国产 LoopWM 登顶 HF:让世界模型学会"多想几轮"

中国初创脸谱心智(FaceMind)提出 Looped World Model,用参数共享的循环 Transformer 在潜空间反复迭代,声称在约 1B 参数量级实现最高 100× 参数效率,论文登顶 Hugging Face Daily Papers,获 Nvidia 点赞、周鸿祎陆奇加持。
一家中国初创,把世界模型的 scaling 轴又往前推了一格
7 月 1 日凌晨,Hugging Face Daily Papers 榜首挂着一篇来自中国团队的论文:《Looped World Models》。作者是一家叫"脸谱心智"(FaceMind)的初创公司,投资方名单里能看到周鸿祎和陆奇的名字,Nvidia 官方账号也在 X 上转发点了赞。
对世界模型这条路线来说,这不是那种"又刷新了一个榜"的常规更新。它提出的东西更本质一点:给世界建模加了一条新的 scaling 轴——迭代潜深度(iterative latent depth)。翻译成人话就是,模型不用一味做大,也不用喂更多数据,而是学会在关键时刻"多想几轮"。
传统世界模型的老毛病:一锤子买卖
要理解 LoopWM 在解决什么问题,得先看清传统世界模型的结构性尴尬。
世界模型的核心任务是模拟环境演化——给一个当前状态和动作,预测下一时刻会发生什么。听上去和语言模型的 next token prediction 很像,但难度完全不是一个量级:语言模型只需要预测一个 token,世界模型要预测的是一整套物理规律在时间维度上的展开。
过去的做法基本是两条路:要么把模型堆到更大,要么把训练数据加到更多。但世界模型面临一个特殊的矛盾——长程模拟需要深计算,深模型又贵又容易累积误差。你把 Transformer 层数加到 100 层,一次前向确实更精细,但每步 rollout 都要跑这 100 层,几百步之后延迟直接爆炸,而且误差会在自回归里被层层放大。
更别扭的是,传统架构对每个状态转移都分配固定计算量。不管这一步是"苹果从桌子上掉下来"这种简单物理,还是"多物体连锁碰撞"这种复杂交互,用的都是同样深的网络。这显然不符合真实世界的规律——环境演化本来就是有难有易的。
LoopWM 的思路:让同一组参数反复作用
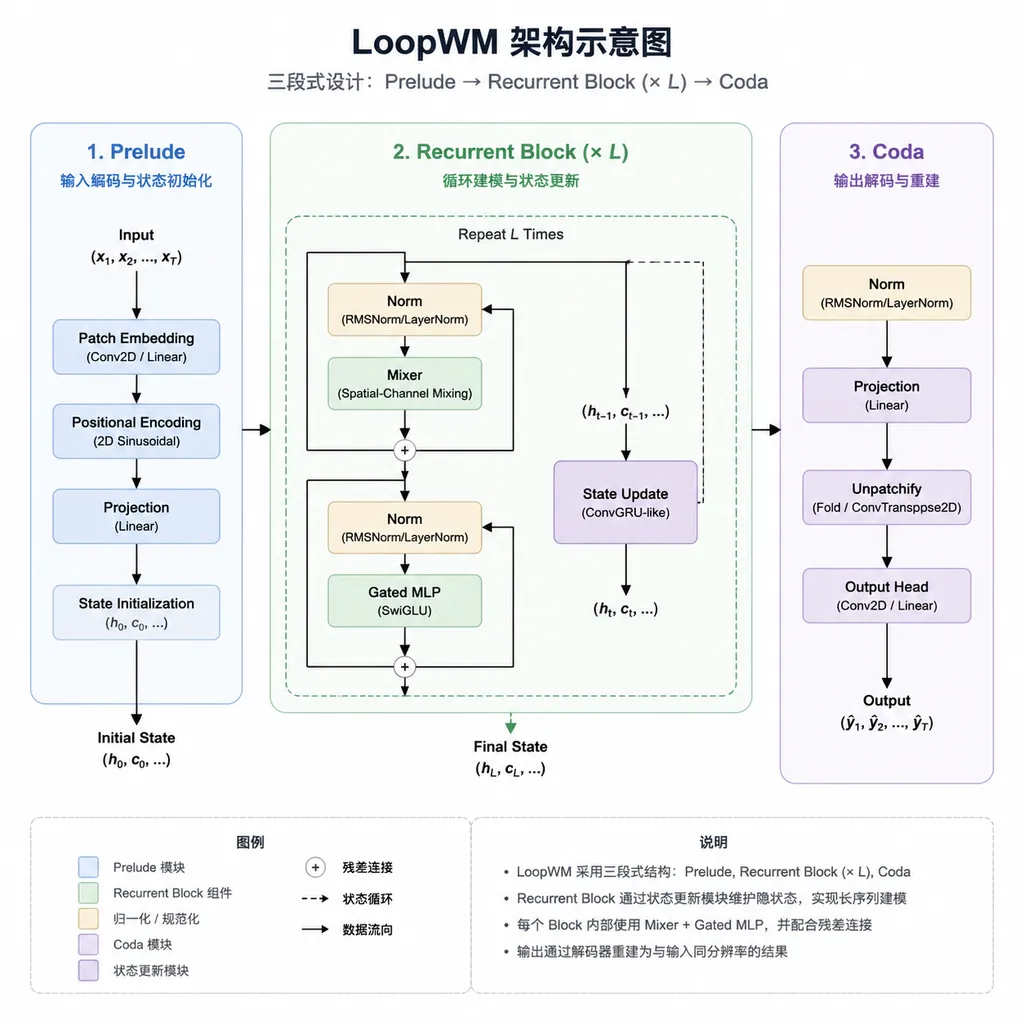
脸谱心智的解法,是把 looped transformer 首次带进了世界建模。整体架构由四部分组成:观测编码器、动作嵌入器、循环动力学核心(Looped Dynamics Core)、预测头。前后三块都是常规操作,真正关键的是中间。
循环动力学核心又被拆成三段:
- Prelude:把前一时刻状态、当前观测和当前动作先整理成适合推理的初始表示
- Recurrent Block:核心部分,一组共享参数的 Transformer 块,对潜状态反复迭代更新
- Coda:循环结束后,把最终潜表示整理成预测头能解码的输出
这套设计里最反直觉的一点是 Recurrent Block 的参数共享。也就是说,如果你让模型迭代 8 次,它并不是在跑 8 层不同的 Transformer,而是同一组权重被反复调用了 8 次。参数量没变,但等效计算深度上去了。
这件事听上去像是工程小技巧,但脸谱心智想说的是:真实环境的演化本来就是某种稳定规律被持续施加的结果,共享更新算子反复作用于潜状态,让模型的计算图和环境动力学的迭代结构更贴近了。这是一种"架构层面的先验",不是纯粹的算力堆叠。
两个关键设计:Deferred Decoding 和 Early Exit
光有循环还不够。在长程 rollout 里,两个配套设计才是让这套东西真正跑起来的关键。
Deferred Decoding(延迟解码):多步 rollout 时,模型不再每走一步就急着把潜状态还原成显式观测,而是在潜空间里连续推演,等到真正需要输出的时候再解码。逻辑很朴素——每步都翻译回观测空间的话,计算会被频繁打断,长期结构建模也更难。论文里的实验显示,rollout 步数越长,Deferred Decoding 带来的收益越明显。
Early Exit(提前退出):这是让模型学会"按需思考"的关键。一个轻量门控机制会在每轮迭代后判断——当前潜状态是不是已经收敛了?如果这一步转移足够简单,模型就早点跳出循环;如果是复杂交互,就多迭代几轮。这套自适应计算机制让 LoopWM 在推理时的计算开销真正做到"该花的花,能省的省"。
把这四件事拼在一起——共享参数、迭代精炼、稳定循环、自适应计算——LoopWM 就成了一套完整方案。
实验结果:1B 参数打赢闭源大模型
评测环节,脸谱心智把 LoopWM 放到了 ScienceWorld 和 AlfWorld 这两个经典的 embodied 任务环境里,对手包括 Claude-opus-4-6-max、Qwen-3.5-flash、Gemini-3-flash-preview-thinking 等一线闭源模型。
ScienceWorld 上,约 1B 参数的 LoopWM 拿到:
- EM:68.4%(对比 Claude-opus-4-6-max 的 47.2%)
- Token F1:85.3%(对比 72.8%)
- BLEU-4:80.7%
- Entity:83.9%
更夸张的是 Lifespan 这个子任务,论文报告 LoopWM 把得分从 0% 干到了 100%。这不是那种边角料改进,说明循环潜深度在某些长程推理场景里,可能确实带来了结构性的能力跃迁——之前的模型不是做得差一点,而是根本不会做。
AlfWorld 上:EM 51.6%、Token F1 80.4%、BLEU-4 71.6%,BLEU 指标特别突出。
所有这些结果的前提是——约 1B 参数。这就是那句让人眼前一亮的"最高 100× 参数效率"的来源。
值得盯着的不是"100× 参数效率",是那条新 scaling 轴
看完摘要很容易被 100× 这个数字带偏,但我觉得这篇论文真正值得行业认真消化的,是它把"迭代潜深度"提出来当作一条和参数规模、训练数据正交的 scaling 维度。
过去几年,从 GPT-3 到现在,行业对 scaling 的想象基本被压缩成两件事:模型多大、数据多少。OpenAI 的 o 系列后来加了第三条——推理时计算(test-time compute),但那更多是在输出层面的"多想几步"。LoopWM 把这个思路进一步下沉到了架构内部:同一个参数化的算子,通过反复作用于潜状态本身,来提升模拟质量。
这条路对资源受限部署尤其有价值。它提供的不是"更贵的能力上限",而是"更聪明的计算分配方式"——简单场景省算力,复杂场景多花几轮,同样的参数预算榨出更多能力。对具身智能、机器人、自动驾驶这类既要长程规划又要低延迟的场景来说,这个方向的意义远比又一个通用大模型 SOTA 重要。
当然也要冷静一点:循环模型的美妙在于能反复推,危险也在于能反复推。只要状态更新稍微失控,隐藏状态就会在多轮迭代里迅速爆炸。这也是为什么 looped transformer 在 NLP 领域早期尝试过但一直没大规模铺开的原因。脸谱心智在论文里花了不小篇幅讲怎么保证循环稳定性——这套稳定性能不能在更大参数量级和更长 rollout 下继续成立,还需要时间来验证。
一家不太一样的中国初创
脸谱心智这家公司之前在国内 AI 圈的声量并不大,但两条信息值得注意:
第一,投资方名单——周鸿祎和陆奇都进了。这两位的判断力在国内 AI 投资圈相当值得参考,尤其是陆奇,很少在具身智能/世界模型方向公开站台。
第二,Nvidia 在 X 上转了这篇论文。Nvidia 转论文本身不稀奇,但通常只发那些他们认为在 GPU 部署路径上有工程价值、或者代表某种范式转变的工作。LoopWM 的自适应计算特性对推理效率友好,这可能是被点名的原因之一。
国内做世界模型的团队不算多,做到能被 Hugging Face 榜单和 Nvidia 官方同时认可的更少。这次登顶不是终点,接下来要看的是——这套架构在更大规模、更复杂环境下能不能立得住,以及会不会有其他团队跟进复现。
模型权重和推理接入方面,OpenAI Hub 后续如果 FaceMind 开源了 LoopWM checkpoint,会第一时间加入模型池,一个 Key 就能调用,兼容 OpenAI 格式。世界模型和 LLM 的调用范式差别较大,我们也在准备针对性的接入文档。
参考来源
- Looped World Models — Hugging Face Papers:论文原文页面,Daily Papers 榜首
- World-in-World: World Models in a Closed-Loop World:相关方向工作,讨论闭环环境下的世界模型评测
- 本周最值得关注的论文 TOP10 — Hugging Face Blog:本周热点论文汇总,含世界模型相关工作


