Om AI 甩出 VLX:把多模态塞进摄像头的大脑

6 月底连发三天,Om AI 联汇把 VLX 系列端侧流式多模态模型推上 GitHub。三款模型 0.6B 到 10B,主打摄像头、机器人、无人机这种"视频一直在流"的场景,单路延迟压到 0.06 秒。
6 月 27 日到 29 日,Om AI 联汇科技连续三天在 GitHub 上放模型,把 VLX 端侧流式多模态系列一次性铺完:VLX-Flow、VLX-Seek、VLX-Go 三款分工协作,覆盖 0.6B 到 10B 参数规格。这套东西自称"全球首个面向物理世界的端侧流式多模态模型",宣传口径挺大,但拆开看,它确实回答了一个过去一年没什么人正面回应的问题——多模态模型跑在真设备上,到底应该长什么样。
过去两年,视频理解模型主要在解一道题:给你一段视频,请回答问题。抽帧、编码、推理、输出,一次性搞定。这个范式在短视频总结、内容检索里没毛病,但摄像头不会等你上传完再看,机器人也不会站在原地等你提问。物理世界的输入是连续流,不是文件。
Om AI 这次做的事,本质上是把视频理解从"接口"改造成"常驻进程"。
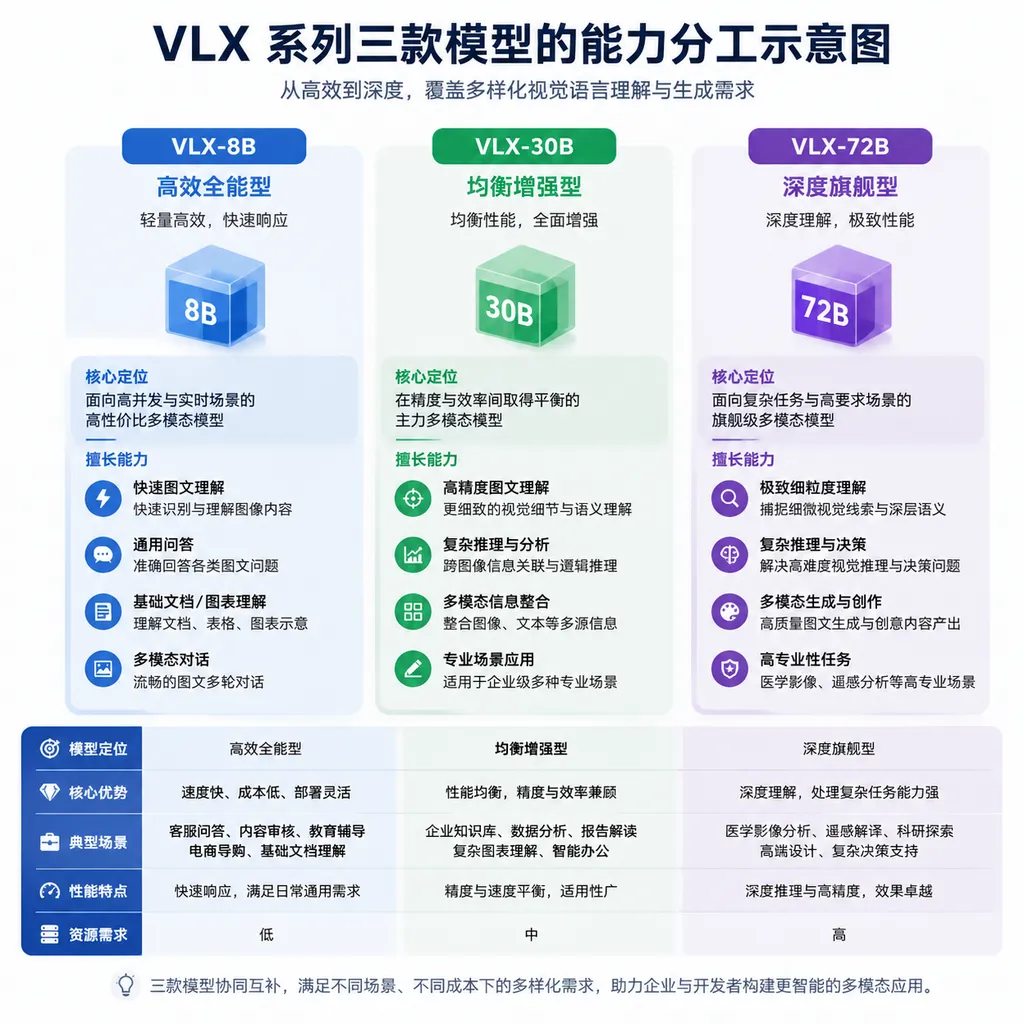
三款模型是怎么分工的
先把结构说清楚。VLX 不是一个大而全的模型,而是三个各司其职的组件,对应"感知—定位—行动"的完整闭环:
- VLX-Flow:负责持续感知与文本交互。视频以连续小片段的形式进来,模型通过增量编码维护一个可复用的缓存状态。新画面来了不用回头重算历史,用户提问的时候,模型已经"看了一会儿",能直接答。
- VLX-Seek:负责精准定位。这里有个挺聪明的设计——它没让模型硬输出坐标数字(LLM 生成坐标一直是个玄学问题),而是把坐标生成改成了区域检索:从若干候选区域里挑一个。这一步把开放式的空间推理压缩成了封闭集合上的选择题,靠谱度直接上一个台阶。
- VLX-Go:负责行动。它不吐建议文本,直接输出机器人能吃的短时航点和运动轨迹。跟随、避障、导航这些活儿,从"视觉理解"到"电机指令"中间那一层它自己接了。
三个模型串起来,就是"边看、边找、边动"。这个链路和过去 VLA(Vision-Language-Action)模型的思路是接近的,但 Om AI 把它拆得更细,也更贴合端侧算力现实。
流式多模态到底和传统方案差在哪
这是文章里最值得展开的一段。
传统视频理解一般走两条路:全帧输入——切成上百帧一次喂进去,信息量大但算力和延迟顶不住长视频;固定采样——每隔几秒抽一帧,成本低但动作细节容易漏。摄像头场景下这俩都不太行,因为关键事件可能就发生在采样间隙。
VLX-Flow 的思路是把视频切成连续的小片段(比如每 2 秒一段),按时间顺序进模型。视觉编码器把新片段编码成语言模型能用的表征,语言模型这边维护一个KV 缓存 + 递推状态,新片段进来只做增量更新,不重算历史。
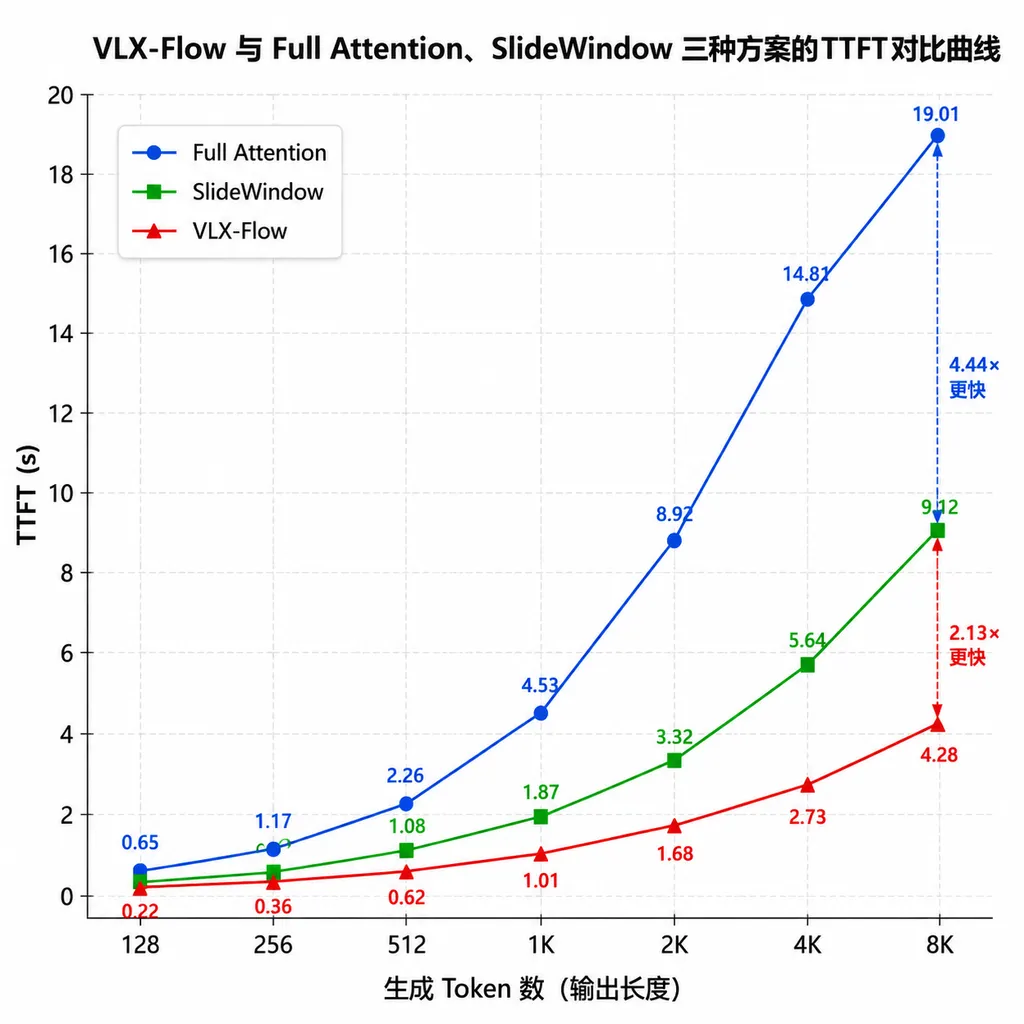
它的语言模型里塞了 Linear Attention 模块,这是关键一步。标准自注意力的 KV Cache 会随序列变长线性膨胀,跑长视频 OOM 只是时间问题。Linear Attention 通过可递推状态把历史压成固定大小的状态量,视频流一直进,显存不会一直涨。TTFT(首 token 生成延迟)这个数字更能说明问题:
- Full Attention:输入图像数量增加,TTFT 一路上涨
- SlideWindow:窗口一满就重置,TTFT 呈锯齿状波动
- VLX-Flow:靠双层记忆压缩历史状态,TTFT 在长序列下依然稳定
官方给的单路延迟数字是 0.06 秒。这个数在端侧上下文里很有意义——它意味着模型能跟上正常帧率的视频流,不用降采样、不用批处理,摄像头怎么给它就怎么消化。
双层记忆:让文本历史和视觉状态别打架
VLX-Flow 里另一个有意思的设计是双层记忆机制。
第一层是视觉缓存,保留最近时间窗口的画面细节,动作、位置、主体状态、短时变化都在这里。第二层是文本承接层,负责连续描述、用户提问、模型回答这些长程语义。多轮交互的时候,文本承接层会在合并、裁剪、回放过程中和视觉缓存同步,避免"文本说桌上有杯子,模型内部记忆里杯子已经被拿走了"这种错位。
这个问题在实际用起来时特别烦人。人类多轮对话中一个常见的失败模式就是:模型记得自己上一轮说过什么,但完全忘了视觉输入这时候已经变了。Om AI 用同步机制把这两条记忆链绑在一起,工程上是老实的做法。
为什么不是"云端模型压小"
公司自己反复强调一句话:VLX 不是把云端模型压到端上,而是从架构层为端侧重新设计。这句话乍看像营销,但对着技术细节看,确实有区别。
把云端多模态模型(比如 GPT-4V、Qwen-VL 那类)量化成 INT4、砍参数量、蒸馏到 1B 以下,跑是能跑,但架构本身还是为"离线一次性推理"设计的。KV Cache 该炸还是炸,抽帧策略该丢帧还是丢帧,只是数值精度低了、算子省了。
VLX 的做法是从数据构造那一层就换了范式——训练时就用"观察 + 延迟提问"的方式喂数据。视频先分段流进模型,模型生成 Stream Memory,几十秒甚至几分钟之后再抛问题,模型必须靠已经压好的记忆状态回答,不能回头翻视频。这套训练目标决定了模型的内部状态是为持续运行优化的,而不是为一次性响应优化的。
这也是为什么参数规格从 0.6B 起步。端侧场景对算力和显存的硬约束摆在那里,1B 以下的模型能在无人机、机器人主控、AI PC 上直接跑,10B 的版本则给车载和边缘工作站留了余地。
我的判断:这一步踩在了对的方向上
多模态模型这两年在 benchmark 上刷分刷得挺热闹,但落到真实设备上,故事一直有点尴尬。摄像头厂商想接大模型,接完发现云端延迟撑不起实时告警;机器人公司想搞 VLA,发现端上跑不起来只能上云,上云又出不了工厂。行业里其实一直缺一个"为持续视频流原生设计"的模型架构。
VLX 未必是最终答案,但它把问题拆得很清楚:连续输入、动态环境、资源受限,这三个约束不解决,物理 AI 就一直卡在 demo 阶段。Om AI 把感知、定位、执行拆成三个模型协同,比把所有能力硬塞进一个大模型要务实——每个模型只做自己那件事,训练目标干净,端侧部署也好切分。
当然要看的东西还有几件:
- 实际部署效果:0.06 秒是官方数字,跑在什么硬件、什么分辨率、多长的历史上下文,需要开发者自己压测
- VLX-Seek 的区域检索:思路好,但候选区域怎么生成、精度上限在哪,这一块的工程细节决定它能不能替代传统检测头
- VLX-Go 的泛化性:直接输出航点意味着必须和具体机器人本体强耦合,跨形态迁移会不会掉链子
- 生态适配:ROS、Isaac、各种嵌入式推理框架的兼容度
Om AI 这家公司背景不算轻——CEO 赵天成拿过吴文俊人工智能科技进步奖,公司也在浙江具身智能圈里挂了号,AWE 2026 上展过"通用智能终端大脑"的概念。这次连发三天、代码同步 GitHub,姿态是想把 VLX 做成开发者能用的东西,而不是发布会上放几张 PPT 就收工。
云端和端侧的分工
最后聊一句范式。
VLX 走的是端侧路线,主打设备本地跑;而云端多模态模型(GPT-5、Claude、Gemini 那一批)继续在做更复杂的推理、更长的上下文、更强的通用能力。这两条线其实不冲突——机器人在本地用 VLX-Flow 持续感知、VLX-Go 处理运动,遇到需要复杂决策的问题时再回云端调大模型,是很自然的分工。做云端 API 聚合的服务(比如 OpenAI Hub 这类一个 Key 调 GPT/Claude/Gemini/DeepSeek 的平台)解决的是"复杂推理走云"的部分,VLX 这样的端侧模型解决的是"实时感知在本地"的部分。物理世界的 AI 系统未来大概率是这两层叠起来的。
从"看图答题"到"持续感知",多模态模型的形态在变。VLX 把这个变化摆到了台面上——摄像头不会每 5 秒才看一眼世界,机器人也不能只在被提问时才睁眼。这套架构值不值得押注,等接下来几个月实测数据出来再看,但方向是对的。
参考来源
- Om AI 联汇 GitHub 组织页 - VLX 系列模型代码与文档的官方发布地址
- VLX 相关模型仓库 - Hugging Face 上的模型权重与配置文件


