GitHub 让 Copilot 学会了「读屏」:通用可访问性智能体浮出水面

GitHub 公开了一项名为通用可访问性智能体的实验,让 Copilot 跳出 IDE,去帮 PR 修无障碍 bug,这背后是 Copilot Agent 走向跨系统应用的一次关键试水。
GitHub 这两天放出了一个不太常规的实验:让 Copilot 不再只盯着代码编辑器,而是跑去做无障碍(accessibility)测试和修复——一个叫做"通用可访问性智能体"(general-purpose accessibility agent)的项目正在内部试点。
听起来像是一个 a11y 工具升级,但放在 Copilot Agent 的演进路线上看,这事的分量不小。它意味着 GitHub 第一次把智能体推出代码仓库之外,让它去理解一个真实运行中的应用——加载页面、模拟键盘焦点、读取屏幕阅读器输出、判断对比度,然后把发现的问题写成可执行的 PR 推回仓库。链路是闭环的,而且跨了好几个系统。
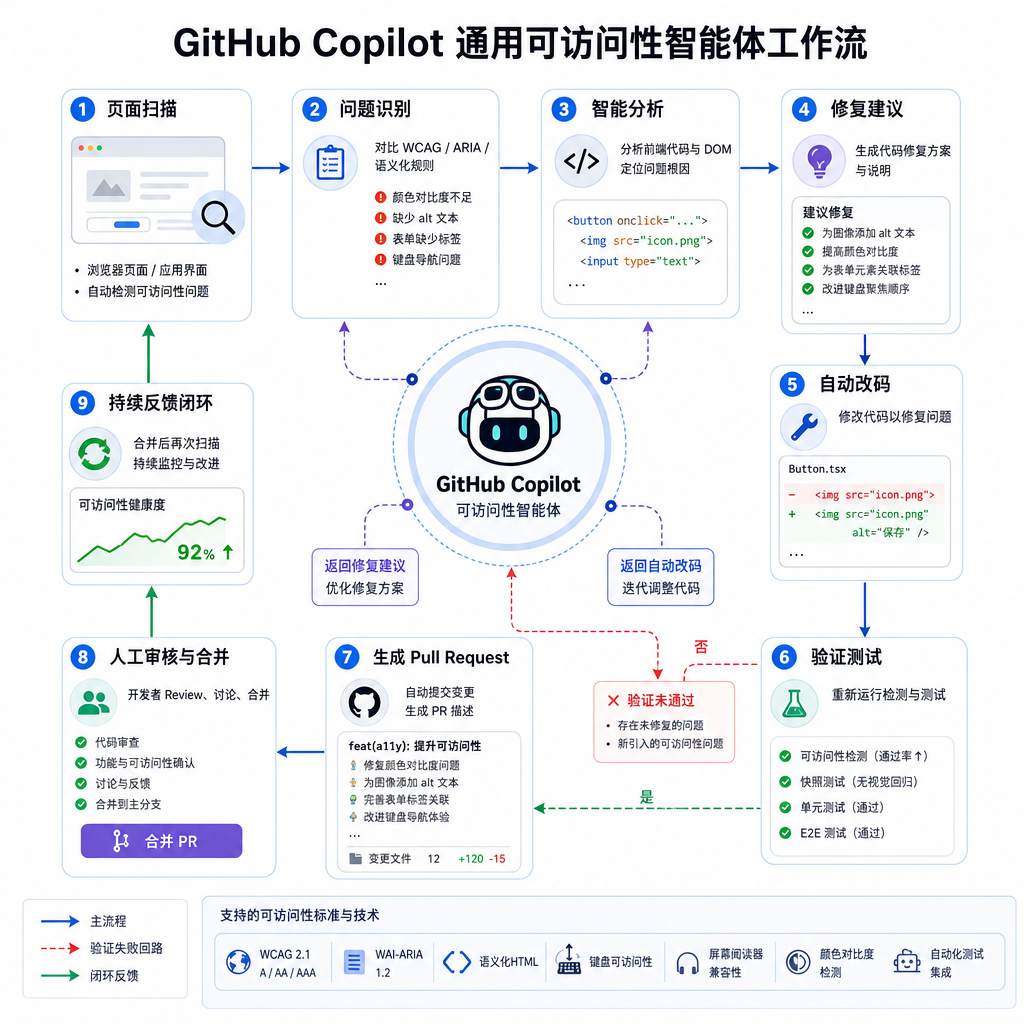
这个智能体在做的事,比 axe-core 复杂得多
做过前端的人对自动化无障碍测试都不陌生,axe-core、Lighthouse、Pa11y 这一票工具用了很多年。它们的特点是规则驱动:扫一遍 DOM,对照 WCAG 条目报问题。优点是稳定可重复,缺点也很明显——只能抓"机器能判定"的一小部分问题。
按 Deque 自己公布的数据,纯静态规则大约只能覆盖 WCAG 失败项的 30%-40%,剩下的得靠人。比如一个按钮的 aria-label 写的是 "button",规则检查会通过,但这标签对屏幕阅读器用户毫无意义;再比如焦点顺序在视觉上看起来正常,但 Tab 键走下来逻辑是乱的,这种问题规则引擎很难判断。
GitHub 这次做的事,是把大模型的语义理解能力塞进这个长期没解的缺口。智能体被设计成一个会用浏览器、会读语义树、会做交互判断的"虚拟测试员"。它的工作流大致是这样:
- 接到一个仓库或一个具体页面后,先把应用跑起来,加载到一个受控浏览器环境里
- 用读屏代理(screen reader proxy)和键盘模拟去走一遍主要交互路径
- 把页面的可访问性树(accessibility tree)、视觉截图、DOM 结构一起喂给模型做判断
- 对疑似问题做分类,区分是"规则可判定"还是"语义性问题"
- 定位到源码里的具体位置,生成修复方案,最后开 PR
这套流程里最值得说的是后两步。定位源码听起来简单,实际上前端工程化层层抽象——一个有问题的 div 可能来自 React 组件、可能由设计系统封装过、可能是 i18n 注入的字符串。智能体得在编译产物和源代码之间反向追踪,这个能力其实是 Copilot 已经在 IDE 里锤炼了一年多的活儿,现在被搬到了运行时场景。
为什么是"通用",关键在这两个字
GitHub 在博客里特意强调 general-purpose,这个定语不是修辞。
业界过去几年也出过不少 AI 驱动的无障碍工具,但大多数是绑定特定框架或特定云平台的——比如只支持 React、只跑在 AWS、只能扫 SPA。GitHub 这次的智能体试图做的是不挑技术栈:传给它一个 URL 或者一个能跑起来的项目,它就能开工。这背后涉及的工程量包括沙箱环境编排、不同前端框架的 source map 解析、以及对老旧 Web 技术(jQuery、服务端模板渲染)的兼容。
更值得关注的是它的延展性。GitHub 团队在文章里透露,这套架构的核心组件——浏览器自动化层、语义树解析层、源码定位层、PR 生成层——是模块化的。换句话说,今天它做无障碍审查,明天换一组判断逻辑就能去做性能审计、SEO 审计、安全扫描。这跟 Copilot 早期只能补全代码、后来能改 PR、再后来变成 Agent Mode 自己跑命令的演进节奏完全一致:先把单点能力做扎实,再抽象成平台。
这也是为什么我倾向于把这次发布看作一次方法论展示,而不仅仅是一个新功能。GitHub 在告诉外界:Copilot 已经具备让智能体走出 IDE、跨系统协作的能力了。
实战中暴露的问题,团队没有藏着
比较难得的是,这篇博客没有按通常的产品发布稿那种打法吹效果,而是花了相当篇幅讲踩过的坑。几个我觉得对开发者有参考价值的点:
幻觉问题在视觉判断里被放大。 模型有时候会"看到"页面上根本不存在的元素,或者把一个装饰性图标判定为关键操作按钮。团队的做法是引入交叉验证——同一个判断必须从可访问性树和视觉截图两条路径都得到支持,才会被记入问题列表。这个思路其实和多模态模型评估里的 self-consistency 一脉相承,但在生产场景里第一次被这么严肃地工程化。
修复建议的过度自信。 模型很乐意给出"加个 aria-label 就好了"这种表面修复,但很多时候问题的根因在组件设计。团队加了一道审核:智能体生成的 PR 必须标注修复的置信度等级,低置信度的修复会被标为"建议人工审查"而不是直接 merge ready。
性能与覆盖率的取舍。 让一个智能体把整站爬一遍既慢又贵,团队最后选择的策略是按用户旅程(user journey)切片,每次只测一条关键路径。这意味着开发者在接入时要给智能体一些上下文——告诉它哪些是核心流程。
长尾交互覆盖不到。 模态框、抽屉、复杂表单这种带状态的组件,自动化探索还是会漏。团队目前的解法是开放扩展接口,允许开发者写自定义的探索脚本喂给智能体作为种子。
把它放回 Copilot Agent 的整张棋盘上
要理解这次实验的位置,得把 GitHub 过去 18 个月的 Copilot 路线串起来看。
从 GitHub Copilot Workspace 开始,GitHub 就在试图回答一个问题:当一个 AI 能完整理解"任务-代码-验证"这条链时,它的工作单位还应该是"代码片段"吗?后来的 Copilot Agent Mode 给出了第一阶段的答案——智能体可以自己读代码、改文件、跑命令、看测试结果,在 IDE 里形成闭环。再后来的 Cloud Agent 把这套东西搬到云端,让任务可以异步执行、可以通过 REST API 触发。
通用可访问性智能体是这条线的下一站:智能体不再只在代码层面工作,它要去操作一个真实的运行时系统,再把发现反向写回代码。这一步打通后,下一批可能出现的就是测试智能体、安全审计智能体、文档维护智能体,每一个都有同样的"运行-观察-修复"骨架。
Microsoft Reactor 之前那场 Agent Mode 的活动里也在反复强调一点:智能体的价值不在写代码本身,而在闭环。这次的可访问性实验把闭环延伸到了浏览器渲染出来的页面,是一次实质性扩张。
对开发者意味着什么
短期内,这个智能体还在受限试点,没有公开 API。GitHub 没给具体上线时间表,只说在收集早期反馈。但有几件事值得提前准备:
- 如果你的项目还在用纯静态扫描(axe-core、Lighthouse CI)作为唯一的 a11y 防线,可以开始评估补一层语义性检查的方案,等通用智能体开放再无缝接入
- 设计系统层面预留 source map 和组件元数据,能让未来的智能体修复更精准——这不只是为这一个工具,对任何运行时反向定位类工具都有用
- 关键用户旅程的文档化值得做。智能体的探索效率取决于种子上下文,越是结构清晰的项目,越容易被这类工具吃透
这件事还有一层信号:当 Anthropic、OpenAI、Google 都在往"通用计算机使用智能体"方向卷的时候,GitHub 选择了一条更克制的路线——不做万能的桌面 Agent,而是把 Copilot 的能力按场景切片下放,每一片都解决一个具体的工程问题。从 Code、PR、Workspace、Cloud Agent 一路下来,可访问性是又一个新切片。
顺带说一句,对想测试不同模型在这类"看页面+改代码"任务里表现的开发者,OpenAI Hub 已经把 GPT、Claude、Gemini、DeepSeek 这些主流模型都接到了同一个 OpenAI 兼容接口下,国内直连,调试多模态视觉理解和代码生成的组合任务时省去了切来切去的麻烦。
通用可访问性智能体本身能不能成为爆款产品并不是最重要的事。重要的是 GitHub 用这个实验证明了一件事:Copilot 这套智能体框架,已经可以走出代码编辑器,去操作真实世界的应用了。这扇门一旦推开,后面会涌出来的东西远不止无障碍修复一个。
参考来源
- Building a general-purpose accessibility agent—and what we learned in the process — GitHub 官方博客,通用可访问性智能体实验的完整介绍与团队复盘
- GitHub Copilot 云代理文档 — Copilot Cloud Agent 的官方使用文档,包含 REST API 编程触发任务的方式
- GitHub Copilot 智能体的概念 — Copilot 智能体体系的概念性说明,涵盖 Cloud Agent、CLI、第三方代理等组件
- 技术速递:GitHub Copilot 和 AI Agent 如何拯救传统系统 — 知乎专栏关于 Copilot Agent 在遗留系统现代化中的实战经验
- 使用 GitHub Copilot SDK 创建多智能体系统讨论 — Reddit 上关于基于 Copilot SDK 构建多智能体系统的开发者讨论


