Noiz AI 联手港科大清华开源音频大模型:单卡 0.24 秒四步出声

Noiz AI 联合港科大、清华团队开源了一款音频生成大模型,仅需 4 步采样、单张 GPU 0.24 秒即可生成一段高质量音频,还能听懂时间戳级别的精细控制指令,把 TTS 和音效生成卷到了一个新刻度。
又一个被「步数」按在地上摩擦的领域:音频
6 月 14 日,Noiz AI 联合港科大、清华团队在 GitHub 放出了一款音频生成大模型,主打两件事:四步采样、单卡 0.24 秒一段音频。再加一句听起来像锦上添花、但对工程师其实最关键的话——它听得懂时间戳。
这个组合扔出来,圈内人基本能看明白意思了:扩散模型那套「几十步采样换质量」的玩法,在音频领域也被一步步压扁,现在已经压到了和图像扩散加速(LCM、SDXL Turbo 那批工作)差不多的量级。更关键的是,他们顺手把可控性也补上了——这一点是过去一年 TTS / 音效生成赛道一直没解决干净的问题。
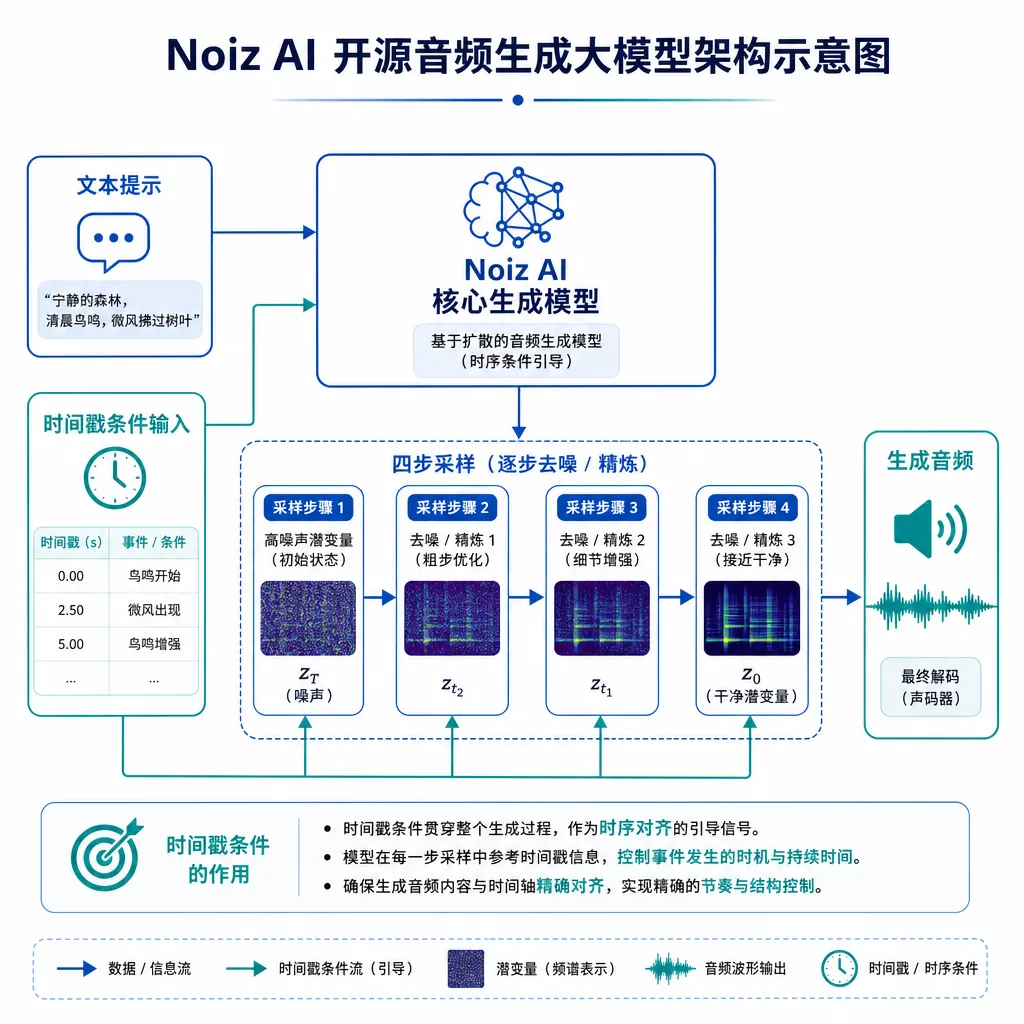
先把数字摆出来
按官方放出的基准数据(单卡 A100,FP16):
- 采样步数:4 步
- 端到端延迟:约 0.24 秒生成一段约 10 秒的音频
- RTF(Real-Time Factor):远低于 0.05,也就是说生成速度是实时播放的 20 倍以上
- 支持任务:文本转语音(TTS)、文本转音效(TTA)、人声 + 环境音混合生成
- 可控维度:时间戳级别的事件对齐、情感标签、说话人音色、语速、停顿
几个对比参照系:
- 一年前主流的 AudioLDM2、Stable Audio 这类工作,普遍要 50–200 步 DDIM 才能稳定收敛,单卡延迟在几秒级别。
- 即便是去年下半年大火的 ElevenLabs Turbo 系列,在做带情感的长句合成时,首包延迟也很难压到 200ms 以内。
- 国内开源派里,CosyVoice、F5-TTS 这一拨已经把质量做到接近商业产品,但「四步出声」这种量级的加速 + 时间戳控制还没见过。
所以这次的看点不是「又一个开源 TTS」,而是扩散音频模型的推理范式被改了。
四步是怎么做到的:一致性蒸馏 + 流匹配
看技术报告,Noiz 这套方案不是单点优化,而是几条线一起上:
1. 把扩散换成流匹配(Flow Matching)
传统 DDPM/DDIM 的训练目标是预测每一步的噪声,推理时必须沿着 SDE/ODE 一步步走。Flow Matching 直接学一个从噪声到数据的连续向量场,ODE 求解时步数可以大幅压缩。这条路子在图像生成(Stable Diffusion 3、Flux)和视频生成(Sora 那一脉)已经被验证,现在被搬到了音频。
2. 一致性模型蒸馏(Consistency Distillation)
光有 Flow Matching 还不够,他们再叠一层一致性蒸馏:让模型在任意起点直接预测 ODE 终点。这就是为什么能从动辄几十步压到 4 步——本质上是「教师模型走 50 步学到的东西,学生模型一步逼近」。
3. 潜空间扩散,而非波形扩散
模型工作在 VAE 编码后的潜空间(latent),帧率被压缩了几十倍,再加上一个轻量神经声码器把 latent 解码回 24kHz 波形。这套架构是借鉴了 Stable Audio 的思路,但 VAE 和声码器都是自己重训过的,对人声和音效混合场景做了适配。
4. DiT 主干 + 时间戳交叉注意力
骨干是 Diffusion Transformer(DiT),相比 U-Net 在长序列上更稳。时间戳的注入方式是把每个事件的 (start, end, label) 编码成条件 token,喂进交叉注意力——这一步是「听懂时间戳」的关键。
「听懂时间戳」到底是什么意思
这点值得展开说,因为这是这次发布里最被低估、但对开发者最实用的能力。
过去你让 TTS 念一段台词,最多控制下情感、语速。你让 TTA(文本到音效)生成「下雨、雷声、远处有狗叫」,模型大概率会把三个声音堆在一起,至于狗叫在第几秒响、雷声什么时候打,全凭运气。
Noiz 这个模型允许你这样写 prompt:
[0.0s-2.0s] 雨声,中等强度
[1.5s-2.2s] 远处雷声,低频
[3.0s-3.5s] 狗叫,两声
[4.0s-7.0s] 雨声逐渐变小
生成出来的 10 秒音频,事件的起止位置基本能对得上——官方报告里给出的对齐误差在 100ms 量级。
这对什么场景有用?
- 视频配音:剪辑师做镜头切换时,希望音效卡在画面切换的那一帧,过去得靠人工对齐
- 游戏音频:动作触发音效要求毫秒级响应,传统生成模型完全没法用
- 有声书 / 播客:旁白、对话、背景音乐的时序衔接
- 多模态 Agent:当 LLM 要让虚拟角色「在说『你好』的同时挥手」,时间戳是唯一让音频和动作对齐的语言
说白了,时间戳是音频模型从「玩具」变成「生产工具」的那条必经之路。这一点之前只有少数闭源商业模型(比如 ElevenLabs 的 Sound Effects API、Suno 的 stems 模式)部分做到了,开源世界这是头一份。
训练数据和模型规模
报告里披露的细节:
- 训练数据:约 20 万小时音频,覆盖中英日韩四语言的语音数据,以及 BBC Sound Effects、Freesound 等开源音效库,再加上自有版权数据
- 模型参数:主干 DiT 约 1.3B,VAE + 声码器合计约 200M
- 训练算力:未明确,但从规模推断应该是数百张 H100 量级的训练
相比一些纯学术开源工作,20 万小时这个量级算是「准工业」体量了——这也是为什么生成质量能拉到商业可用水平。
跟同行比,它处在什么位置
把市面上主流的开源 / 半开源音频生成模型摆一起看:
| 模型 | 任务 | 采样步数 | 时间戳控制 | 开源程度 | |---|---|---|---|---| | Stable Audio Open | 音乐 / 音效 | ~100 | 否 | 完全开源 | | AudioLDM2 | 音效 / 语音 | ~200 | 否 | 完全开源 | | CosyVoice 2 | TTS | ~25 | 否 | 完全开源 | | F5-TTS | TTS | ~32 | 否 | 完全开源 | | ElevenLabs Turbo | TTS | 未公开 | 部分 | 闭源 API | | Suno v4 | 音乐 | 未公开 | 部分 | 闭源 | | Noiz Audio | TTS + 音效 | 4 | 是 | 完全开源 |
这张表里 Noiz 的位置一目了然:唯一一个同时支持 TTS 和音效、采样步数压到个位数、还带时间戳控制的完全开源模型。当然,表格不能说明全部——音质 MOS、情感表现力、特殊语种这些维度还得等社区做更广泛的盲测。但从架构和首批 demo 看,至少不会落到下风。
一点点冷水
讲完优点也得说几个值得留意的点:
- 歌唱合成(SVS)能力薄弱。这版本主打念白和音效,唱歌不是它的目标场景,想做音乐生成的还得看 Suno、Udio、或者 DiffSinger 那一脉。
- 小语种泛化。20 万小时数据里主要是中英日韩,西班牙语、阿拉伯语这些虽然能生成,但音质和自然度会明显下降。
- 零样本声音克隆仅支持 3 秒参考音频时质量稳定,更短的样本会出现音色漂移——这一点不如 ElevenLabs 在工程上打磨得细。
- License。代码是 Apache 2.0,但部分预训练权重采用了非商用条款,商业落地要自己重新检查。这个坑过去 Stable Diffusion、Llama 都踩过,开发者要看清楚。
对开发者意味着什么
这一波音频模型的「步数革命」最直接的影响有两个:
第一,实时音频生成第一次进入了消费级硬件可达的区间。0.24 秒单卡 A100,意味着换到 4090 上做推理也就是 0.5–1 秒之间,本地部署做实时对话 Agent、游戏 NPC 已经不再是 PPT 级别的事。
第二,音频不再是多模态 Agent 的瓶颈环节。过去做 Voice Agent,TTS 的首包延迟(TTFB)经常和 LLM 的首 token 时间打平甚至更长。现在四步采样把 TTS 的首包压到几十毫秒级别,瓶颈彻底回到 LLM 这边——这也意味着「打断式对话」「实时低延迟语音交互」会有一波新玩家冒出来。
对集成方来说,主流大模型聚合平台(包括我们 OpenAI Hub)会陆续把这类开源音频模型纳入统一 API,开发者用一个 Key 就能在同一个项目里同时调 GPT-5、Claude 4、Gemini 3 和这种新出的音频模型,省去自己部署 GPU 的麻烦。但说实话,这个模型部署门槛已经不高,自己用 vLLM-style 的服务化方案跑一份本地推理也完全可以。
写在最后
2025 年下半年到 2026 年初,开源世界在视频和语音两个赛道追得很凶。视频那边有 Wan、Open-Sora、CogVideoX 一路压价;语音和音频这边则是 CosyVoice、F5-TTS、再到今天的 Noiz Audio——每一波都在把「可商用、可控、低延迟」这三件事往一起凑。
Noiz 这次的工作没有什么颠覆性的全新概念,用的是 Flow Matching、一致性蒸馏、DiT 这些过去一年已经被反复验证过的零件。但把这些零件按对了顺序拼起来,并且专门为时间戳条件做了工程优化,做出来的东西就是比同行实用一截。
这种「组合式创新」恰恰是开源社区目前最擅长的事情——闭源大厂会跑得更快,但开源派的优势是把工具链铺到每一个开发者的手里。从这个角度看,今天能在 GitHub 上 clone 下来跑一遍 4 步生成 demo 的开发者,可能比一年前在某商业平台上点「试用」按钮的人,离真正的生产环境更近。


