REAP:让生产环境自己造Coding Agent评测集

一篇新论文提出REAP流水线,从真实开发者与Coding Agent的交互日志中自动构建可执行验证的benchmark,直击当前公开评测集与生产环境严重脱节的痛点。
REAP:让生产环境自己造Coding Agent评测集
如果你最近在做 Coding Agent,大概率被同一个问题折磨过:SWE-bench 分数刷得漂亮,客户那边一上真代码就翻车。
一篇刚在 arXiv 挂出、也被搬上 r/MachineLearning 讨论的论文给出了一个新解法——REAP(Relevance and Execution-Audited Pipeline),一条不需要人工标注、直接从生产环境的开发者-Agent 交互中自动提炼评测任务的流水线。作者用它跑出了一个叫 Harvest 的 benchmark,每个任务都源自真实开发者的 prompt,验证方式是拉取生产环境里的 fail-to-pass 测试。
这事儿的意义不在于又多了一个榜单,而在于它把 Coding Agent 的评测方式从「刷公开数据集」往「持续采集生产信号」推了一大步。
现有评测的三条路,各有各的坑
先说清楚 REAP 想解决什么。工业界目前评估 Coding Agent 的效果,主流手段就三种,论文一开头就把它们全否了一遍:
- 在线 A/B 测试:最贴近真实,但周期动辄数周,还得拿真实用户当小白鼠,一次 Agent 行为退化可能就是一批 issue 工单。
- 影子部署(Shadow Deployment):把 Agent 挂在旁边跑但不影响用户,问题是产生的信号跨 run 不可复现——同一个 prompt,代码库状态变了、依赖变了,跑出来的结果没法对齐。
- 公开 benchmark:SWE-bench、LiveCodeBench 这些,问题最明显——语言分布、prompt 风格、代码库结构都跟真实生产不是一回事。SWE-bench 全是 Python 开源仓库的 GitHub issue,可你的团队 monorepo 里可能一半是 TypeScript,一半是 Go,还有一堆内部框架。
这三条路的共同问题是:要么慢,要么脏,要么偏。而 Coding Agent 又是个迭代极快的东西,模型换、prompt 换、工具链换,评测跟不上就是瞎调。
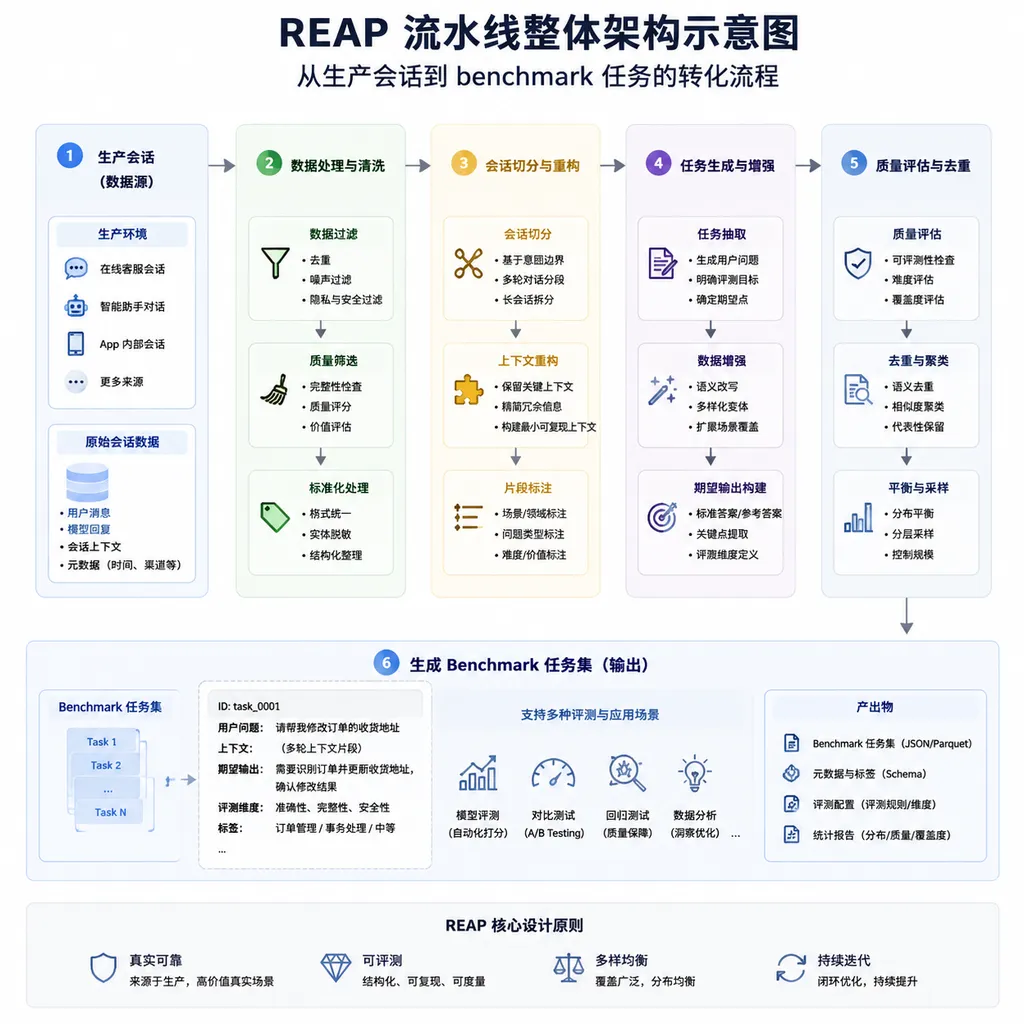
REAP 干了什么
REAP 的核心思路一句话:把生产环境里已经发生过的开发者-Agent 交互,自动转成可复现、可自动判分的评测样本。
每一条样本长这样:
- verbatim prompt:开发者当时原封不动打进去的那句话,包括所有的上下文、模糊表述、拼写错误
- committed diff:这次交互最终被合入的代码变更(就是工业界俗称的 patch/PR)
- fail-to-pass 测试集:变更前失败、变更后通过的那批测试
第三点是关键。fail-to-pass 测试等于给了一个自动化的正确性信号,评测时不需要 LLM-as-a-judge,也不需要人工看 diff。Agent 生成的代码丢进去跑测试,红转绿就是过,简单粗暴。
REAP 的流水线做了几件脏活:
- LLM-based 任务分类:从海量会话里挑出「值得作为评测任务」的那部分——太琐碎的(改个变量名)、目标不明确的、多轮扯了半天没结果的,全过滤掉。
- 测试相关性校验:不是所有跟着 diff 一起改的测试都真的验证了这次改动。REAP 会判断哪些测试是「因为这个改动而由红转绿」,哪些只是顺手改的。
- 多轮稳定性检查:同一个任务跑多次,看结果是否稳定。不稳定的(比如依赖了外部服务、有 flaky test)直接踢掉。
最后剩下的,才进 Harvest。
Monorepo 才是真正的硬骨头
论文里有个细节我觉得特别值得开发者关注——monorepo 场景下 benchmark 必须「持续再策展」。
作者的原话是:monorepo 的 build 基础设施状态是「短暂的(ephemeral)」,代码库天天在变,依赖天天在动,一个月前能跑通的测试,今天可能因为某个内部库升级就跑不通了。这意味着:
你没法像 SWE-bench 那样,冻结一个 commit 当做永恒的评测基线。
REAP 的答案是把 curation 本身做成一条流水线,跟着当前代码库状态持续跑。这背后其实是个挺重要的观念转变——benchmark 不再是一个静态的数据集文件,而是一个跟生产系统同步的动态视图。
从工程角度看,这跟数据仓库里的 view、或者流处理里的 materialized view 是一个逻辑。评测集是被「物化」出来的,源头是生产日志。
为什么现在这事儿开始重要
把镜头拉远一点看。过去半年,Coding Agent 领域的一个明显趋势是:大家逐渐承认单纯堆模型能力已经不够了。
上个月 QCon 北京上,百度文心快码的团队分享过一个观点:Coding Agent 在真实工程中遇到的问题不是「模型不行」,而是「行为不可控、效果不可量化、优化高度依赖少数专家」。他们提出的解法是「Feedback Loop + Benchmark + Agent Engineers」的飞轮——采集真实使用信号,用贴近生产的 benchmark 持续评测,让 Agent 的演进变成日常工程活动。
REAP 其实在做的是同一件事的自动化版本。当你的 Agent 每天服务几万开发者、每天产生几十万次交互时,人工策展 benchmark 完全不现实,只能靠管道化。
这也是为什么我觉得 REAP 的价值远不止「又一篇论文」。它给出的其实是一套Coding Agent 团队应该怎么搭建自己评测基础设施的模板:
- 别再指望公开 benchmark 能告诉你线上表现
- 别再靠工程师拍脑袋挑几个 case 做回归
- 把评测集的生产、验证、更新,全部工程化
几个值得追问的问题
当然,REAP 目前公开的信息里还有几个坑没填清楚,值得后续关注:
第一,隐私和数据合规怎么处理? 生产会话里的 prompt 和 diff 大概率含有专有代码、内部路径、甚至凭证。把这些提炼成 benchmark,即使只在内部用,也涉及不小的数据治理成本。论文没细说他们的脱敏方案。
第二,fail-to-pass 测试的覆盖率天花板在哪里? 不是所有代码变更都伴随测试。UI 改动、配置修改、文档生成,这些高频场景里能被 F2P 测试捕获的比例可能相当有限。REAP 采出来的 Harvest 大概率是「有测试文化的团队 + 后端偏多」的分布,本身也有偏差。
第三,Agent 会不会「过拟合」自己的历史? 如果一个团队用 REAP 采出的 benchmark 反过来训自家的 Agent,很容易陷入自我强化——Agent 学会了自己以前的解法,但这些解法未必是最优的。这里需要额外的多样性保障机制。
第四,跨语言、跨框架的可迁移性。 论文提到 Harvest 覆盖 7 种编程语言,但生产分布是不均匀的。小语种任务的样本量够不够支撑稳定评估,需要看进一步的数据披露。
对开发者的实际启发
就算你不打算复刻 REAP,这篇论文里的几个做法也挺值得抄作业:
- 把 fail-to-pass 测试作为主要评测信号,比 LLM judge 稳、比人工审核快。用在你自己 Coding Agent 的回归测试里,能省掉大量扯皮。
- verbatim prompt 而不是清洗过的 prompt。真实用户不会写完美 prompt,你的 Agent 需要在噪声里工作。评测时保留原始输入,才能测出真实能力。
- 多轮稳定性检查是 benchmark 质量的底线。任何单次通过率高但方差大的任务,都应该被视为不可靠信号。
从更大的图景看,2026 年的 Coding Agent 竞争已经不是「谁家模型更强」,而是「谁家评测和反馈循环转得更快」。REAP 只是这条路上的一个节点,但它把一件原本靠人肉、靠经验、靠玄学的事情,往「可工程化」推进了一大步。
对于正在自建 Coding Agent 的团队来说,与其继续在 SWE-bench 上卷分数,不如认真想想:你的生产环境里,每天有多少高质量的交互数据,正在被白白丢掉。
参考来源
- REAP 论文讨论 - r/MachineLearning:论文原始讨论帖,评论区有不少一线从业者的补充观点
- wagner-group/reap-benchmark - GitHub:注意这是另一个同名项目(对抗性 patch benchmark),本文所述 REAP 论文相关代码尚未公开,可关注该关键词后续动态


