Google 发布 TabFM:表格数据也有了自己的基础模型

Google Research 推出 TabFM,一个专门为表格数据设计的零样本基础模型,无需针对具体数据集微调即可直接预测。这填补了表格领域长期缺乏"GPT 时刻"的空白,但要真正撼动 XGBoost 的地位还有硬仗要打。
表格数据终于等来了它的基础模型
7 月 1 日,Google Research 在博客上正式推出了 TabFM(Tabular Foundation Model),一个面向表格数据的零样本基础模型。核心卖点很直接:给它一张你从没见过的表,不用微调、不用调参、不用喂样本,它直接输出预测。
听起来很像视觉和 NLP 领域早就习以为常的事,但放在表格数据上,这事其实憋了很多年。做过表格建模的都知道,这个领域的"日常"依然是 XGBoost、LightGBM、CatBoost 三大件加上一堆特征工程。深度学习在这块的渗透率之低,跟它在 CV/NLP 的统治力形成了鲜明反差。
TabFM 的意义,不在于它今天就能干掉 GBDT,而在于它把"表格基础模型"这条路径从学术论文推向了工业级可用。
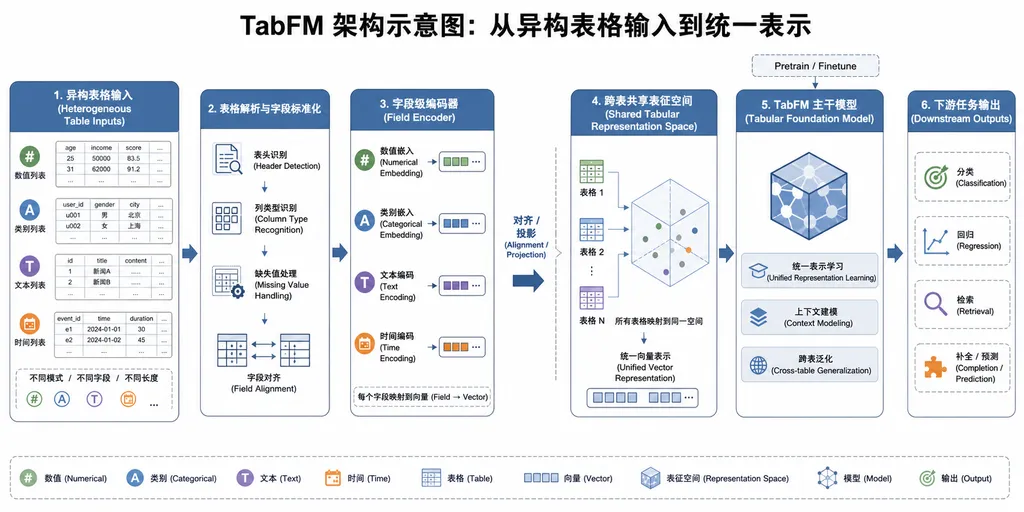
为什么表格数据这么难做基础模型
先说清楚一件事:为什么图像和文本都跑通了预训练大模型这条路,唯独表格数据一直磨磨蹭蹭?
答案是异构性。
图像不管来自哪台相机,本质上都是 RGB 像素的二维排列,相邻像素之间有强烈的空间相关性。文本不管什么语言,都是 token 序列,同一种语言的语料共享一套词表。这两种模态天然具备"统一语义空间"的基础。
表格数据没有这个基础。两张医疗表都可能记录病人信息,但一张的第三列叫"血压",另一张的第三列叫"BMI";一张的"年龄"是整数,另一张写成了"25岁"这种字符串。列的顺序没有语义(换列不改变数据含义),列的数量也不固定,数值型和类别型混杂。你想让一个模型直接吃下所有表,得先解决一个哲学问题:这些表之间到底共享什么。
过去几年,学术界围绕这个问题做了不少尝试。TabPFN 走的是"上下文学习"路线,用一个巨大的合成数据集预训练一个 Transformer,推理时把训练样本直接塞进 context;TabLLM 之类的方法把每一行数据序列化成自然语言喂给 LLM;还有 UniTabE、TP-BERTa 这类基于跨表预训练的思路。每条路径都有各自的天花板——TabPFN 早期版本只能处理不超过一千个样本、一百个特征的小数据集;LLM 序列化的方案 token 消耗巨大,扩展性堪忧。
TabFM 是怎么做的
根据 Google Research 披露的信息,TabFM 的核心思路是用预训练的大语言模型作为骨架,在专门设计的表格学习目标上做二次训练。
这个选择挺有意思。它没有像 TabPFN 那样从零训练一个专用架构,而是复用了 LLM 已经学到的语义理解能力——尤其是对列名、类别值这些天然带语义的字段。当你有一列叫 age 一列叫 income,LLM 是"认识"这两个词的,它知道 age 通常是正整数、income 通常是较大的数值,这种先验能显著加速模型对新表的适应。
然后再叠加两个关键设计:
- 统一的表格 tokenization:把异构的行、列、数值、类别值全部映射到统一的表示空间,让模型可以吞下任意维度、任意列名的表格。
- 零样本预测目标:预训练时就是按照"给一部分行做上下文,预测另一部分行"的方式训的,天然对齐推理时的零样本使用场景。
这套组合拳的效果是:用户拿到一张全新的表,直接扔给 TabFM,指定要预测哪一列,模型立即给出结果。不需要构造训练集/验证集/测试集,不需要跑 Optuna 搜超参,不需要选损失函数。
对比一下传统 pipeline 你就知道这有多省事。一个典型的表格建模流程包括:数据清洗 → 特征工程 → 编码转换 → 模型选择 → 超参搜索 → 交叉验证 → 集成。这里面每一步都是坑。TabFM 试图把前面这些全部压缩成一次前向推理。
零样本能力到底有多强
这是最关键的问题。Google 在博客里给出了跨多个基准的评测结果,TabFM 在零样本设置下已经能与经过完整调参的 GBDT 打得有来有回,在部分任务上甚至反超。
但我得给这个数字加一层解读。表格领域的评测有个老问题:基准不统一,结果对数据集选择极其敏感。McElfresh 等人在 176 个分类数据集上做过大规模评测,结论是 TabPFN 平均表现领先,但在特定领域(比如高维稀疏、极端类别不平衡)依然被树模型吊打。TabFM 现在放出的结果好看,能不能扛住第三方在自选数据集上的验证,还得再看。
南京大学团队上个月刚发布的表格学习综述里提到一个观点我很认同:通用表格模型的价值不完全在于精度超越专用方法,而在于把"跑一个可用模型"的边际成本降到接近零。当你需要在几百张表上快速做初步分析、或者在一个业务系统里为几十个不同的预测任务提供 baseline,TabFM 这种零样本能力的价值就凸显出来了。
换句话说,它不一定要在 Kaggle 冠军解决方案里出现,但可能会成为每个数据科学家笔记本里"第一个跑的模型"。
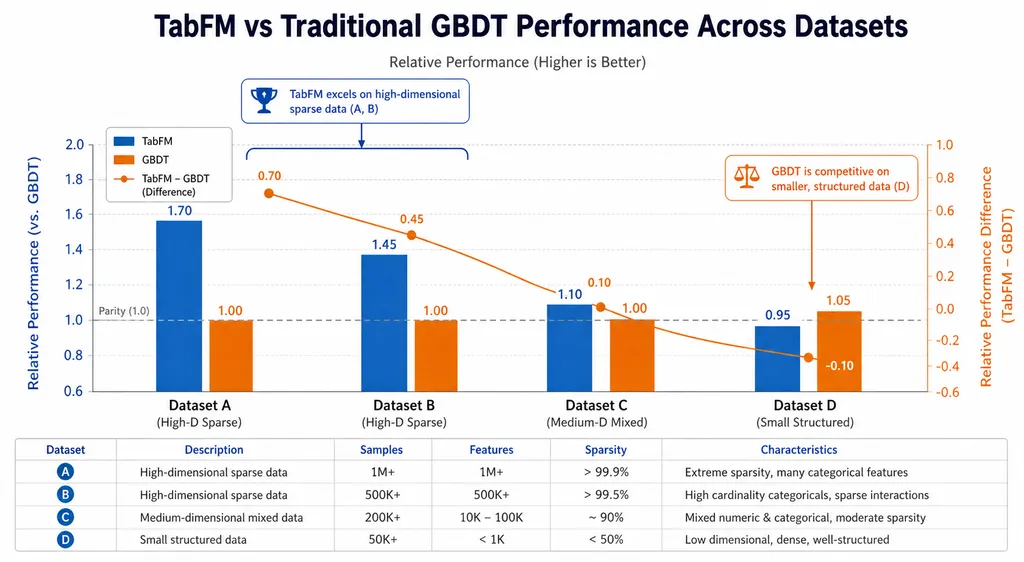
它会替代 XGBoost 吗
短期内不会。中期看,可能会瓜分掉一部分场景。
先说 TabFM 的天然优势:
- 冷启动场景:数据量小、没有足够样本做超参搜索的时候,预训练模型的先验知识就是白捡的
- 多任务/多表环境:一个模型服务几十上百张表,运维成本远低于为每张表都训一个 GBDT
- 富语义表格:列名有明确业务含义的表,LLM 骨架能吃到语义红利
- 快速原型:几秒钟出一个 baseline,产品经理都能用
再说它短期干不过 GBDT 的场景:
- 超大规模数据:几千万行、上百个特征的场景,GBDT 的训练和推理效率依然占优
- 极致精度追求:Kaggle 榜单前排目前还是 GBDT 集成的天下,TabFM 的零样本精度天花板可能顶不到这个层次
- 纯数值、无语义列名:
f1, f2, f3这种匿名特征,LLM 的语义先验发挥不出来 - 推理延迟敏感场景:Transformer 推理成本 vs. GBDT 的一次树遍历,不是一个数量级
我的判断是,TabFM 以及后续的同类模型会先在**"表格数据的长尾场景"**站稳脚跟——那些数据量不大、任务多、精度要求没那么苛刻、但需要快速上线的业务。至于替代 XGBoost 在核心业务里的地位,那还需要几代模型的迭代。
一个更大的信号
往后退一步看,TabFM 的发布释放的是一个更大的信号:"专用模型 → 可迁移模型 → 通用基础模型"这条路径,正在从视觉、语言蔓延到所有数据模态。
时间序列已经有了 Chronos、Moirai 这些基础模型;分子结构、蛋白质、图数据领域都在尝试各自的"foundation model"。表格作为工业界最普遍的数据形态之一,之前一直被认为"太异构、搞不出来",现在这个壁垒也在被凿开。
对开发者来说,值得关注的几个后续方向:
- 模型规模效应:TabFM 只是第一步,随着预训练数据和参数量提升,零样本能力会到哪里
- 推理成本优化:如何在保持精度的前提下把 Transformer 表格推理压到接近 GBDT 的效率
- 多模态融合:真实业务的表格里经常带图像、文本、时间序列,一个能同时吃这些模态的表格基础模型会是下一个大目标
- 开源生态:TabPFN 已经开源,TabFM 目前是 Google 内部模型,能否开源或开放 API 会决定它的社区扩散速度
目前 Google 还没公布 TabFM 的开放使用计划,博客里只说了后续会有更多细节。我们会持续跟进,一旦有 API 或权重开放,会第一时间在 OpenAI Hub 上做适配。
对于日常需要跑各种模型对比的开发者,OpenAI Hub 已经聚合了 GPT、Claude、Gemini、DeepSeek 等主流模型,一个 Key 就能切换调用,国内直连,兼容 OpenAI 格式——等 TabFM 这类新形态基础模型开放接口的时候,接入体验会保持一致。
参考来源
- 知乎专栏 - llm的检索rag-2- 面向表格数据的TabFM - 关于 TabFM 早期技术方案的中文解读,包含 LLM 骨架微调的细节讨论
- 智源社区 - 一文读懂深度表格数据表示学习 - 南京大学团队关于表格表示学习的系统性综述,对通用表格模型的技术路线分类清晰
- GitHub - LAMDA-Tabular/Tabular-Survey - 上述综述的配套代码库,包含表格学习方法的完整评测框架


