理想马赫 Mind-Pro 上车 L9,车端大模型终于不再是噱头

理想在 Livis Day 发布多模态大模型马赫 Mind-Pro,全面落地 L9 Livis 车载智能,IFEval、AIME26 等核心评测跻身行业第一梯队,所有推理在车端本地完成。
理想马赫 Mind-Pro 上车 L9,车端大模型终于不再是噱头
6 月 15 日下午,理想在 Livis Day 汽车软件与人工智能发布会上甩出了一张关键牌——多模态大模型马赫 Mind-Pro 已经全面落地 L9 Livis 车载智能。这是继 2023 年 Mind GPT、2025 年马赫 VLA 之后,理想自研大模型矩阵中分量最重的一次更新,也是国内车企第一次把一个综合能力对标头部通用大模型的多模态模型,真正塞进量产车里跑起来。
说"塞进去跑起来",是因为这次发布会上理想给出的不是 PPT,而是一组评测成绩和工程参数。

一、不是车机助手,是真·通用大模型挂在车上
过去两年,但凡车企讲"大模型上车",多数情况指的是接了云端 API 或者塞了个十几 B 的小模型做意图识别,本质还是更聪明的语音助手。马赫 Mind-Pro 这次给出的成绩单不太一样:
- IFEval 指令跟随:跻身第一梯队
- LongBench-v2 超长文本理解:第一梯队
- AIME26 高阶数学推理:第一梯队
- BFCL-v4 工具调用:第一梯队
这四项基本覆盖了一个通用大模型的核心能力面——能听懂复杂指令、能处理长上下文、能做硬核推理、能调外部工具。能在 AIME26 这种 2026 年新版数学奥赛题集上挤进第一梯队的模型,目前国内一只手数得过来,理想把它装进了车里。
更关键的是另一组数据:Token 生成速度、任务完成质量、Token 成本、端到端响应时延全部满足量产要求。这不是技术指标,是商业指标。一个模型只要跑在车端,就要面对算力上限、续航焦虑和延迟容忍度三座大山。Mind-Pro 能交付到量产线,说明这套模型 + 推理引擎 + 车规 SoC 的组合已经被打磨到能跑顺。
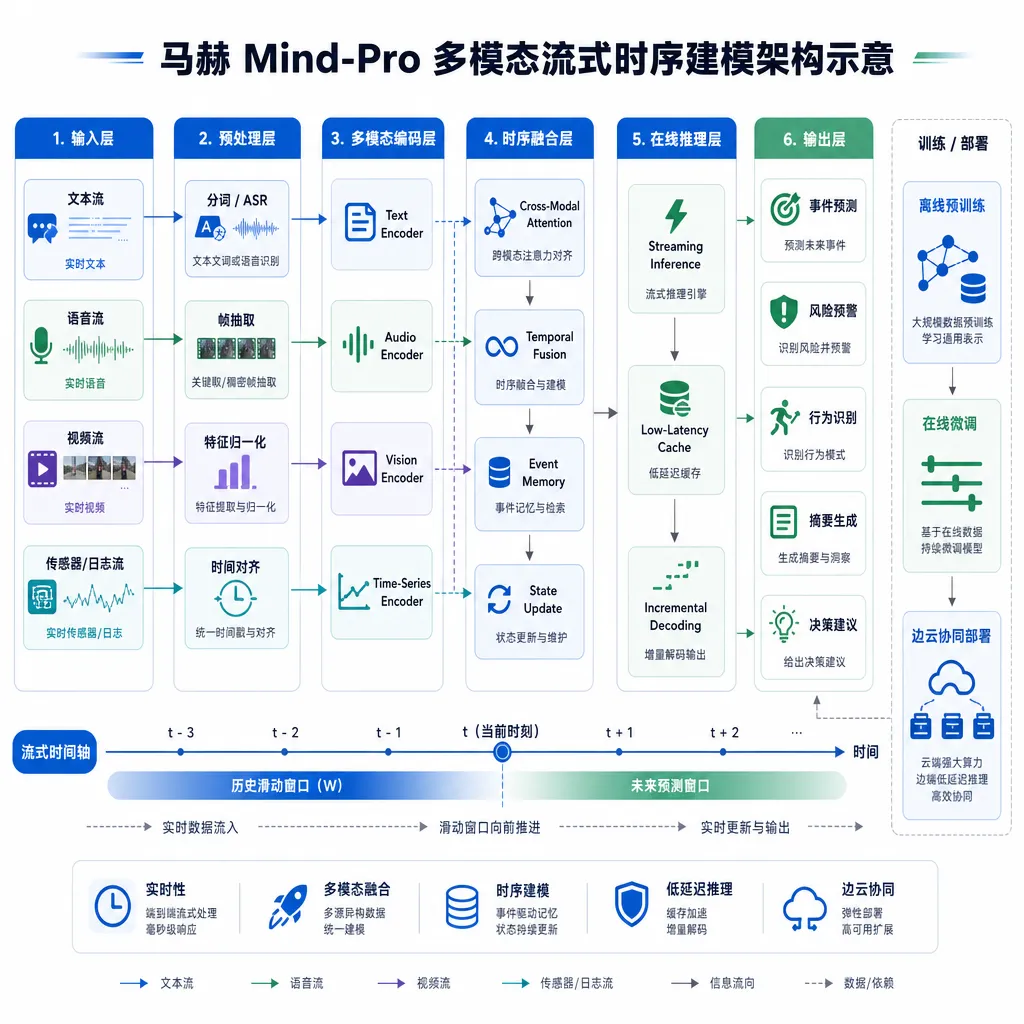
二、多模态流式时序建模:让模型连续看世界
比能力榜单更值得说的,是马赫 Mind-Pro 的架构选择——多模态流式时序建模(Multimodal Streaming Temporal Modeling)。
传统多模态模型处理视频或动态场景,常规打法是抽帧,每隔几百毫秒喂一张图给模型,模型把每一帧当独立输入处理。这种做法对短视频理解够用,但车端场景完全不行——你不可能让模型每 500ms 才"看一眼"路况,更不可能让它在两帧之间漏掉一个突然冲出来的小孩。
流式时序建模的思路是把摄像头、麦克风、车辆 CAN 总线等信号当作连续时序信号来建模,模型在时间维度上是连续感知的,而不是一帧一帧切片。这有点像把模型从"看相册"升级到"看直播",并且在直播过程中可以随时基于历史上下文做因果推理。
这一步走通之后,理想官方描述的能力——Always-on 全天候主动感知、连续理解动态物理世界、因果推理、自主决策——才有可能落地。否则你的车机助手只能被动响应,永远等不到"快看后面那辆车要变道"这种主动提醒。
三、行为特化训练:模型直接输出动作
Mind-Pro 还有一个偏工程但非常重要的设计:大量车载专属的行为特化训练,能够直接输出动作,实时调用车辆硬件。
这里要稍微展开一下。当前主流大模型调用工具有两种主流范式:
- Function Calling:模型输出一段 JSON,交给中间件去解析、路由、执行
- Agent 框架:模型输出自然语言,框架层做意图识别后再触发动作
两种方案在 Web 服务里都跑得动,但在车端有个致命问题——延迟。一句"打开主驾座椅加热并调到三档",如果先要走一遍 JSON 解析、再走一遍硬件 RPC,端到端时延很容易破秒。Mind-Pro 的思路是把车控动作作为一种"原生输出模态"训练进模型,模型推理过程中可以直接发出硬件指令,省掉中间一整层。
这种打法的代价是模型耦合度高,换硬件就要重训。但反过来看,理想本来就是从芯片(马赫 M100)到操作系统到模型全栈自研,耦合不是问题,反而是优势。
四、本地推理 + 数据不上传,把隐私牌打死
发布会另一个被反复强调的点是:所有能力——Always-on 主动感知、人车交互、自主控车、多模态问答——全部在车端本地完成,数据完全不上传。
这一条对 To C 来说是隐私安全卖点,对 To 工程来说则是真本事。要让一个能在 AIME26 拿到一线成绩的模型完全跑在车端 SoC 上,要么模型本身做了极致蒸馏和稀疏化,要么底层推理引擎做了相当极致的优化。理想此前自研过 LisaRT-LLM 推理引擎,这次 Mind-Pro 大概率沿用了相关基础设施,并针对马赫 M100 做了专项 kernel 优化。
车端本地推理的好处是显而易见的:
- 隐私:座舱里说的话、看到的画面不出车
- 可用性:没有信号的隧道、地下车库照样工作
- 时延:省掉网络往返,端到端响应可以压到几百毫秒级别
- 成本:不烧云端 Token,理想自己也省钱
但代价也很真实——模型规模、上下文长度、并发请求数都受车端硬件天花板限制。Mind-Pro 能在这个约束下打进第一梯队,工程能力是硬通货。
五、跟竞品比,理想这一手赢在哪儿
横向对比一下国内车企的大模型布局:
| 玩家 | 模型路线 | 部署方式 | 多模态能力 | |------|---------|---------|----------| | 理想 Mind-Pro | 自研多模态 | 车端本地 | 流式时序,连续感知 | | 蔚来 NOMI GPT | 自研 + 云端 | 云端为主 | 以语音为主 | | 小鹏 XGPT | 自研基座 | 云端 | 视觉 + 语音 | | 华为盘古车机 | 盘古子模型 | 云端 + 端侧 | 多模态 | | 比亚迪璇玑 | 多家合作 | 云端 | 语音为主 |
理想这次最锋利的差异点有三个:全本地推理、流式多模态、原生车控输出。前两个是技术路线选择,第三个是垂直整合的产物。这套组合拳打出来,至少在"大模型作为座舱底层 OS"这个维度上,理想跑在了前面。
当然,Mind-Pro 仍然只是座舱大脑,理想自动驾驶那条线还是另一套模型——马赫 VLA(Vision-Language-Action),围绕 3D 空间理解、闭环强化学习做系统级升级。两者一座舱一智驾,构成了理想 AI 战略的两条腿。
六、对开发者意味着什么
直接说几个判断:
-
车端推理引擎会变成下一个红海。Mind-Pro 能跑通本地推理,意味着 7B~14B 级别的多模态模型在车规芯片上已经具备量产可行性。明年这个时候,车端 LLM Runtime 会出现一批新玩家。
-
车机生态接口会被重构。当模型可以"直接输出动作",传统的车机 App 调用方式(Intent、SDK、深链)很可能被原生大模型协议取代。理想没说会不会开放接口,但如果开放,将是一个新机会。
-
多模态评测标准也会跟着变。IFEval、BFCL 这些指标过去主要在云端模型场景使用,现在被理想拿来标定车端能力,说明车端模型评测正在被通用 NLP 评测体系吸收。
-
隐私 + 本地推理会成为合规默认项。数据不出车的设定一旦被头部车企采用,监管层很可能跟进。后面再做云端方案的车企,合规成本会更高。
七、小结
马赫 Mind-Pro 不是一个新的车机助手,它是把通用大模型的能力曲线砸进了车端硬件的天花板里,并且砸出了一条新的路径。在国内车企里,理想是第一个把多模态大模型做到"能力评测在线、商业指标可量产、推理过程在车端"这三件事同时成立的玩家。
L9 Livis 车主大概率会是第一批吃到红利的人,但这次发布会的意义不止于一款车——它给整个行业划了一条新基准线:车上的大模型,从今天起,要按通用大模型的标准来评了。
参考来源
- 理想:马赫 Mind-Pro 模型已全面落地赋能 L9 Livis 车载智能 - IT之家:Livis Day 发布会现场报道,含模型评测数据与商业化指标


