开源知识图谱+混合检索:把多跳推理这事做扎实

一位开发者在 Reddit 上放出了一套 Django+React 的全栈知识图谱管道,用 spaCy 抽实体、NetworkX 建共现图、社区聚类生成主题摘要,再叠加稠密向量和 BM25 双路召回,专治标准 RAG 在多跳问题上的"中间遗忘症"。
一个 Reddit 项目,把 GraphRAG 拆成了能跑的脚手架
这两天 r/MachineLearning 上一个项目被翻了出来:一位开发者把 Knowledge Graph + Hybrid Retrieval 这套被微软 GraphRAG 带火的玩法,做成了一个开源、可跑、有前端的全栈管道。Django 当后端、React 当界面,从原始文本一路打通到多跳问答。
这事的背景,做过 RAG 的人都不陌生。普通向量检索碰到"先问 A 跟谁有关、再问那个人又做过什么"这类需要跨文档串联的问题,基本就是抓瞎——要么命中头部最相关的几个 chunk 然后丢掉关键线索,要么把 top-K 拉大塞满上下文,然后撞上经典的 "lost in the middle",模型直接忽略中段信息。GraphRAG 思路本身没问题,但门槛不低:图怎么建、社区怎么切、检索怎么混,每一步都能踩坑。
这个项目的价值在于,它把这条链路从论文级别拉到了工程师可以 fork 下来直接看的程度。
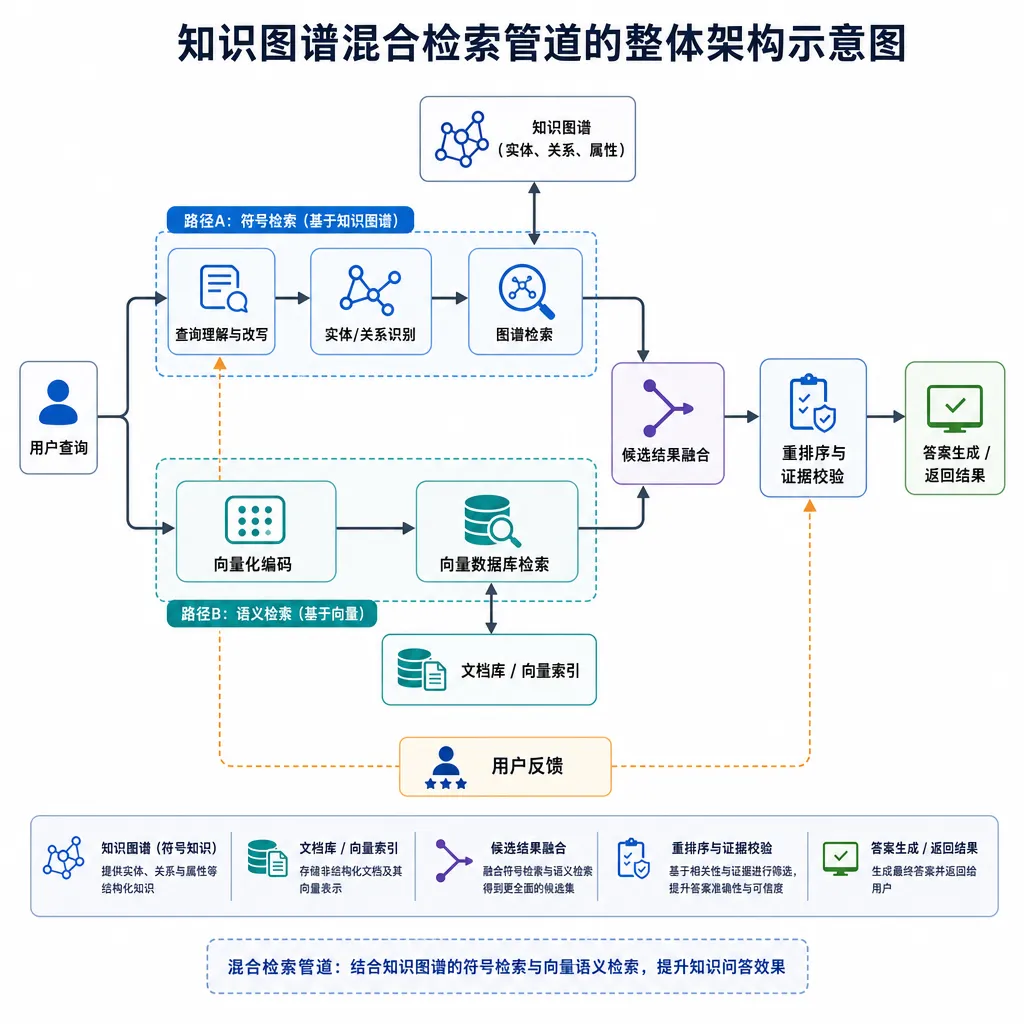
管道拆开看:五步走,每一步都有讲究
作者给的流程图很清晰,按顺序是 Ingestion → Graph Construction → Community Detection → Indexing → Hybrid Retrieval。我们一个个看,顺便聊聊每一步背后的工程取舍。
1. 切块:重叠 chunk 保留局部上下文
第一步是把原始文本清洗、解析,然后切成带 overlap 的 chunk。这一步看起来最朴素,但其实是后面所有花活的地基。重叠切块不是新东西,但在 GraphRAG 场景下尤其重要——因为后面要做实体共现,如果切得太干净,本来该被识别成"同一句话里出现"的两个实体就被切散了,图的边就少了一大批。
实战里,chunk size 一般在 300–800 token,overlap 取 10–20%。这个项目没强制规定,留给用户自己调,算是给了实践空间。
2. 建图:spaCy + NetworkX 的经典组合
对每个 chunk,作者用 spaCy 抽取命名实体,然后用 NetworkX 建一个加权共现图:节点是实体,边的权重对应"两个实体一起出现过多少次",同时每条边、每个节点都记录了反向指针——指回它来自哪些原始 chunk。
这一步是整个系统最关键的设计。它没用更花哨的 LLM 做关系抽取(比如 OpenIE 那种把谓词也抽出来),而是退回到最朴素的共现统计。代价是关系语义弱了,好处是稳定、可控、成本低。对企业内部知识库这种本来就有大量专有名词的场景,共现图其实已经能跑出 80% 的效果。
如果你做过相关项目,应该知道 LLM 抽三元组那条路有多脆——同一个实体能被换十几种说法,对齐麻烦得要死。这个项目直接用 spaCy 的实体边界做唯一标识,省了对齐这步。
3. 社区检测:贪心模块度切簇 + 防"枢纽节点偏置"
图建出来之后,下一步是用 greedy_modularity_communities 把图切成若干主题簇。这个算法是 NetworkX 自带的,思路是最大化模块度(modularity),把高度互连的节点归到一起。
切完之后,对每个簇,作者做了一个特别值得说的事:他不是把这个簇里所有 chunk 都塞给 LLM 总结,而是随机采样几个 chunk 再交给 LLM 生成主题摘要。
为什么?因为如果你直接按节点的度数排序拿 top chunks,那些超高频实体("公司"、"系统"、"用户"这种)会主导摘要内容,导致每个簇的摘要都长得差不多——这就是作者说的 "hub node bias"。随机采样能让小众但有特色的 chunk 也有机会进入摘要,主题区分度才出得来。
这是个很细节的工程经验,论文里基本不会写,但做过相关项目的人会拍大腿。
4. 索引:双轨并行,向量 + BM25
建完图、生成完社区摘要之后,作者把所有 chunk 同时灌进两套索引:
- 稠密向量库:用 embedding 模型把 chunk 向量化,存进向量数据库(项目里给的是可替换接口,FAISS、Chroma 都能接)
- 稀疏 BM25 索引:在同一语料上建一个传统的词频倒排索引
这两套索引覆盖的能力是互补的:向量擅长抓语义相近但用词不同的内容,BM25 擅长抓精确的术语、产品名、错误码这种"必须字面匹配"的查询。光用任一种都有死角,混合检索是 2024 年之后业界基本共识。
5. 混合检索:query 进来,双路召回
查询时,系统对 query 同时走两路:稠密语义召回 + 稀疏关键词召回,再做融合(一般是 RRF,Reciprocal Rank Fusion)。同时,借助第二步建好的图,可以从命中实体出发做 N 跳邻居扩展,把关联的 chunk 也捞进候选集。
这就是多跳推理能跑通的核心机制——用图结构把语义上相隔很远但事实上相连的 chunk 拉到一起。
它解决了什么真问题
讲完流程,回到一个更现实的问题:这套东西比标准 RAG 强在哪?
标准 RAG 最痛的两个场景:
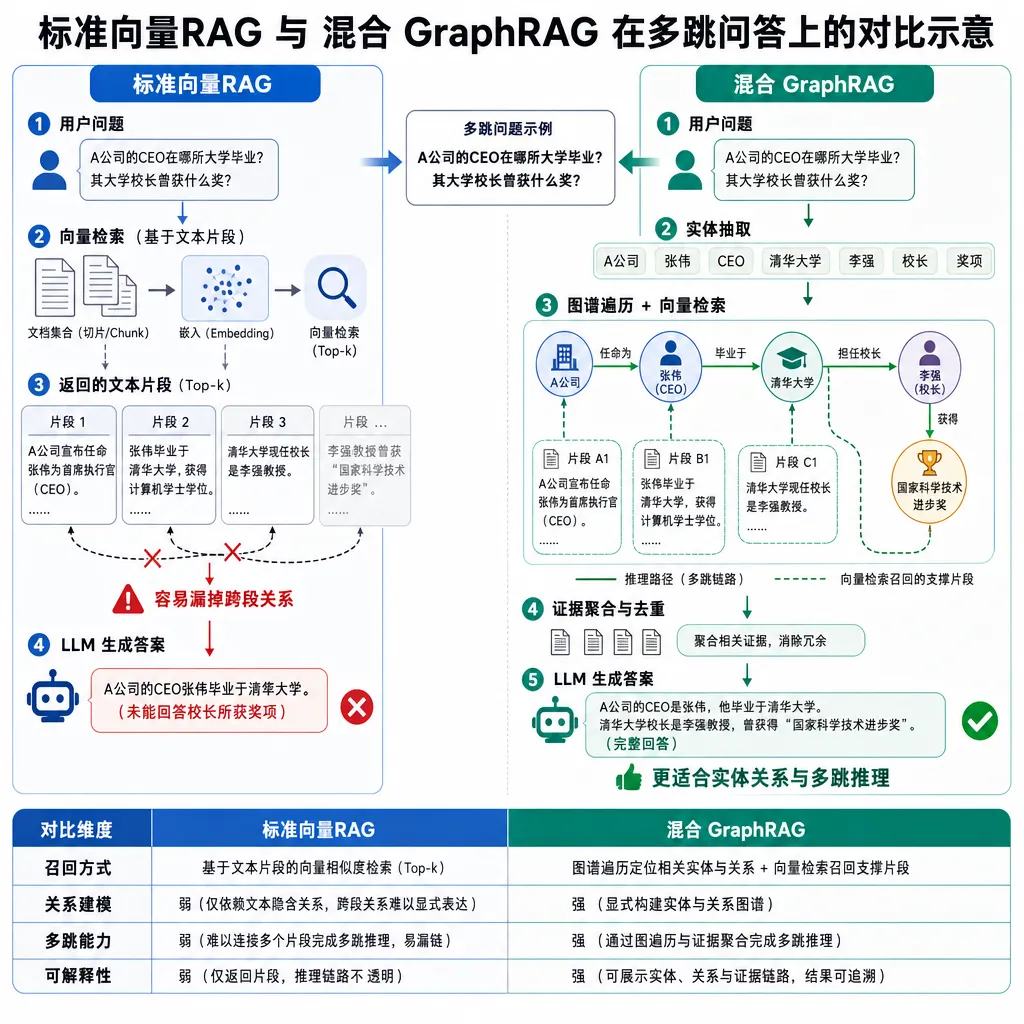
- 多跳问答:问"X 公司 2023 年的 CTO 后来去了哪家创业公司"。这种问题需要先定位 X 公司、再定位 CTO、再跳到新公司。向量检索一把召回,要么只命中 X 公司相关段,要么只命中那个人的段,很难一次性把链条凑齐。
- 全局性总结:问"这份 500 页报告的核心观点有几条"。向量召回是局部的,根本没法回答全局问题。
这个项目用社区摘要解决全局题、用图扩展解决多跳题,思路上是对的。微软 GraphRAG 论文里给的数据是,在多跳和总结类问题上 GraphRAG 比 vanilla RAG 提升 30–80%(依任务而定),这个开源项目虽然没给完整 benchmark,但架构上是对齐的。
几个值得吐槽的地方
当然也不是没毛病。
第一,spaCy 抽实体在中文场景不太够用,要换 LTP 或者直接上 LLM 做 NER,成本和延迟立刻上来。作者主要测的是英文语料,中文用户得自己改。
第二,greedy_modularity_communities 在图变大之后会很慢,几万节点级别就开始吃力,几十万就基本不能用了。生产场景要换 Leiden 算法(Microsoft GraphRAG 用的就是 Leiden),但 NetworkX 原生不带,得自己接 graspologic 或 cdlib。
第三,社区摘要的随机采样虽然解决了 hub 偏置,但反过来也引入了不稳定性——每次 rebuild 出来的摘要不一样,对生产环境的可观测性是个挑战。一般得固定随机种子、或者多次采样取交集。
第四,前端是 React 写的,看着挺好,但和 Django 后端的耦合方式不太适合直接嵌进现有系统。更适合当 demo 看,真要上生产还得拆。
给开发者的几个实用建议
如果你打算 fork 下来改改用,这里有几条经验:
- 先用小语料跑通,比如 10 万 token 以内的领域文档,把整个 pipeline 跑顺再扩量
- chunk size 和 overlap 一定要调,不同领域差异很大;技术文档可以小一点(300 左右),叙事文本要大一点(600+)
- 混合检索的融合权重别用默认值,针对你的查询类型做 grid search,关键词重的场景把 BM25 权重调高
- 社区粒度用 resolution 参数控制,问题越细的领域、簇要切得越细
- embedding 模型别图省事用 OpenAI 那个老的 ada-002,换成 BGE-M3、E5 或者 Qwen3-Embedding 这一档,多语言效果差距很大
顺便说一句,这套管道里需要调 LLM 的地方主要是社区摘要生成和最终回答,对模型本身没有强绑定。OpenAI Hub 上 GPT、Claude、Gemini、DeepSeek 这些主流模型用同一个 Key 都能跑,做对比实验时换模型只改 base_url 和 model name 就行,省得为每家 API 单独写适配。
写在最后
GraphRAG 这个方向从 2024 年微软发论文之后,业界一直在追,但真正能跑、能拆、能改的开源实现并不多。LangChain 和 LlamaIndex 都有图相关的模块,但要么太重、要么过于抽象,自己上手很难快速理解每一步在干嘛。
这个 Reddit 上的项目胜在完整且不繁琐——它没把自己包装成框架,就是一套能跑的脚手架,每一步都看得见。对想搞懂 GraphRAG 内部机制、或者想在自己业务里改一版的开发者,是个不错的起点。
知识图谱+混合检索这条路,长期看会比纯向量 RAG 更稳。语义召回的天花板就那么高,要做企业级的多跳推理和全局理解,结构化的东西早晚得加回来。
参考来源
- Reddit 原帖:开源知识图谱混合检索管道 — 项目作者在 r/MachineLearning 的发布与讨论
- RAG 进阶:混合稠密检索和知识图谱来提升精度(知乎专栏) — 关于混合检索+知识图谱在 RAG 精度提升上的实验分析


