞争力。
结语:等实测数据,别急着下结论
Quasar-Preview 的发布很有意思。18B MoE + 500 万 token 这个组合,在纸面上确实亮眼。但 AI 模型行业见过太多"发布即巅峰"的案例,真正的价值要在生产环境里跑一跑才知道。
目前 SILX AI 没有公开几个关键信息:
- Benchmark 数据:RULER、LongBench、MMLU、HumanEval 等基准测试的得分如何?
- 有效上下文:500 万 token 的窗口,实际可用的检索准确率和推理能力到什么水平?
- 定价策略:开源还是闭源?API 调用价格多少?
- 应用案例:有没有真实场景的落地案例?
等这些信息出来,再下结论不迟。如果 Quasar-Preview 能在长上下文这个赛道上做出差异化,配合合理的定价和生态支持,确实有机会切下一块市场。但如果只是参数好看、实测拉胯,那就是另一个故事了。
对开发者来说,现阶段更务实的选择还是 Qwen3 系列或 Gemini 1.5。这些模型有完整的文档、稳定的 API、丰富的应用案例,踩坑成本低。Quasar-Preview 可以关注,但别急着 all-in。
参考来源
- 硅基流动 SiliconFlow - 模型列表 - SILX AI 官方模型服务平台,可查看 Quasar-Preview 的技术规格和调用方式
- 机器之心产业资讯 - AI 行业新闻聚合,覆盖模型发布、技术突破、应用案例
- 生成式 AI 大模型动态周报 - 追踪 OpenAI、Google、阿里等主流厂商的模型更新,包含 Qwen3、Gemini、DeepSeek 等竞品对比

