智平方NeuroVLA:把机器人「大脑小脑脊髓」拆开做

智平方在2026智源大会上发布全球首个类脑式具身智能系统NeuroVLA,用皮层-小脑-脊髓三级架构把传统VLA的单体大模型拆解,碰撞反射缩到20毫秒,脊髓层功耗仅0.4瓦。
6月13日的北京智源大会上,智平方创始人郭彦东把NeuroVLA端了出来——这是一个把人脑「皮层-小脑-脊髓」三层结构搬进机器人大模型的具身智能系统,他们自己定义为「全球首个类脑架构VLA」。
如果你最近一直在追VLA(Vision-Language-Action)这条线,应该能感觉到一个微妙的转向:过去两年大家忙着把视觉、语言、动作塞进一个端到端大模型里,证明「一个网络解决一切」是可行的;但2026年开始,越来越多的玩家意识到,这种「单体大脑」在真实物理世界里碰壁了。NeuroVLA是这一波转向里走得最激进的一个。
单体VLA的天花板,到底卡在哪
先说清楚为什么要做类脑架构。传统VLA的做法很直接:视觉编码器+语言模型+动作解码器,端到端训练,输入图像和指令,输出动作序列。OpenVLA、RT-2、π0这一系是典型代表。
这套范式在演示视频里很惊艳,但部署到工厂或者家庭场景,三个老问题一直没解决:
- 响应延迟:一个动作要走完完整的「感知-推理-生成」链路,少则一百多毫秒,多则三五百毫秒。机器人撞到人之后再开始想「我该怎么办」,已经太晚了。
- 动作抖动:大模型的高频运动控制能力先天不足,做精细操作时会有明显的颤抖和过冲,靠后处理滤波只能缓解。
- 能耗失控:跑一个7B的VLA模型,机载GPU功率几十瓦起步,移动机器人续航被吃得很惨。
智平方给的解法是——人脑就不是这么干的,凭什么机器人非要这么干?
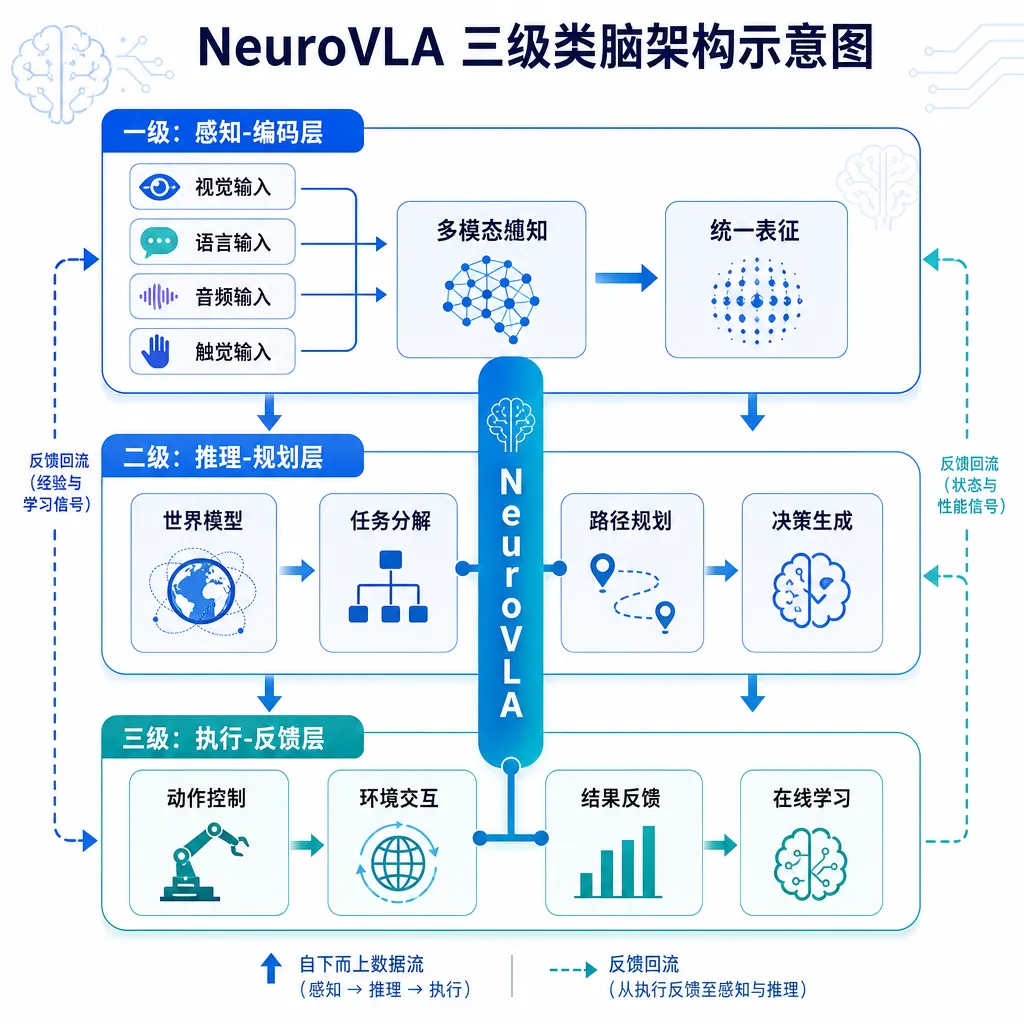
三层架构,各干各的
NeuroVLA把整个系统按生物学层级拆成三块,每一层有自己的频率和职责:
皮层(Cortex):慢思考
负责语义理解、任务规划、长程推理。这一层基本对应传统VLA里的多模态大模型部分,跑在主控算力上,频率不高(几Hz到十几Hz),但管得宽——「把桌上那杯咖啡递给穿蓝衣服的人」这种话,是这一层听懂的。
小脑(Cerebellum):高频运动协调
这是NeuroVLA最关键的一层。小脑层接收皮层下发的动作意图,负责把它细化成平滑、稳定、连贯的运动轨迹,并根据实时反馈做动态修正。官方数据是这一层把运动抖动降低了75%以上——这个数字如果实测能复现,对精细操作场景的意义非常大。
小脑层的设计借鉴了生物小脑的「前馈+反馈」控制思路,不再让大模型直接吐关节角度,而是由专门的运动协调模块来做插值、平滑和扰动补偿。
脊髓(Spinal Cord):反射弧
这一层是最有意思的。脊髓层只干一件事:在毫秒级时间窗口内对危险信号做出反射性响应。碰撞、跌落、夹手——这些场景下根本来不及让皮层「思考」,必须像人不小心摸到烫的东西会瞬间缩手一样,绕开大脑直接处理。
NeuroVLA的脊髓层把碰撞-反射响应做到了20毫秒。作为对比,传统VLA系统这个数字超过200毫秒,差了一个数量级。更重要的是,碰撞之后的任务恢复成功率从0%(传统VLA基本就当场死机)提升到了54.8%——也就是说机器人不光能躲开,还能调整路径接着干活。
脉冲神经网络,外加在线学习
脊髓层用了脉冲神经网络(SNN)做动作头,训练算法是R-STDP(奖励调制的STDP)。这两个组合在学术圈不算新概念,但被严肃地用在量产机器人上,NeuroVLA算是头一波。
SNN的好处一是低功耗——官方披露脊髓层执行任务时平均功耗只有0.4瓦,比一部手机播放视频还低;二是天然适合处理时序信号和事件驱动型任务,正好对得上「反射」这种用例。
R-STDP则带来一个有意思的能力:部署阶段的在线自适应。说人话就是机器人在工厂里干着干着,自己就能针对当前场景微调脊髓层的响应,类似人类反复练习一个动作后形成的「肌肉记忆」。这一点对于工业场景的长尾问题处理非常关键——工厂里每条产线的细节都不一样,让机器人能自己适应而不是每次都回炉训练,价值很大。
这个架构到底解决了什么
把NeuroVLA和传统VLA放一起比,差异可以列得很清楚:
| 维度 | 传统VLA | NeuroVLA | | --- | --- | --- | | 架构 | 单体端到端大模型 | 皮层-小脑-脊髓三层分工 | | 碰撞反射延迟 | >200ms | 20ms | | 运动抖动 | 基准 | 降低75%+ | | 反射后任务恢复率 | 0% | 54.8% | | 脊髓层功耗 | N/A | 0.4W | | 在线学习 | 通常不支持 | R-STDP支持 |
值得注意的是,三层之间不是简单的串行调用,而是并行运行、互不阻塞。皮层在做慢思考的时候,小脑该跑还在跑,脊髓的反射弧永远在线。这一点其实是类脑设计最本质的优势——把不同时间尺度的任务交给不同的子系统处理,而不是让一个大模型既要管语义又要管毫秒级反应。
说白了,这就是把软件架构里「关注点分离」的思想,搬到了具身智能的模型架构层面。

已经在跑的商业化
智平方不是只发了一个论文级的Demo。会上同时披露了几个落地数据点:
- NeuroVLA已在AlphaBrain Platform开源——这对开发者是个好消息,意味着可以拿来研究和二次开发
- 商业化场景已经覆盖汽车、半导体等工业产线
- 自有产品「智魔方」机器人店员业态落地全国十余省份
郭彦东在会上抛了一句话挺值得琢磨:通用智能机器人是继PC、手机、汽车之后的「第四代智能终端」,行业应该回归技术创新、避免烧钱内卷。这话从一家正在做量产的公司CEO嘴里说出来,多少带点行业喊话的意味——过去一年具身智能这个赛道明星公司一堆,融资数字也很好看,但真正能拿出工程化落地数据的并不多。
类脑VLA是不是下一站
回到一个更大的问题:单体端到端VLA还是分层类脑架构,哪条路对?
从NeuroVLA的数据看,类脑路线在安全、稳定、能耗这三个工程化最关键的维度上拿到了明显的优势。但代价也很现实——架构复杂度上去了,三层之间的协同训练、通信延迟、故障处理都是新问题;皮层和小脑之间的接口怎么设计才能既灵活又高效,本身就是个开放问题。
端到端派的反驳大概会是:「你这是开倒车,scaling law能解决的问题不需要先验结构」。这个争论在大模型领域并不新鲜,只是现在搬到了具身智能。
我个人倾向于认为,物理世界的实时性约束是scaling解决不了的硬约束。你可以把一个VLA模型从7B堆到70B、700B,但光速和电路延迟摆在那里,单体大模型走完一次前向传播需要的时间不会因为参数变多就消失。在这一点上,类脑分层架构有结构性的优势。
至于NeuroVLA本身——它给出的20ms反射、0.4W功耗、75%抖动抑制,如果在第三方测评和更多场景里能稳定复现,那这个架构思路大概率会成为接下来一两年里其他玩家跟进的方向。AlphaBrain Platform开源也降低了大家验证的门槛。
顺带一提,OpenAI Hub已经接入了一系列主流多模态模型,做VLA上层皮层模块开发的同学可以直接用一个Key切换GPT、Claude、Gemini、DeepSeek等模型来跑对比——三层架构里皮层那一层用哪个大模型,实际上是个工程取舍问题,值得多试几个看效果。
参考来源
- 具身大模型类脑技术谁走在最前面?2026大脑-小脑-脊髓分工协同能力评估 - IT之家 — 对NeuroVLA技术细节、性能数据和VLA三阶段演进论的深度梳理


