Meta 开源 Brain2Qwerty v2:脑信号直出整句,最高词准确率 78%

Meta 把非侵入式脑机接口推进了一大步——v2 跳过字母直接解码句子,最佳被试单词准确率冲到 78%,代码和数据集已全部开源。
Meta 把它去年那个能"读脑打字"的研究又往前推了一截。这次发布的 Brain2Qwerty v2 不再逐字母拼写,而是直接从一段连续的脑磁图(MEG)信号里解出完整句子,最好的被试单词准确率达到 78%,平均也有 61%。代码、论文、西班牙语 BCBL 数据集一并扔上了 GitHub 和 Hugging Face,Nature Neuroscience 同步刊出。
这件事的分量在哪?一句话:非侵入式脑机接口第一次在"自然句子解码"这个任务上,做到了能用的程度。
从"拼字母"到"出句子",跨过去一道坎
回顾一下去年的 v1。当时 Meta 的做法是这样的:35 个健康志愿者坐在 MEG 扫描仪里打字,模型学着把脑信号映射成键盘按键,再拼回字母。MEG 路线最好成绩字符错误率(CER)19%,平均 32%;用更便宜但信噪比差很多的 EEG(脑电图),平均 CER 直接掉到 67%。
这个成绩当时已经够发论文,但离"能用"差得远。32% 的字符错误率意味着每三个字符就错一个,读起来基本是乱码。更关键的是,逐字母解码是个低效的范式——人脑里浮现一个句子的时候,并不是先想第一个字母再想第二个字母,而是整句概念几乎同步涌出。把这个并行的过程强行拆成串行打字,等于和大脑自己的工作方式拧着干。
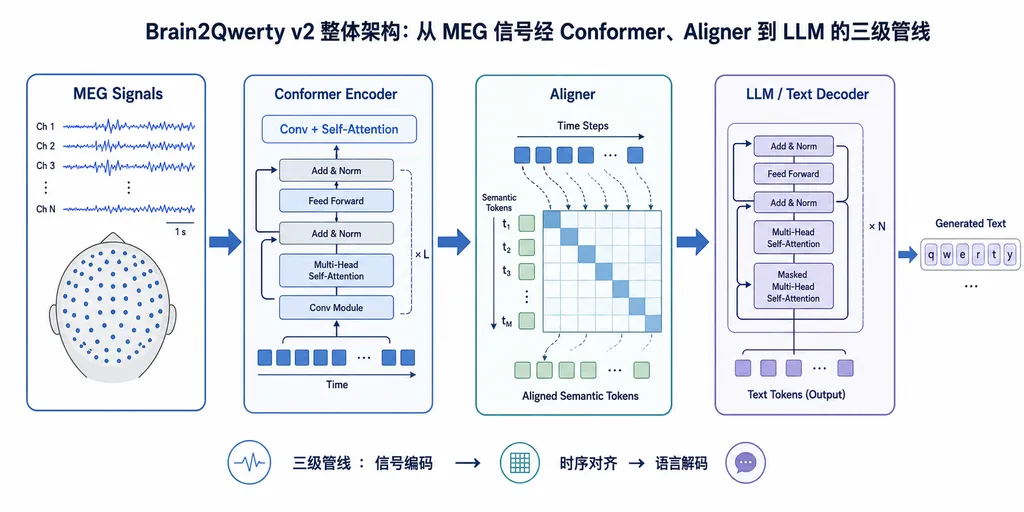
v2 的做法换了思路。整个管线变成三段:
- Conformer 编码器:吃进连续 MEG 信号,提取时序特征。Conformer 这个架构原本是语音识别里用的,处理"连续信号 → 离散符号"的活儿是老本行。
- Aligner 对齐器:把脑信号片段和字符/词的边界对齐。这一步取代了 v1 里强制要求 MEG 段与按键时间戳对齐的硬约束,让模型能处理更自然的连续输入。
- LLM 解码器:在词和句子层面做最后的语言建模和纠错。
三个模块联合训练,分别在字母、词、句子三个粒度上拟合。再加上每个被试的训练数据量扩大了 10 倍,模型从"逐字符蹦"进化到了"整句出"。
论文里给的例子挺直观:有个被试输入了 ek benefucui syoera kis ruesgis——明显手滑了——但 LLM 模块根据脑信号上下文,把它纠回了原意 el beneficio supera los riegos(西班牙语:"收益超过风险")。模型不仅在解码大脑的意图,还顺手修了使用者的笔误。 这一点很有意思,意味着语言模型已经在脑信号的高层语义和具体按键之间起到了桥梁作用,而不只是被动转录。
和侵入式 BCI 比,差距还有多少
这是绕不开的对比。Neuralink、Synchron 这类侵入式方案在 ALS 患者身上能做到 90% 以上的单词准确率,最近 UC Davis 那篇研究甚至冲到 97%。78% 看起来还差一截。
但要把代价摆出来一起算:
| 路线 | 准确率(最佳) | 安装方式 | 长期稳定性 | |------|-----------|------|--------| | 侵入式(Utah 阵列、Neuralink) | 90%+ | 开颅手术,植入电极 | 电极会被胶质细胞包裹,信号衰减 | | 非侵入式 MEG(Brain2Qwerty v2) | 78% | 戴个头盔,无创 | 不存在生物排异问题 | | 非侵入式 EEG | 30-40%(运动想象类任务) | 头皮电极,无创 | 信噪比差,受限多 |
换句话说,Brain2Qwerty 把非侵入式方案从"勉强能识别几个意念命令"推到了"能解码自由句子"的层级,缩小了和侵入式之间那条看起来没法跨越的鸿沟。对于不愿意或不适合做开颅手术的患者来说,多了一个真正可行的方向。
当然,MEG 这边的硬伤是设备。现在用的脑磁图机是一整套低温超导磁强计,要液氦冷却,机器有半个房间那么大,单台动辄上百万美元,只能在屏蔽磁干扰的特殊房间里用。这种"非侵入"指的是没破皮,不是真的方便。
Meta 自己也提到了下一步:OPM(光泵磁强计)。这是不需要液氦的新型 MEG 传感器,能做成可穿戴形态,最近几年学术界进展不慢。如果 OPM 的灵敏度跟得上传统超导方案,Brain2Qwerty 这套算法就能从实验室搬出来。这条路如果走通,BCI 的形态可能就从"开颅植入"或者"躺进大铁罐"变成"戴个头盔"。
技术细节里值得拎出来说的几点
通读论文和代码仓库,有几个点开发者可能会感兴趣。
1. 训练数据是个大头
v2 之所以效果跳跃,很大程度归因于"每被试 10 倍数据"。这暴露了 BCI 一个老问题:脑信号的个体差异极大,跨被试泛化基本不能用,每个人都得单独采数据、单独训练。每个被试采几十小时的 MEG 数据,成本不低。
Meta 这次开源的西班牙语 BCBL 数据集(托管在 Hugging Face 上,由巴斯克认知、脑与语言中心采集)算是给社区一个起点。但要做英语、中文或其他语种的版本,还得各自从零开始采。
2. Conformer + Aligner 的组合不是新东西
这套架构在端到端语音识别里已经用得很熟了。Meta 这次的贡献更多在于证明了 MEG 信号可以用语音 ASR 的范式来处理——既然 MEG 是一段连续时序信号,目标是连续符号序列,那么把它当成"脑磁版的语音"来做,思路就通了。
这对其他 BCI 研究是个启发:与其重新发明轮子,不如把语音、视频领域成熟的序列建模工具直接迁移过来。
3. LLM 那一层用的不是大模型
从开源代码看,最后做语言纠错的 LLM 规模并不大,主要起 n-gram 加强版的作用,做句子级的统计纠错。这意味着如果换上一个真正强力的 LLM(比如 Llama 系列),理论上还有不小的提升空间。这也是社区接下来很可能尝试的方向。
4. 离实时还有距离
Meta 自己在论文里坦白了:现在的模型不是实时跑的,Transformer 和 LLM 都在句子级别工作,必须等一整句信号采完才能解码。对临床场景来说,这意味着用户没法像打字一样即时看到反馈,体验会很别扭。把整套架构改成流式(streaming)解码是个明显的待办项。
这事对开发者意味着什么
如果你是做 BCI、神经科学、医疗 AI 方向的,这次开源相当于把一套 SOTA 级别的基线工具包直接交到你手上:
git clone https://github.com/facebookresearch/brain2qwerty
cd brain2qwerty
pip install -e .
数据集可以直接从 Hugging Face 拉:
from datasets import load_dataset
ds = load_dataset(\"bcbl190626/SpanishBCBL\")
如果你不在 BCI 圈子,但关注多模态信号到自然语言的解码这条线,Brain2Qwerty 给的信号也很清楚:把生物信号(脑磁、肌电、眼动)和 LLM 拼起来做端到端解码,正在变成一个范式。 类似的思路会渐渐渗透到手语翻译、亚发声识别、可穿戴交互这些方向。
一点判断
Meta 这两年在 AI 上的策略挺有意思:主流大模型方向打不过 OpenAI 和 Anthropic,就在边缘但够硬核的地方开源刷影响力。Brain2Qwerty 不会直接帮 Meta 卖广告或者推 Llama,但它是那种"摆在那里就让人记住"的研究。从动机上说,Meta 一直在押注下一代人机交互——Ray-Ban Meta 眼镜、Orion AR、肌电腕带——脑机接口是这条线的尽头。哪怕现在离消费级还差十年,也得把基础打着。
对 BCI 这个领域来说,Brain2Qwerty v2 不是范式革命,但它第一次让非侵入式路线在"自由句子解码"这个最关键的指标上拿出了像样的成绩。再加上代码、数据全开源,社区接下来一年应该会有不少跟进工作。值得盯着看。
参考来源
- facebookresearch/brain2qwerty (GitHub) — Brain2Qwerty v2 官方开源代码仓库,含模型、训练脚本和评估工具
- SpanishBCBL 数据集 (Hugging Face) — Meta 与 BCBL 合作采集的西班牙语 MEG 打字数据集
- 《Brain2Qwerty:从脑波到文字》论文解读 (知乎) — 国内研究者对 v1 论文的中文技术解读,便于理解架构演进背景


