OpenAI 把推理成本砍半,API 降价还有多少空间?

OpenAI 工程师内部透露,通过一系列系统底层优化将模型推理成本压低逾 50%,节省下来的算力既可用于降价,也可用于放宽用户额度。在国内厂商把 API 价格打到地板的当下,这次效率提升给了 OpenAI 重新组织定价策略的底气。
OpenAI 在算力账上又抠出了一半
据 The Information 报道,OpenAI 工程师在内部透露,公司最近通过一系列系统底层优化,把 AI 模型的推理成本压低了 50% 以上。注意,这里说的不是训练成本,而是模型在线上响应请求时实际烧掉的那部分 GPU 时间——也就是 OpenAI 每天最烧钱、也最直接决定毛利的环节。
更关键的一点:这次降本主要来自现有服务器资源利用率的提升,而不是靠堆更多新卡。换句话说,同样一批 H100/H200,跑出来的有效 token 数翻倍了。节省下来的预算,要么用来降 API 价格,要么用来给用户放宽速率限制和上下文额度。
这个消息扔出来的时机非常微妙。过去半年,国内 DeepSeek、通义、豆包、文心一系把 API 价格打到了让美国同行很难看的地步,而 OpenAI 和 Anthropic 在企业端也开始遭遇"客户跑去用便宜模型"的真实压力——前不久《华尔街日报》刚刚写过这件事。OpenAI 这时候放出"推理成本砍半"的风声,不像是单纯的工程炫技,更像是为接下来的某轮降价做铺垫。
50% 是怎么省出来的
报道没有披露太多技术细节,但结合 OpenAI 过去一年的公开动作和业内的常规手段,大致可以拼出这个 50% 的来源结构。
第一块,是 KV Cache 的精细化管理。 大模型推理最贵的部分不是计算,而是显存带宽——每生成一个 token,都要把巨大的 KV Cache 在显存和计算单元之间搬来搬去。OpenAI 此前已经把 prompt caching 做成了对外特性(命中缓存的输入 token 价格只有 1/2 到 1/4),而内部这套缓存系统显然还在持续优化。把高频前缀、系统提示词、长文档的中间状态以更激进的方式跨请求复用,是省钱的第一大头。
第二块,是更聪明的批处理(continuous batching)和投机解码(speculative decoding)。 传统 batching 一旦凑齐一批就锁死,短请求要等长请求做完,GPU 利用率掉得很厉害。continuous batching 允许请求随时进出 batch,配合 PagedAttention 这类显存管理方案,能把 GPU 占用率从 40% 多拉到 70%-80%。投机解码则用小模型先"猜"几个 token,大模型一次性验证,相当于把串行解码部分变成并行验证,对长输出场景立竿见影。
第三块,是 MoE 路由和 expert 并行的优化。 GPT-4 系列普遍被认为是 MoE 架构,激活参数远小于总参数。MoE 在推理时最大的痛点是 expert 之间负载不均——某些 expert 被疯抢,另一些闲着。OpenAI 在调度层做的工作,很可能涉及到 expert 的动态迁移、热点专家的复制、以及更激进的量化(FP8 甚至更低)。
第四块,是混合精度和量化下沉。 把模型权重和 KV Cache 从 BF16 压到 FP8,理论上能把显存占用和带宽需求各砍一半,而精度损失在大多数任务上几乎察觉不到。这件事 NVIDIA H100 之后的硬件原生支持,OpenAI 没理由不用。
这几块加起来,做到整体推理成本下降 50%,并不是一个夸张的数字。Anthropic、Google 这边其实也都在做类似的事情,只是 OpenAI 这次主动放风出来。
为什么是现在放出这个消息
回到商业层面。OpenAI 的处境其实比外界想象的要紧。
一方面,企业客户的 token 消耗量在涨,但 ARPU 没有同步涨——因为大家都学会了用 prompt caching、batch API、以及把简单任务路由到便宜小模型这套组合拳。Sam Altman 自己也承认 ChatGPT Pro 订阅是亏钱的,企业 API 这边的毛利率也并不像想象中那么舒服。
另一方面,开发者的迁移成本越来越低。OpenAI 兼容的 API 格式已经变成事实标准,DeepSeek、Qwen、Claude 全都提供 OpenAI 格式的接口,开发者切换模型基本就是改个 base_url 和 model 名。再加上现在国内一堆聚合平台(比如 OpenAI Hub 这类一个 Key 调所有主流模型的服务)让"按任务挑模型"成本几乎为零,OpenAI 守不住"开发者只能用我家"的护城河。
所以这次推理成本减半,更可能的剧本是:
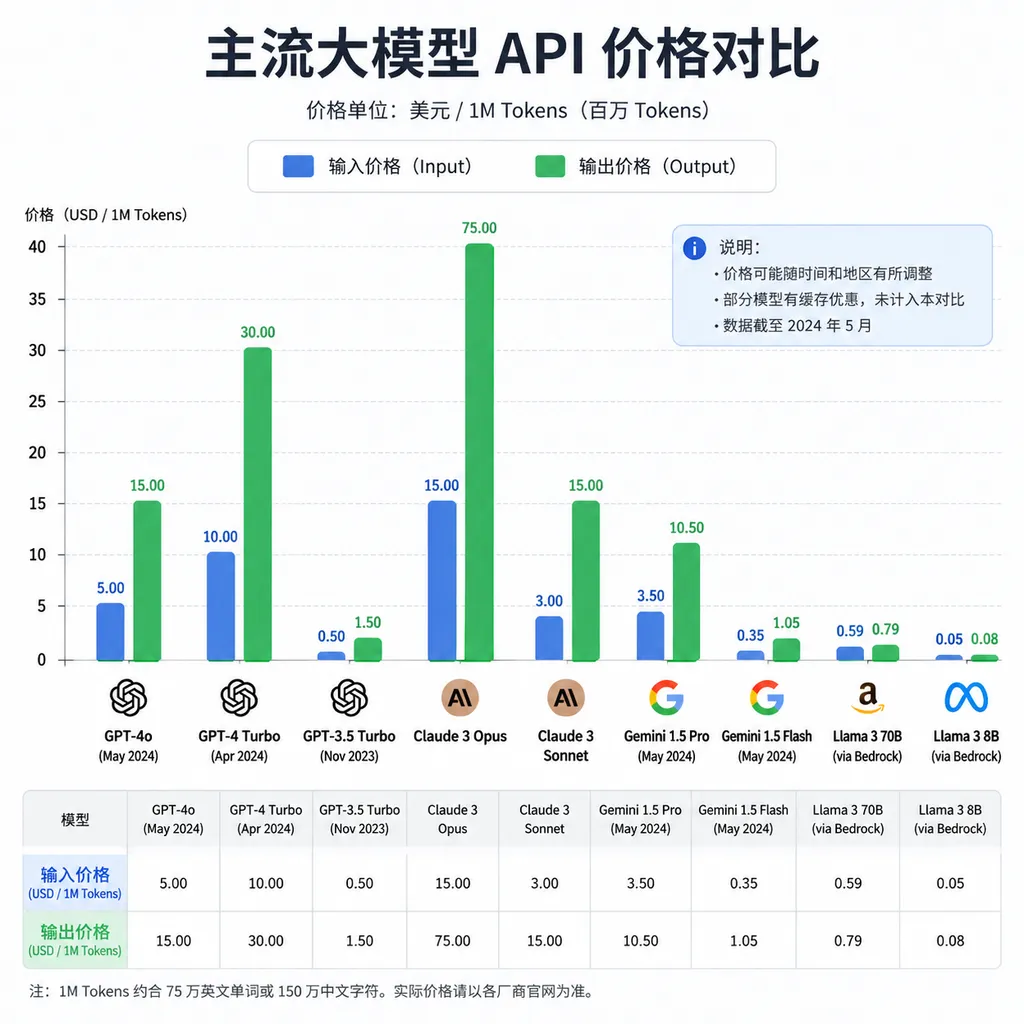
- GPT-5 系列 mini/nano 档位再降一轮价,对标 DeepSeek-V3 和 Gemini Flash;
- batch API 折扣加深,从现在的 50% off 可能进一步压到 60%-70% off;
- 企业版的 rate limit 和上下文窗口放宽,用容量换续约;
- 更激进的 prompt caching 默认开启,让长 system prompt 场景的实际单价继续下探。
国内开发者怎么看这件事
从国内开发者的视角,这件事的影响有两层。
第一层是显性的:如果 OpenAI 真的再降一轮价,对国内做出海应用的团队是直接利好。GPT-4o、GPT-5 这一档模型的能力上限在某些场景(特别是复杂 agent、代码生成、多模态理解)仍然有优势,价格再降一档,意味着原本因为成本不敢上量的产品可以重新算账。
第二层是隐性的:价格战会进一步把"API 即商业模式"这件事推向边缘。虎嗅那篇"让 AI 大模型的价格战来得再猛烈些吧"里有个挺尖锐的观点——API 收费可能本身就不应该是大模型的主营业务,就像 iOS 和 Android 不靠 SDK 收费一样。这个判断在 2024 年还显得激进,到 2026 年回看,越来越像现实。OpenAI 真正赚钱的业务是 ChatGPT 订阅、企业部署、以及未来的硬件和 agent 平台分成,API 更像是开发者获取入口。
这意味着对开发者来说,未来几年 API 价格只会更便宜,不会更贵。模型能力的差异会继续存在,但单 token 的价差会持续收敛。理性的做法是:
- 不要把架构绑死在某一家模型上,保留快速切换的能力;
- 用聚合平台(OpenAI Hub 这类服务,国内直连,OpenAI 格式兼容,一个 Key 同时调 GPT、Claude、Gemini、DeepSeek)降低多模型并行测试的工程成本;
- 把任务做分级路由——简单任务交给便宜模型,复杂推理才上旗舰,这套架构在价格继续下探的环境下收益会更高。
还有一个值得关注的副作用
推理成本减半,对 NVIDIA 来说不算好消息。报道里有一句很微妙的话:"运行其 AI 系统所需的英伟达芯片更少。"
过去两年市场对 AI 算力需求的预期,建立在"模型越来越大、用户越来越多、所以 GPU 永远不够卖"这个假设上。但如果头部厂商通过软件优化每 18 个月就能把单位推理成本砍半(类似 AI 时代的摩尔定律,只不过是在软件层),那 GPU 的边际需求增长曲线就不会像之前预测的那么陡。
当然,Jevons 悖论也可能起作用——成本降了,需求反而被打开,总算力消耗继续上涨。但至少在短期,OpenAI 这种主动透露"我们用更少的卡做更多的事"的姿态,是在向资本市场和供应链传递一个新信号:算力效率本身就是一种竞争力,而不是单纯的卡数竞赛。
小结
推理成本砍半这件事,技术上不算革命,但商业上是一个清晰的拐点。它告诉市场两件事:
- OpenAI 还有相当大的降价弹药,价格战的下一轮如果开打,它不会像外界以为的那样被动;
- AI API 的单价下行通道,远没有到底。
对开发者来说,与其纠结哪家便宜,不如把架构和工作流先准备好——能随时切换、能按任务路由、能利用各家的 batch 和 caching 折扣。这一波价格战的最大受益者,本来就应该是构建在模型之上的应用层。
参考来源
- 消息称 OpenAI 通过系统底层优化,将 AI 模型推理成本减半 - IT之家 — The Information 报道的中文转述,包含 OpenAI 工程师内部透露的关键细节
- Open AI 的崩溃结局推演 - 知乎专栏 — 对 OpenAI 商业模式和长期竞争格局的一种推演视角,可作为对照阅读